 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrchard: An Open-Source Agentic Modeling Framework
May 14, 2026Agentic modeling aims to transform LLMs into autonomous agents capable of solving complex tasks through planning, reasoning, tool use, and multi-turn interaction with environments. Despite major investment, open research remains constrained by infrastructure and training gaps. Many high-performing systems rely on proprietary codebases, models, or services, while most open-source frameworks focus on orchestration and evaluation rather than scalable agent training. We present Orchard, an open-source framework for scalable agentic modeling. At its core is Orchard Env, a lightweight environment service providing reusable primitives for sandbox lifecycle management across task domains, agent harnesses, and pipeline stages. On top of Orchard Env, we build three agentic modeling recipes. Orchard-SWE targets coding agents. We distill 107K trajectories from MiniMax-M2.5 and Qwen3.5-397B, introduce credit-assignment SFT to learn from productive segments of unresolved trajectories, and apply Balanced Adaptive Rollout for RL. Starting from Qwen3-30B-A3B-Thinking, Orchard-SWE achieves 64.3% on SWE-bench Verified after SFT and 67.5% after SFT+RL, setting a new state of the art among open-source models of comparable size. Orchard-GUI trains a 4B vision-language computer-use agent using only 0.4K distilled trajectories and 2.2K open-ended tasks. It achieves 74.1%, 67.0%, and 64.0% success rates on WebVoyager, Online-Mind2Web, and DeepShop, respectively, making it the strongest open-source model while remaining competitive with proprietary systems. Orchard-Claw targets personal assistant agents. Trained with only 0.2K synthetic tasks, it achieves 59.6% pass@3 on Claw-Eval and 73.9% when paired with a stronger ZeroClaw harness. Collectively, these results show that a lightweight, open, harness-agnostic environment layer enables reusable agentic data, training recipes, and evaluations across domains.
Diagnosing Training Inference Mismatch in LLM Reinforcement Learning
May 14, 2026Modern LLM RL systems separate rollout generation from policy optimization. These two stages are expected to produce token probabilities that match exactly. However, implementation differences can make them assign different values to the same sequence under the same model weights, inducing Training-Inference Mismatch (TIM). TIM is difficult to inspect because it is entangled with off-policy drift and common stabilization mechanisms. In this work, we isolate TIM in a zero-mismatch diagnostic setting (VeXact), and show that small token-level numerical disagreements can independently cause training collapse. We further show that TIM changes the effective optimization problem, and identify a set of remedies that could mitigate TIM. Our results suggest that TIM is not benign numerical noise, but a systems-level perturbation that should be treated as a first-order factor in analyzing LLM RL stability.
ConFit v3: Improving Resume-Job Matching with LLM-based Re-Ranking
May 10, 2026A reliable resume-job matching system helps a company find suitable candidates from a pool of resumes and helps a job seeker find relevant jobs from a list of job posts. While recent advances in embedding-based methods such as ConFit and ConFit v2 can efficiently retrieve candidates at scale, the lack of controllability and explainability limits their real-world adaptations. LLM-based re-rankers can address these limitations through reasoning, but existing training recipes are developed on short-document benchmarks and do not account for noise in real-world recruiting data. In this work, we first conduct a systematic analysis over the LLM re-ranker training pipeline for person-job fit, covering inference algorithm design, RL algorithm selection, data processing, and SFT distillation. We find that using multi-pass re-ranking, training with listwise RL objectives, removing noisy samples, and distilling from a stronger LLM before RL significantly improves re-ranking performance. We then aggregate these findings to train ConFit v3 with Qwen3-8B and Qwen3-32B on real-world person-job fit datasets, and find significant improvements over existing best person-job fit systems as well as strong LLMs such as GPT-5 and Claude Opus-4.5. We hope our findings provide useful insights for future research on adapting LLM-based re-rankers to person-job fit systems.
DAG-STL: A Hierarchical Framework for Zero-Shot Trajectory Planning under Signal Temporal Logic Specifications
Apr 20, 2026Signal Temporal Logic (STL) is a powerful language for specifying temporally structured robotic tasks. Planning executable trajectories under STL constraints remains difficult when system dynamics and environment structure are not analytically available. Existing methods typically either assume explicit models or learn task-specific behaviors, limiting zero-shot generalization to unseen STL tasks. In this work, we study offline STL planning under unknown dynamics using only task-agnostic trajectory data. Our central design philosophy is to separate logical reasoning from trajectory realization. We instantiate this idea in DAG-STL, a hierarchical framework that converts long-horizon STL planning into three stages. It first decomposes an STL formula into reachability and invariance progress conditions linked by shared timing constraints. It then allocates timed waypoints using learned reachability-time estimates. Finally, it synthesizes trajectories between these waypoints with a diffusion-based generator. This decomposition--allocation--generation pipeline reduces global planning to shorter, better-supported subproblems. To bridge the gap between planning-level correctness and execution-level feasibility, we further introduce a rollout-free dynamic consistency metric, an anytime refinement search procedure for improving multiple allocation hypotheses under finite budgets, and a hierarchical online replanning mechanism for execution-time recovery. Experiments in Maze2D, OGBench AntMaze, and the Cube domain show that DAG-STL substantially outperforms direct robustness-guided diffusion on complex long-horizon STL tasks and generalizes across navigation and manipulation settings. In a custom environment with an optimization-based reference, DAG-STL recovers most model-solvable tasks while retaining a clear computational advantage over direct optimization based on the explicit system model.
Regularized Entropy Information Adaptation with Temporal-Awareness Networks for Simultaneous Speech Translation
Apr 10, 2026Simultaneous Speech Translation (SimulST) requires balancing high translation quality with low latency. Recent work introduced REINA, a method that trains a Read/Write policy based on estimating the information gain of reading more audio. However, we find that information-based policies often lack temporal context, leading the policy to bias itself toward reading most of the audio before starting to write. We improve REINA using two distinct strategies: a supervised alignment network (REINA-SAN) and a timestep-augmented network (REINA-TAN). Our results demonstrate that while both methods significantly outperform the baseline and resolve stability issues, REINA-TAN provides a slightly superior Pareto frontier for streaming efficiency, whereas REINA-SAN offers more robustness against 'read loops'. Applied to Whisper, both methods improve the pareto frontier of streaming efficiency as measured by Normalized Streaming Efficiency (NoSE) scores up to 7.1% over existing competitive baselines.
VideoWorld 2: Learning Transferable Knowledge from Real-world Videos
Feb 10, 2026Learning transferable knowledge from unlabeled video data and applying it in new environments is a fundamental capability of intelligent agents. This work presents VideoWorld 2, which extends VideoWorld and offers the first investigation into learning transferable knowledge directly from raw real-world videos. At its core, VideoWorld 2 introduces a dynamic-enhanced Latent Dynamics Model (dLDM) that decouples action dynamics from visual appearance: a pretrained video diffusion model handles visual appearance modeling, enabling the dLDM to learn latent codes that focus on compact and meaningful task-related dynamics. These latent codes are then modeled autoregressively to learn task policies and support long-horizon reasoning. We evaluate VideoWorld 2 on challenging real-world handcraft making tasks, where prior video generation and latent-dynamics models struggle to operate reliably. Remarkably, VideoWorld 2 achieves up to 70% improvement in task success rate and produces coherent long execution videos. In robotics, we show that VideoWorld 2 can acquire effective manipulation knowledge from the Open-X dataset, which substantially improves task performance on CALVIN. This study reveals the potential of learning transferable world knowledge directly from raw videos, with all code, data, and models to be open-sourced for further research.
Reinforcement World Model Learning for LLM-based Agents
Feb 05, 2026Large language models (LLMs) have achieved strong performance in language-centric tasks. However, in agentic settings, LLMs often struggle to anticipate action consequences and adapt to environment dynamics, highlighting the need for world-modeling capabilities in LLM-based agents. We propose Reinforcement World Model Learning (RWML), a self-supervised method that learns action-conditioned world models for LLM-based agents on textual states using sim-to-real gap rewards. Our method aligns simulated next states produced by the model with realized next states observed from the environment, encouraging consistency between internal world simulations and actual environment dynamics in a pre-trained embedding space. Unlike next-state token prediction, which prioritizes token-level fidelity (i.e., reproducing exact wording) over semantic equivalence and can lead to model collapse, our method provides a more robust training signal and is empirically less susceptible to reward hacking than LLM-as-a-judge. We evaluate our method on ALFWorld and $τ^2$ Bench and observe significant gains over the base model, despite being entirely self-supervised. When combined with task-success rewards, our method outperforms direct task-success reward RL by 6.9 and 5.7 points on ALFWorld and $τ^2$ Bench respectively, while matching the performance of expert-data training.
DGSAN: Dual-Graph Spatiotemporal Attention Network for Pulmonary Nodule Malignancy Prediction
Dec 24, 2025Lung cancer continues to be the leading cause of cancer-related deaths globally. Early detection and diagnosis of pulmonary nodules are essential for improving patient survival rates. Although previous research has integrated multimodal and multi-temporal information, outperforming single modality and single time point, the fusion methods are limited to inefficient vector concatenation and simple mutual attention, highlighting the need for more effective multimodal information fusion. To address these challenges, we introduce a Dual-Graph Spatiotemporal Attention Network, which leverages temporal variations and multimodal data to enhance the accuracy of predictions. Our methodology involves developing a Global-Local Feature Encoder to better capture the local, global, and fused characteristics of pulmonary nodules. Additionally, a Dual-Graph Construction method organizes multimodal features into inter-modal and intra-modal graphs. Furthermore, a Hierarchical Cross-Modal Graph Fusion Module is introduced to refine feature integration. We also compiled a novel multimodal dataset named the NLST-cmst dataset as a comprehensive source of support for related research. Our extensive experiments, conducted on both the NLST-cmst and curated CSTL-derived datasets, demonstrate that our DGSAN significantly outperforms state-of-the-art methods in classifying pulmonary nodules with exceptional computational efficiency.
ReasonCD: A Multimodal Reasoning Large Model for Implicit Change-of-Interest Semantic Mining
Dec 22, 2025
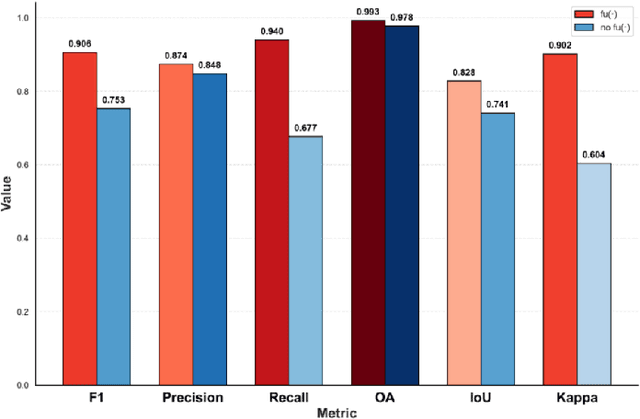
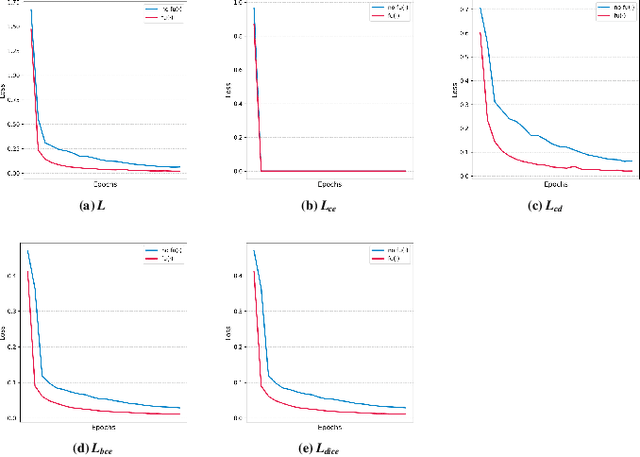
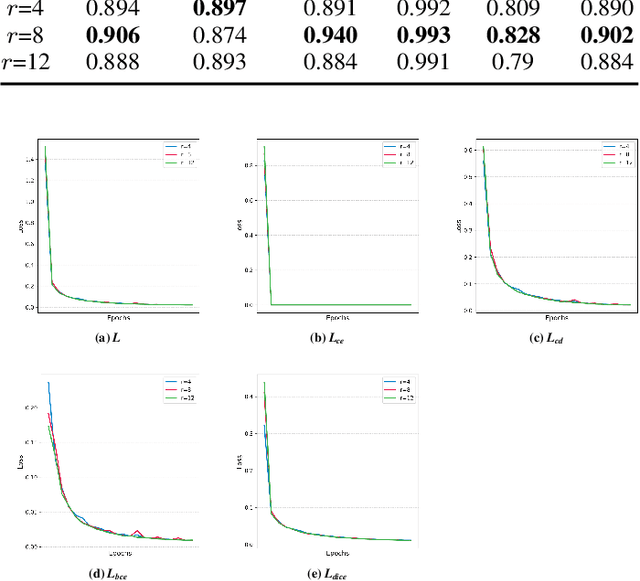
Remote sensing image change detection is one of the fundamental tasks in remote sensing intelligent interpretation. Its core objective is to identify changes within change regions of interest (CRoI). Current multimodal large models encode rich human semantic knowledge, which is utilized for guidance in tasks such as remote sensing change detection. However, existing methods that use semantic guidance for detecting users' CRoI overly rely on explicit textual descriptions of CRoI, leading to the problem of near-complete performance failure when presented with implicit CRoI textual descriptions. This paper proposes a multimodal reasoning change detection model named ReasonCD, capable of mining users' implicit task intent. The model leverages the powerful reasoning capabilities of pre-trained large language models to mine users' implicit task intents and subsequently obtains different change detection results based on these intents. Experiments on public datasets demonstrate that the model achieves excellent change detection performance, with an F1 score of 92.1\% on the BCDD dataset. Furthermore, to validate its superior reasoning functionality, this paper annotates a subset of reasoning data based on the SECOND dataset. Experimental results show that the model not only excels at basic reasoning-based change detection tasks but can also explain the reasoning process to aid human decision-making.
Dyna-Mind: Learning to Simulate from Experience for Better AI Agents
Oct 10, 2025



Reasoning models have recently shown remarkable progress in domains such as math and coding. However, their expert-level abilities in math and coding contrast sharply with their performance in long-horizon, interactive tasks such as web navigation and computer/phone-use. Inspired by literature on human cognition, we argue that current AI agents need ''vicarious trial and error'' - the capacity to mentally simulate alternative futures before acting - in order to enhance their understanding and performance in complex interactive environments. We introduce Dyna-Mind, a two-stage training framework that explicitly teaches (V)LM agents to integrate such simulation into their reasoning. In stage 1, we introduce Reasoning with Simulations (ReSim), which trains the agent to generate structured reasoning traces from expanded search trees built from real experience gathered through environment interactions. ReSim thus grounds the agent's reasoning in faithful world dynamics and equips it with the ability to anticipate future states in its reasoning. In stage 2, we propose Dyna-GRPO, an online reinforcement learning method to further strengthen the agent's simulation and decision-making ability by using both outcome rewards and intermediate states as feedback from real rollouts. Experiments on two synthetic benchmarks (Sokoban and ALFWorld) and one realistic benchmark (AndroidWorld) demonstrate that (1) ReSim effectively infuses simulation ability into AI agents, and (2) Dyna-GRPO leverages outcome and interaction-level signals to learn better policies for long-horizon, planning-intensive tasks. Together, these results highlight the central role of simulation in enabling AI agents to reason, plan, and act more effectively in the ever more challenging environments.