 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyna-Mind: Learning to Simulate from Experience for Better AI Agents
Oct 10, 2025



Reasoning models have recently shown remarkable progress in domains such as math and coding. However, their expert-level abilities in math and coding contrast sharply with their performance in long-horizon, interactive tasks such as web navigation and computer/phone-use. Inspired by literature on human cognition, we argue that current AI agents need ''vicarious trial and error'' - the capacity to mentally simulate alternative futures before acting - in order to enhance their understanding and performance in complex interactive environments. We introduce Dyna-Mind, a two-stage training framework that explicitly teaches (V)LM agents to integrate such simulation into their reasoning. In stage 1, we introduce Reasoning with Simulations (ReSim), which trains the agent to generate structured reasoning traces from expanded search trees built from real experience gathered through environment interactions. ReSim thus grounds the agent's reasoning in faithful world dynamics and equips it with the ability to anticipate future states in its reasoning. In stage 2, we propose Dyna-GRPO, an online reinforcement learning method to further strengthen the agent's simulation and decision-making ability by using both outcome rewards and intermediate states as feedback from real rollouts. Experiments on two synthetic benchmarks (Sokoban and ALFWorld) and one realistic benchmark (AndroidWorld) demonstrate that (1) ReSim effectively infuses simulation ability into AI agents, and (2) Dyna-GRPO leverages outcome and interaction-level signals to learn better policies for long-horizon, planning-intensive tasks. Together, these results highlight the central role of simulation in enabling AI agents to reason, plan, and act more effectively in the ever more challenging environments.
Iterative Self-Tuning LLMs for Enhanced Jailbreaking Capabilities
Oct 24, 2024



Recent research has shown that Large Language Models (LLMs) are vulnerable to automated jailbreak attacks, where adversarial suffixes crafted by algorithms appended to harmful queries bypass safety alignment and trigger unintended responses. Current methods for generating these suffixes are computationally expensive and have low Attack Success Rates (ASR), especially against well-aligned models like Llama2 and Llama3. To overcome these limitations, we introduce ADV-LLM, an iterative self-tuning process that crafts adversarial LLMs with enhanced jailbreak ability. Our framework significantly reduces the computational cost of generating adversarial suffixes while achieving nearly 100\% ASR on various open-source LLMs. Moreover, it exhibits strong attack transferability to closed-source models, achieving 99% ASR on GPT-3.5 and 49% ASR on GPT-4, despite being optimized solely on Llama3. Beyond improving jailbreak ability, ADV-LLM provides valuable insights for future safety alignment research through its ability to generate large datasets for studying LLM safety. Our code is available at: https://github.com/SunChungEn/ADV-LLM
Teaching AI Agents to Search with Reflective-MCTS and Exploratory Learning
Oct 15, 2024
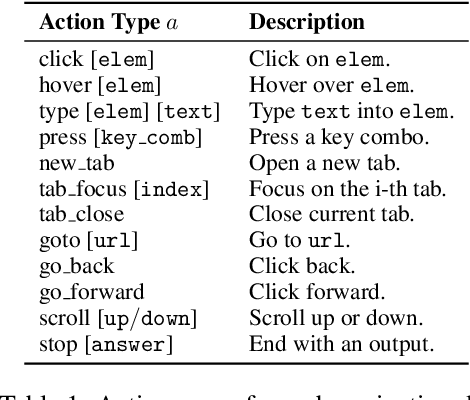
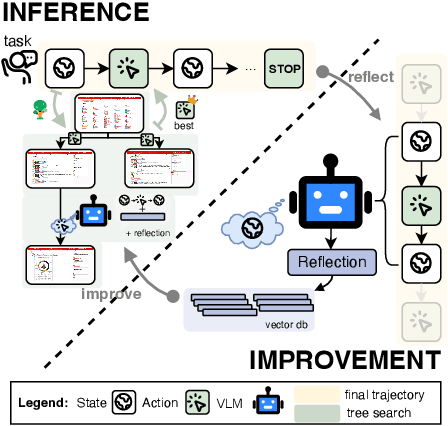
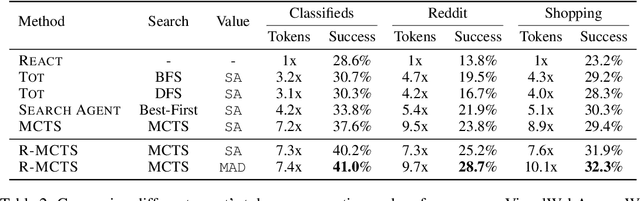
Autonomous agents have demonstrated significant potential in automating complex multistep decision-making tasks. However, even state-of-the-art vision-language models (VLMs), such as GPT-4o, still fall short of human-level performance, particularly in intricate web environments and long-horizon planning tasks. To address these limitations, we present Reflective Monte Carlo Tree Search (R-MCTS) and Exploratory Learning to build o1-like models for agentic applications. We first introduce R-MCTS, a novel test-time algorithm designed to enhance the ability of AI agents to explore decision space on the fly. R-MCTS extends traditional MCTS by 1) incorporating contrastive reflection, allowing agents to learn from past interactions and dynamically improve their search efficiency; and 2) using multi-agent debate to provide reliable state evaluation. Next, we introduce Exploratory Learning, a novel learning strategy to teach agents to search at inference time without relying on any external search algorithms. On the challenging VisualWebArena benchmark, our GPT-4o-based R-MCTS agent achieves a 6% to 30% relative improvement across various tasks compared to the previous state-of-the-art. Additionally, we show that the experience gained from test-time search can be effectively transferred back to GPT-4o via fine-tuning. After Exploratory Learning, GPT-4o 1) demonstrates the ability to explore the environment, evaluate a state, and backtrack to viable ones when it detects that the current state cannot lead to success, and 2) matches 87% of R-MCTS's performance while using significantly less compute. Notably, our work demonstrates the compute scaling properties in both training - data collection with R-MCTS - and testing time. These results suggest a promising research direction to enhance VLMs' reasoning and planning capabilities for agentic applications via test-time search and self-learning.
Improving Autonomous AI Agents with Reflective Tree Search and Self-Learning
Oct 02, 2024Autonomous agents have demonstrated significant potential in automating complex multistep decision-making tasks. However, even state-of-the-art vision-language models (VLMs), such as GPT-4o, still fall short of human-level performance, particularly in intricate web environments and long-horizon planning tasks. To address these limitations, we introduce Reflective Monte Carlo Tree Search (R-MCTS), a novel test-time algorithm designed to enhance the ability of AI agents, e.g., powered by GPT-4o, to explore decision space on the fly. R-MCTS extends traditional MCTS by 1) incorporating contrastive reflection, allowing agents to learn from past interactions and dynamically improve their search efficiency; and 2) using multi-agent debate to provide reliable state evaluation. Moreover, we improve the agent's performance by fine-tuning GPT-4o through self-learning, using R-MCTS generated tree traversals without any human-provided labels. On the challenging VisualWebArena benchmark, our GPT-4o-based R-MCTS agent achieves a 6% to 30% relative improvement across various tasks compared to the previous state-of-the-art. Additionally, we show that the knowledge gained from test-time search can be effectively transferred back to GPT-4o via fine-tuning. The fine-tuned GPT-4o matches 97% of R-MCTS's performance while reducing compute usage by a factor of four at test time. Furthermore, qualitative results reveal that the fine-tuned GPT-4o model demonstrates the ability to explore the environment, evaluate a state, and backtrack to viable ones when it detects that the current state cannot lead to success. Moreover, our work demonstrates the compute scaling properties in both training - data collection with R-MCTS - and testing time. These results suggest a promising research direction to enhance VLMs' reasoning and planning capabilities for agentic applications via test-time search and self-learning.
Rethinking Interpretability in the Era of Large Language Models
Jan 30, 2024

Interpretable machine learning has exploded as an area of interest over the last decade, sparked by the rise of increasingly large datasets and deep neural networks. Simultaneously, large language models (LLMs) have demonstrated remarkable capabilities across a wide array of tasks, offering a chance to rethink opportunities in interpretable machine learning. Notably, the capability to explain in natural language allows LLMs to expand the scale and complexity of patterns that can be given to a human. However, these new capabilities raise new challenges, such as hallucinated explanations and immense computational costs. In this position paper, we start by reviewing existing methods to evaluate the emerging field of LLM interpretation (both interpreting LLMs and using LLMs for explanation). We contend that, despite their limitations, LLMs hold the opportunity to redefine interpretability with a more ambitious scope across many applications, including in auditing LLMs themselves. We highlight two emerging research priorities for LLM interpretation: using LLMs to directly analyze new datasets and to generate interactive explanations.
Teaching Language Models to Self-Improve through Interactive Demonstrations
Oct 20, 2023



The self-improving ability of large language models (LLMs), enabled by prompting them to analyze and revise their own outputs, has garnered significant interest in recent research. However, this ability has been shown to be absent and difficult to learn for smaller models, thus widening the performance gap between state-of-the-art LLMs and more cost-effective and faster ones. To reduce this gap, we introduce TriPosT, a training algorithm that endows smaller models with such self-improvement ability, and show that our approach can improve a LLaMA-7b's performance on math and reasoning tasks by up to 7.13%. In contrast to prior work, we achieve this by using the smaller model to interact with LLMs to collect feedback and improvements on its own generations. We then replay this experience to train the small model. Our experiments on four math and reasoning datasets show that the interactive experience of learning from and correcting its own mistakes is crucial for small models to improve their performance.
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Oct 03, 2023Although Large Language Models (LLMs) and Large Multimodal Models (LMMs) exhibit impressive skills in various domains, their ability for mathematical reasoning within visual contexts has not been formally examined. Equipping LLMs and LMMs with this capability is vital for general-purpose AI assistants and showcases promising potential in education, data analysis, and scientific discovery. To bridge this gap, we present MathVista, a benchmark designed to amalgamate challenges from diverse mathematical and visual tasks. We first taxonomize the key task types, reasoning skills, and visual contexts from the literature to guide our selection from 28 existing math-focused and visual question answering datasets. Then, we construct three new datasets, IQTest, FunctionQA, and PaperQA, to accommodate for missing types of visual contexts. The problems featured often require deep visual understanding beyond OCR or image captioning, and compositional reasoning with rich domain-specific tools, thus posing a notable challenge to existing models. We conduct a comprehensive evaluation of 11 prominent open-source and proprietary foundation models (LLMs, LLMs augmented with tools, and LMMs), and early experiments with GPT-4V. The best-performing model, Multimodal Bard, achieves only 58% of human performance (34.8% vs 60.3%), indicating ample room for further improvement. Given this significant gap, MathVista fuels future research in the development of general-purpose AI agents capable of tackling mathematically intensive and visually rich real-world tasks. Preliminary tests show that MathVista also presents challenges to GPT-4V, underscoring the benchmark's importance. The project is available at https://mathvista.github.io/.
Self-Verification Improves Few-Shot Clinical Information Extraction
May 30, 2023Extracting patient information from unstructured text is a critical task in health decision-support and clinical research. Large language models (LLMs) have shown the potential to accelerate clinical curation via few-shot in-context learning, in contrast to supervised learning which requires much more costly human annotations. However, despite drastic advances in modern LLMs such as GPT-4, they still struggle with issues regarding accuracy and interpretability, especially in mission-critical domains such as health. Here, we explore a general mitigation framework using self-verification, which leverages the LLM to provide provenance for its own extraction and check its own outputs. This is made possible by the asymmetry between verification and generation, where the latter is often much easier than the former. Experimental results show that our method consistently improves accuracy for various LLMs in standard clinical information extraction tasks. Additionally, self-verification yields interpretations in the form of a short text span corresponding to each output, which makes it very efficient for human experts to audit the results, paving the way towards trustworthy extraction of clinical information in resource-constrained scenarios. To facilitate future research in this direction, we release our code and prompts.
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models
Apr 19, 2023Large language models (LLMs) have achieved remarkable progress in various natural language processing tasks with emergent abilities. However, they face inherent limitations, such as an inability to access up-to-date information, utilize external tools, or perform precise mathematical reasoning. In this paper, we introduce Chameleon, a plug-and-play compositional reasoning framework that augments LLMs to help address these challenges. Chameleon synthesizes programs to compose various tools, including LLM models, off-the-shelf vision models, web search engines, Python functions, and rule-based modules tailored to user interests. Built on top of an LLM as a natural language planner, Chameleon infers the appropriate sequence of tools to compose and execute in order to generate a final response. We showcase the adaptability and effectiveness of Chameleon on two tasks: ScienceQA and TabMWP. Notably, Chameleon with GPT-4 achieves an 86.54% accuracy on ScienceQA, significantly improving upon the best published few-shot model by 11.37%; using GPT-4 as the underlying LLM, Chameleon achieves a 17.8% increase over the state-of-the-art model, leading to a 98.78% overall accuracy on TabMWP. Further studies suggest that using GPT-4 as a planner exhibits more consistent and rational tool selection and is able to infer potential constraints given the instructions, compared to other LLMs like ChatGPT.
Instruction Tuning with GPT-4
Apr 06, 2023Prior work has shown that finetuning large language models (LLMs) using machine-generated instruction-following data enables such models to achieve remarkable zero-shot capabilities on new tasks, and no human-written instructions are needed. In this paper, we present the first attempt to use GPT-4 to generate instruction-following data for LLM finetuning. Our early experiments on instruction-tuned LLaMA models show that the 52K English and Chinese instruction-following data generated by GPT-4 leads to superior zero-shot performance on new tasks to the instruction-following data generated by previous state-of-the-art models. We also collect feedback and comparison data from GPT-4 to enable a comprehensive evaluation and reward model training. We make our data generated using GPT-4 as well as our codebase publicly available.