 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Self-Tuning LLMs for Enhanced Jailbreaking Capabilities
Oct 24, 2024



Recent research has shown that Large Language Models (LLMs) are vulnerable to automated jailbreak attacks, where adversarial suffixes crafted by algorithms appended to harmful queries bypass safety alignment and trigger unintended responses. Current methods for generating these suffixes are computationally expensive and have low Attack Success Rates (ASR), especially against well-aligned models like Llama2 and Llama3. To overcome these limitations, we introduce ADV-LLM, an iterative self-tuning process that crafts adversarial LLMs with enhanced jailbreak ability. Our framework significantly reduces the computational cost of generating adversarial suffixes while achieving nearly 100\% ASR on various open-source LLMs. Moreover, it exhibits strong attack transferability to closed-source models, achieving 99% ASR on GPT-3.5 and 49% ASR on GPT-4, despite being optimized solely on Llama3. Beyond improving jailbreak ability, ADV-LLM provides valuable insights for future safety alignment research through its ability to generate large datasets for studying LLM safety. Our code is available at: https://github.com/SunChungEn/ADV-LLM
PLAtE: A Large-scale Dataset for List Page Web Extraction
May 24, 2022
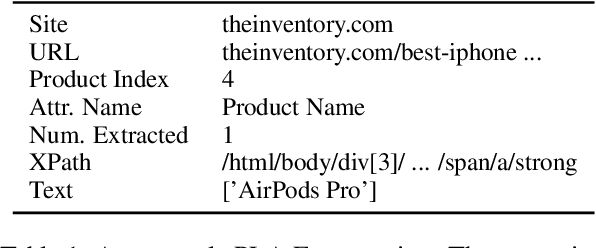

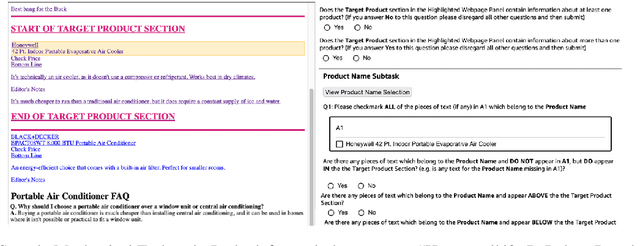
Recently, neural models have been leveraged to significantly improve the performance of information extraction from semi-structured websites. However, a barrier for continued progress is the small number of datasets large enough to train these models. In this work, we introduce the PLAtE (Pages of Lists Attribute Extraction) dataset as a challenging new web extraction task. PLAtE focuses on shopping data, specifically extractions from product review pages with multiple items. PLAtE encompasses both the tasks of: (1) finding product-list segmentation boundaries and (2) extracting attributes for each product. PLAtE is composed of 53, 905 items from 6, 810 pages, making it the first large-scale list page web extraction dataset. We construct PLAtE by collecting list pages from Common Crawl, then annotating them on Mechanical Turk. Quantitative and qualitative analyses are performed to demonstrate PLAtE has high-quality annotations. We establish strong baseline performance on PLAtE with a SOTA model achieving an F1-score of 0.750 for attribute classification and 0.915 for segmentation, indicating opportunities for future research innovations in web extraction.
A Tale of Two Linkings: Dynamically Gating between Schema Linking and Structural Linking for Text-to-SQL Parsing
Sep 30, 2020
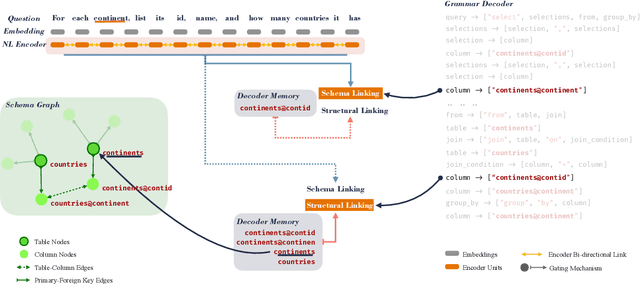
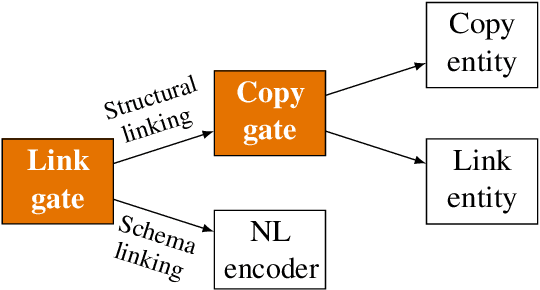

In Text-to-SQL semantic parsing, selecting the correct entities (tables and columns) to output is both crucial and challenging; the parser is required to connect the natural language (NL) question and the current SQL prediction with the structured world, i.e., the database. We formulate two linking processes to address this challenge: schema linking which links explicit NL mentions to the database and structural linking which links the entities in the output SQL with their structural relationships in the database schema. Intuitively, the effects of these two linking processes change based on the entity being generated, thus we propose to dynamically choose between them using a gating mechanism. Integrating the proposed method with two graph neural network based semantic parsers together with BERT representations demonstrates substantial gains in parsing accuracy on the challenging Spider dataset. Analyses show that our method helps to enhance the structure of the model output when generating complicated SQL queries and offers explainable predictions.