 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMem: Context Management with A Decoupled Long-Context Model
May 29, 2026Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra summarization tokens, which significantly affect the end-to-end response latency at deployment. In this paper, we introduce CoMem, a novel framework that decouples memory management from the primary agent workflow, enabling these processes to execute in parallel. We propose a $k$-step-off asynchronous pipeline that overlaps the memory model's summarization with the agent's inference, effectively masking the latency of context processing. To ensure robustness under this asynchronous setting, we introduce a reward-driven training strategy that aligns the memory model to capture sufficient statistics for the agent's decision-making. Theoretical analysis confirms that CoMem offers a superior efficiency-effectiveness trade-off compared to coupled architectures. Our extensive experimental results on SWE-Bench-Verified show that CoMem provides 1.4x latency improvements upon vanilla long-context solutions while preserving most of the performance. Furthermore, we demonstrate that these latency gains scale favorably with increased system throughput, offering a modular path forward for the independent optimization of agent reasoning and memory compression.
ByteFlow: Language Modeling through Adaptive Byte Compression without a Tokenizer
Mar 03, 2026Modern language models still rely on fixed, pre-defined subword tokenizations. Once a tokenizer is trained, the LM can only operate at this fixed level of granularity, which often leads to brittle and counterintuitive behaviors even in otherwise strong reasoning models. We introduce \textbf{ByteFlow Net}, a new hierarchical architecture that removes tokenizers entirely and instead enables models to learn their own segmentation of raw byte streams into semantically meaningful units. ByteFlow Net performs compression-driven segmentation based on the coding rate of latent representations, yielding adaptive boundaries \emph{while preserving a static computation graph via Top-$K$ selection}. Unlike prior self-tokenizing methods that depend on brittle heuristics with human-designed inductive biases, ByteFlow Net adapts its internal representation granularity to the input itself. Experiments demonstrate that this compression-based chunking strategy yields substantial performance gains, with ByteFlow Net outperforming both BPE-based Transformers and previous byte-level architectures. These results suggest that end-to-end, tokenizer-free modeling is not only feasible but also more effective, opening a path toward more adaptive and information-grounded language models.
Extracting Shopping Interest-Related Product Types from the Web
May 23, 2023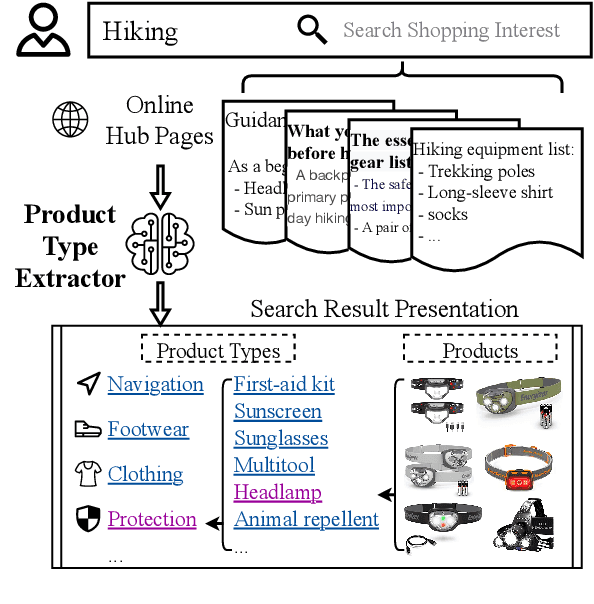
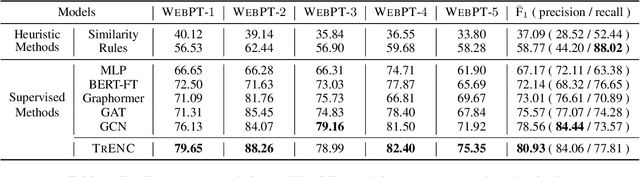
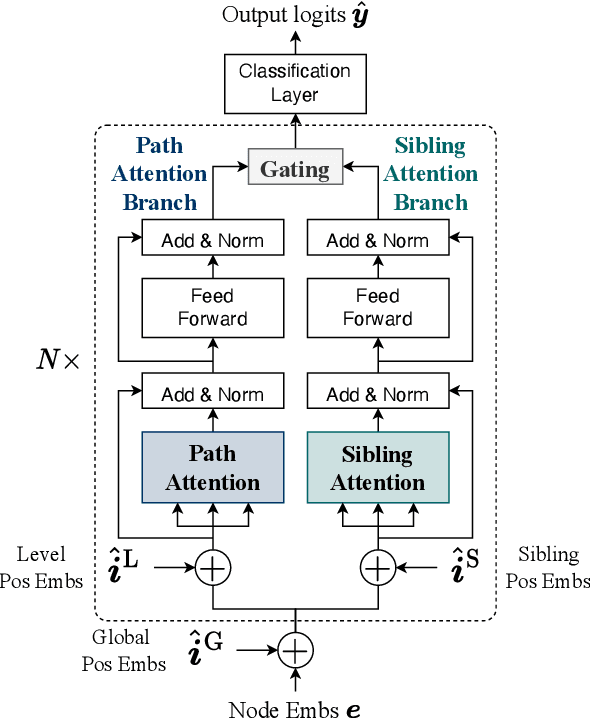
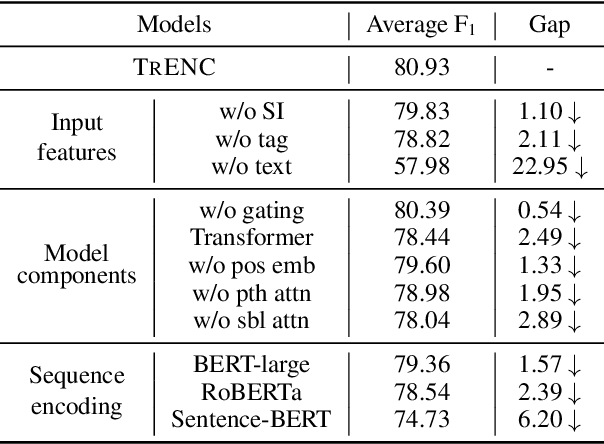
Recommending a diversity of product types (PTs) is important for a good shopping experience when customers are looking for products around their high-level shopping interests (SIs) such as hiking. However, the SI-PT connection is typically absent in e-commerce product catalogs and expensive to construct manually due to the volume of potential SIs, which prevents us from establishing a recommender with easily accessible knowledge systems. To establish such connections, we propose to extract PTs from the Web pages containing hand-crafted PT recommendations for SIs. The extraction task is formulated as binary HTML node classification given the general observation that an HTML node in our target Web pages can present one and only one PT phrase. Accordingly, we introduce TrENC, which stands for Tree-Transformer Encoders for Node Classification. It improves the inter-node dependency modeling with modified attention mechanisms that preserve the long-term sibling and ancestor-descendant relations. TrENC also injects SI into node features for better semantic representation. Trained on pages regarding limited SIs, TrEnc is ready to be applied to other unobserved interests. Experiments on our manually constructed dataset, WebPT, show that TrENC outperforms the best baseline model by 2.37 F1 points in the zero-shot setup. The performance indicates the feasibility of constructing SI-PT relations and using them to power downstream applications such as search and recommendation.
Label-Efficient Self-Training for Attribute Extraction from Semi-Structured Web Documents
Aug 27, 2022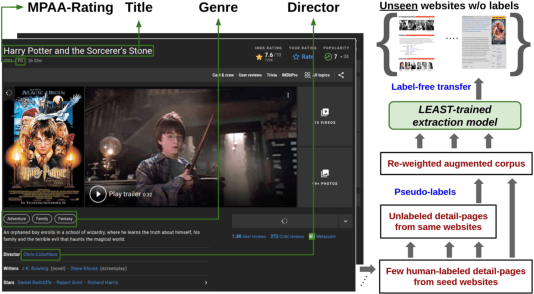

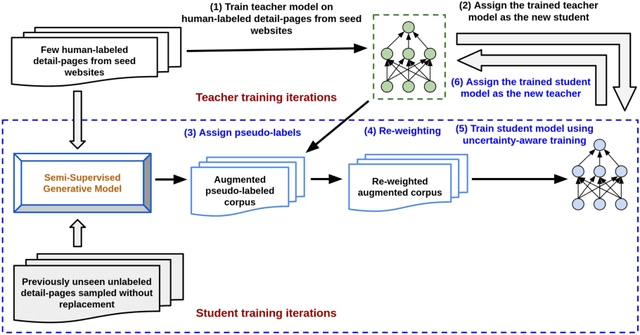
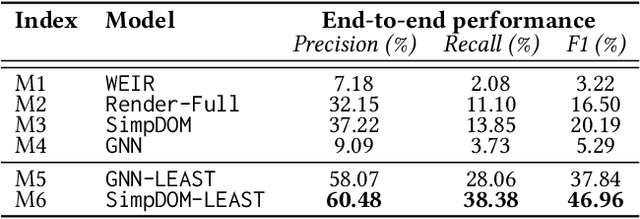
Extracting structured information from HTML documents is a long-studied problem with a broad range of applications, including knowledge base construction, faceted search, and personalized recommendation. Prior works rely on a few human-labeled web pages from each target website or thousands of human-labeled web pages from some seed websites to train a transferable extraction model that generalizes on unseen target websites. Noisy content, low site-level consistency, and lack of inter-annotator agreement make labeling web pages a time-consuming and expensive ordeal. We develop LEAST -- a Label-Efficient Self-Training method for Semi-Structured Web Documents to overcome these limitations. LEAST utilizes a few human-labeled pages to pseudo-annotate a large number of unlabeled web pages from the target vertical. It trains a transferable web-extraction model on both human-labeled and pseudo-labeled samples using self-training. To mitigate error propagation due to noisy training samples, LEAST re-weights each training sample based on its estimated label accuracy and incorporates it in training. To the best of our knowledge, this is the first work to propose end-to-end training for transferable web extraction models utilizing only a few human-labeled pages. Experiments on a large-scale public dataset show that using less than ten human-labeled pages from each seed website for training, a LEAST-trained model outperforms previous state-of-the-art by more than 26 average F1 points on unseen websites, reducing the number of human-labeled pages to achieve similar performance by more than 10x.
PLAtE: A Large-scale Dataset for List Page Web Extraction
May 24, 2022
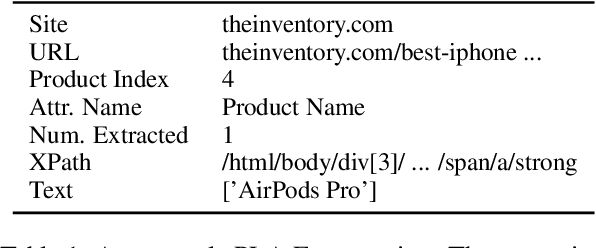

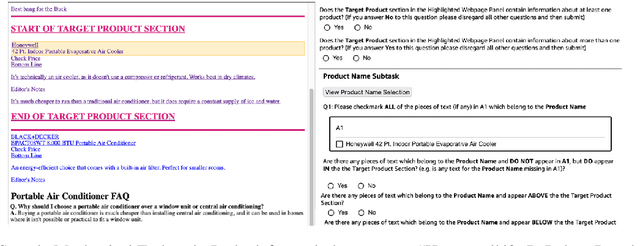
Recently, neural models have been leveraged to significantly improve the performance of information extraction from semi-structured websites. However, a barrier for continued progress is the small number of datasets large enough to train these models. In this work, we introduce the PLAtE (Pages of Lists Attribute Extraction) dataset as a challenging new web extraction task. PLAtE focuses on shopping data, specifically extractions from product review pages with multiple items. PLAtE encompasses both the tasks of: (1) finding product-list segmentation boundaries and (2) extracting attributes for each product. PLAtE is composed of 53, 905 items from 6, 810 pages, making it the first large-scale list page web extraction dataset. We construct PLAtE by collecting list pages from Common Crawl, then annotating them on Mechanical Turk. Quantitative and qualitative analyses are performed to demonstrate PLAtE has high-quality annotations. We establish strong baseline performance on PLAtE with a SOTA model achieving an F1-score of 0.750 for attribute classification and 0.915 for segmentation, indicating opportunities for future research innovations in web extraction.
DOM-LM: Learning Generalizable Representations for HTML Documents
Jan 25, 2022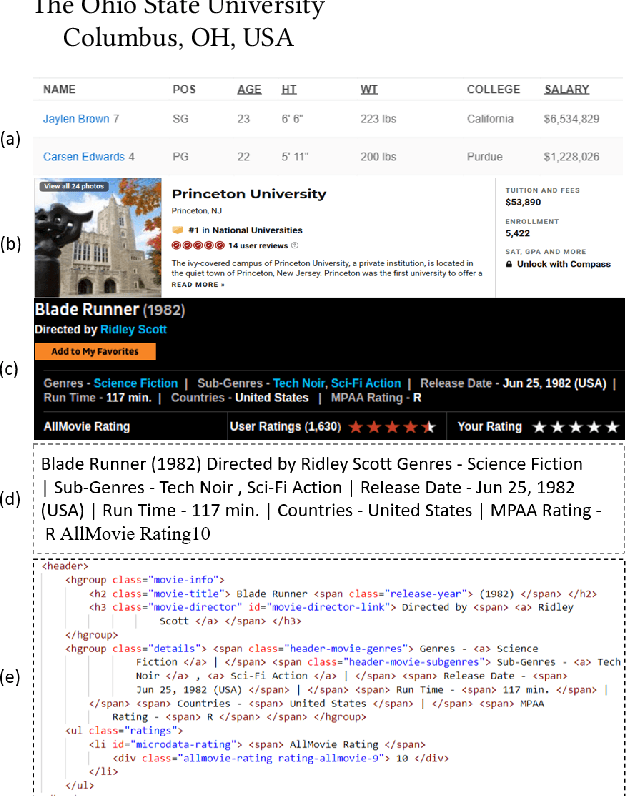

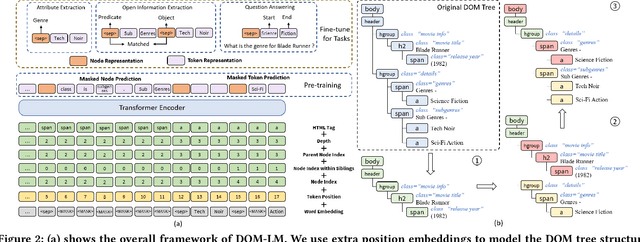
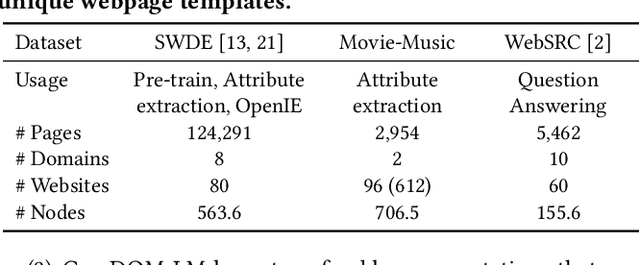
HTML documents are an important medium for disseminating information on the Web for human consumption. An HTML document presents information in multiple text formats including unstructured text, structured key-value pairs, and tables. Effective representation of these documents is essential for machine understanding to enable a wide range of applications, such as Question Answering, Web Search, and Personalization. Existing work has either represented these documents using visual features extracted by rendering them in a browser, which is typically computationally expensive, or has simply treated them as plain text documents, thereby failing to capture useful information presented in their HTML structure. We argue that the text and HTML structure together convey important semantics of the content and therefore warrant a special treatment for their representation learning. In this paper, we introduce a novel representation learning approach for web pages, dubbed DOM-LM, which addresses the limitations of existing approaches by encoding both text and DOM tree structure with a transformer-based encoder and learning generalizable representations for HTML documents via self-supervised pre-training. We evaluate DOM-LM on a variety of webpage understanding tasks, including Attribute Extraction, Open Information Extraction, and Question Answering. Our extensive experiments show that DOM-LM consistently outperforms all baselines designed for these tasks. In particular, DOM-LM demonstrates better generalization performance both in few-shot and zero-shot settings, making it attractive for making it suitable for real-world application settings with limited labeled data.
TCN: Table Convolutional Network for Web Table Interpretation
Feb 17, 2021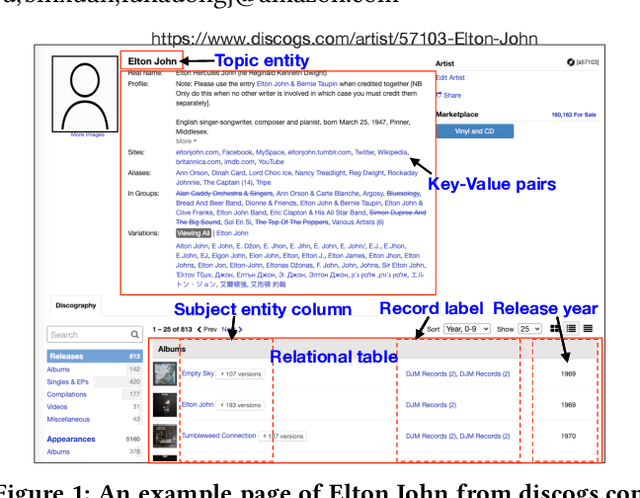
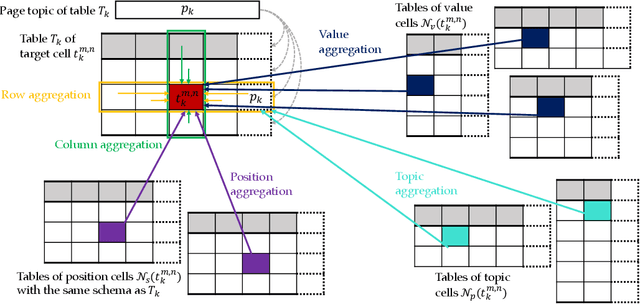
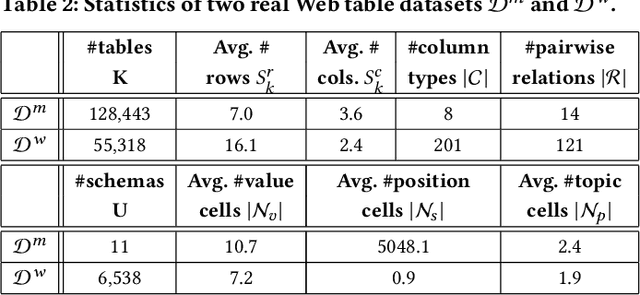
Information extraction from semi-structured webpages provides valuable long-tailed facts for augmenting knowledge graph. Relational Web tables are a critical component containing additional entities and attributes of rich and diverse knowledge. However, extracting knowledge from relational tables is challenging because of sparse contextual information. Existing work linearize table cells and heavily rely on modifying deep language models such as BERT which only captures related cells information in the same table. In this work, we propose a novel relational table representation learning approach considering both the intra- and inter-table contextual information. On one hand, the proposed Table Convolutional Network model employs the attention mechanism to adaptively focus on the most informative intra-table cells of the same row or column; and, on the other hand, it aggregates inter-table contextual information from various types of implicit connections between cells across different tables. Specifically, we propose three novel aggregation modules for (i) cells of the same value, (ii) cells of the same schema position, and (iii) cells linked to the same page topic. We further devise a supervised multi-task training objective for jointly predicting column type and pairwise column relation, as well as a table cell recovery objective for pre-training. Experiments on real Web table datasets demonstrate our method can outperform competitive baselines by +4.8% of F1 for column type prediction and by +4.1% of F1 for pairwise column relation prediction.
ZeroShotCeres: Zero-Shot Relation Extraction from Semi-Structured Webpages
May 14, 2020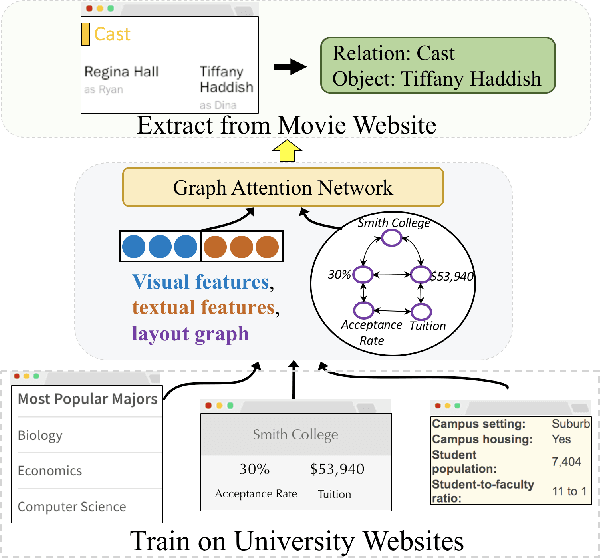

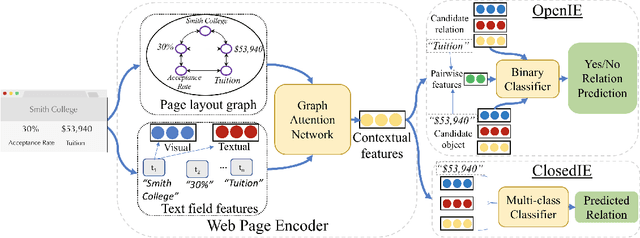

In many documents, such as semi-structured webpages, textual semantics are augmented with additional information conveyed using visual elements including layout, font size, and color. Prior work on information extraction from semi-structured websites has required learning an extraction model specific to a given template via either manually labeled or distantly supervised data from that template. In this work, we propose a solution for "zero-shot" open-domain relation extraction from webpages with a previously unseen template, including from websites with little overlap with existing sources of knowledge for distant supervision and websites in entirely new subject verticals. Our model uses a graph neural network-based approach to build a rich representation of text fields on a webpage and the relationships between them, enabling generalization to new templates. Experiments show this approach provides a 31% F1 gain over a baseline for zero-shot extraction in a new subject vertical.
OpenKI: Integrating Open Information Extraction and Knowledge Bases with Relation Inference
Apr 12, 2019
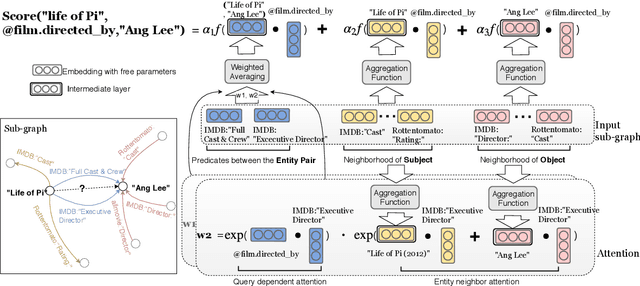
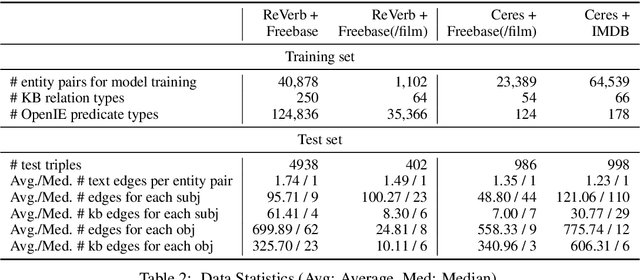
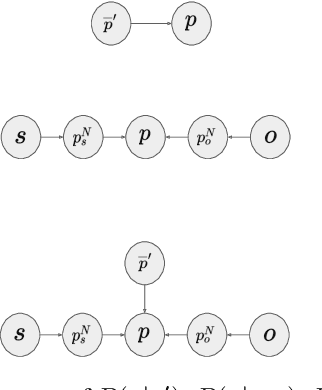
In this paper, we consider advancing web-scale knowledge extraction and alignment by integrating OpenIE extractions in the form of (subject, predicate, object) triples with Knowledge Bases (KB). Traditional techniques from universal schema and from schema mapping fall in two extremes: either they perform instance-level inference relying on embedding for (subject, object) pairs, thus cannot handle pairs absent in any existing triples; or they perform predicate-level mapping and completely ignore background evidence from individual entities, thus cannot achieve satisfying quality. We propose OpenKI to handle sparsity of OpenIE extractions by performing instance-level inference: for each entity, we encode the rich information in its neighborhood in both KB and OpenIE extractions, and leverage this information in relation inference by exploring different methods of aggregation and attention. In order to handle unseen entities, our model is designed without creating entity-specific parameters. Extensive experiments show that this method not only significantly improves state-of-the-art for conventional OpenIE extractions like ReVerb, but also boosts the performance on OpenIE from semi-structured data, where new entity pairs are abundant and data are fairly sparse.
Semi-Supervised Event Extraction with Paraphrase Clusters
Aug 26, 2018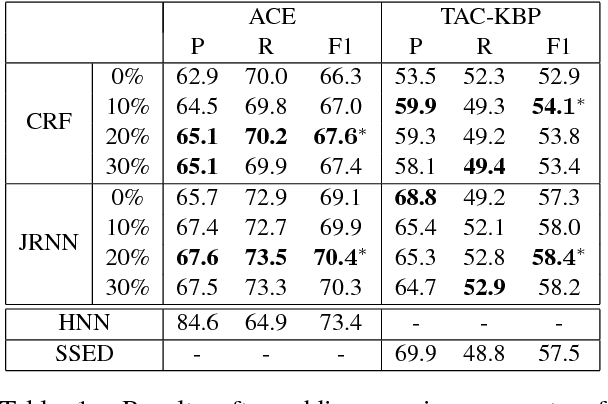
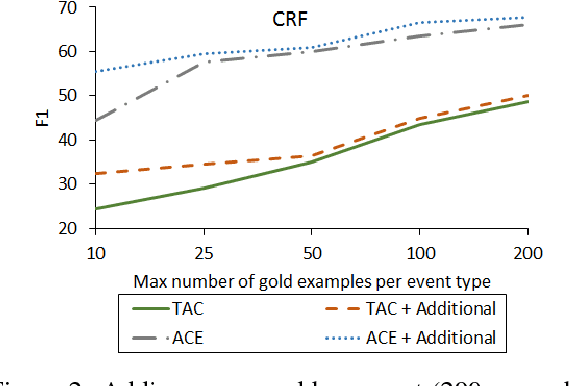

Supervised event extraction systems are limited in their accuracy due to the lack of available training data. We present a method for self-training event extraction systems by bootstrapping additional training data. This is done by taking advantage of the occurrence of multiple mentions of the same event instances across newswire articles from multiple sources. If our system can make a highconfidence extraction of some mentions in such a cluster, it can then acquire diverse training examples by adding the other mentions as well. Our experiments show significant performance improvements on multiple event extractors over ACE 2005 and TAC-KBP 2015 datasets.