 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Efficient Self-Training for Attribute Extraction from Semi-Structured Web Documents
Paper and Code
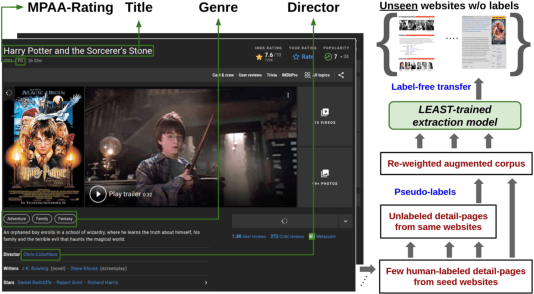

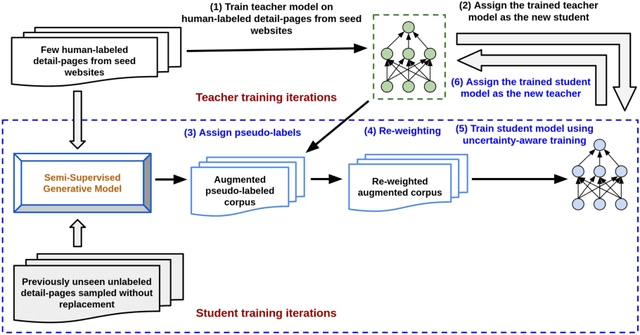
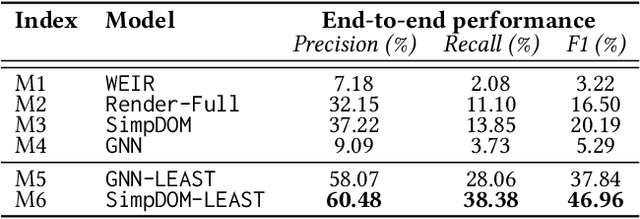
Extracting structured information from HTML documents is a long-studied problem with a broad range of applications, including knowledge base construction, faceted search, and personalized recommendation. Prior works rely on a few human-labeled web pages from each target website or thousands of human-labeled web pages from some seed websites to train a transferable extraction model that generalizes on unseen target websites. Noisy content, low site-level consistency, and lack of inter-annotator agreement make labeling web pages a time-consuming and expensive ordeal. We develop LEAST -- a Label-Efficient Self-Training method for Semi-Structured Web Documents to overcome these limitations. LEAST utilizes a few human-labeled pages to pseudo-annotate a large number of unlabeled web pages from the target vertical. It trains a transferable web-extraction model on both human-labeled and pseudo-labeled samples using self-training. To mitigate error propagation due to noisy training samples, LEAST re-weights each training sample based on its estimated label accuracy and incorporates it in training. To the best of our knowledge, this is the first work to propose end-to-end training for transferable web extraction models utilizing only a few human-labeled pages. Experiments on a large-scale public dataset show that using less than ten human-labeled pages from each seed website for training, a LEAST-trained model outperforms previous state-of-the-art by more than 26 average F1 points on unseen websites, reducing the number of human-labeled pages to achieve similar performance by more than 10x.