 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Proxy for Human Labeling: Ensemble Disagreement Scores in Large Language Models for Industrial NLP
Sep 11, 2023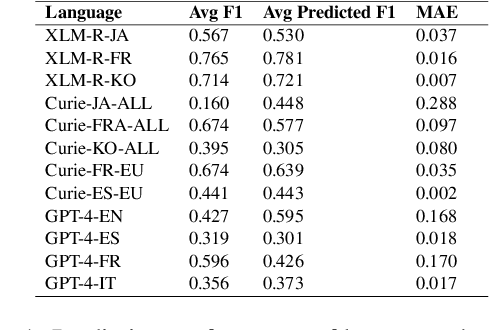
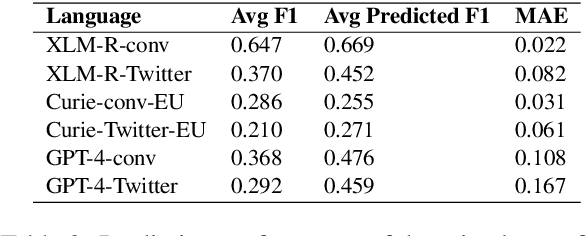
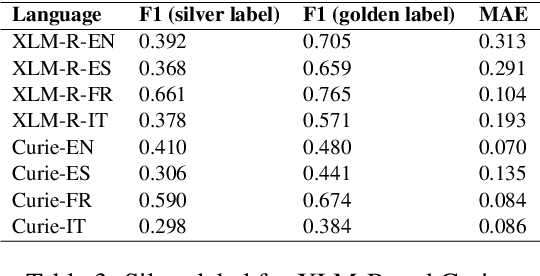
Large language models (LLMs) have demonstrated significant capability to generalize across a large number of NLP tasks. For industry applications, it is imperative to assess the performance of the LLM on unlabeled production data from time to time to validate for a real-world setting. Human labeling to assess model error requires considerable expense and time delay. Here we demonstrate that ensemble disagreement scores work well as a proxy for human labeling for language models in zero-shot, few-shot, and fine-tuned settings, per our evaluation on keyphrase extraction (KPE) task. We measure fidelity of the results by comparing to true error measured from human labeled ground truth. We contrast with the alternative of using another LLM as a source of machine labels, or silver labels. Results across various languages and domains show disagreement scores provide a better estimation of model performance with mean average error (MAE) as low as 0.4% and on average 13.8% better than using silver labels.
Extracting Shopping Interest-Related Product Types from the Web
May 23, 2023Recommending a diversity of product types (PTs) is important for a good shopping experience when customers are looking for products around their high-level shopping interests (SIs) such as hiking. However, the SI-PT connection is typically absent in e-commerce product catalogs and expensive to construct manually due to the volume of potential SIs, which prevents us from establishing a recommender with easily accessible knowledge systems. To establish such connections, we propose to extract PTs from the Web pages containing hand-crafted PT recommendations for SIs. The extraction task is formulated as binary HTML node classification given the general observation that an HTML node in our target Web pages can present one and only one PT phrase. Accordingly, we introduce TrENC, which stands for Tree-Transformer Encoders for Node Classification. It improves the inter-node dependency modeling with modified attention mechanisms that preserve the long-term sibling and ancestor-descendant relations. TrENC also injects SI into node features for better semantic representation. Trained on pages regarding limited SIs, TrEnc is ready to be applied to other unobserved interests. Experiments on our manually constructed dataset, WebPT, show that TrENC outperforms the best baseline model by 2.37 F1 points in the zero-shot setup. The performance indicates the feasibility of constructing SI-PT relations and using them to power downstream applications such as search and recommendation.
Label-Efficient Self-Training for Attribute Extraction from Semi-Structured Web Documents
Aug 27, 2022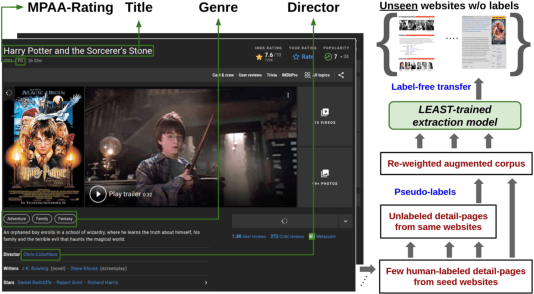

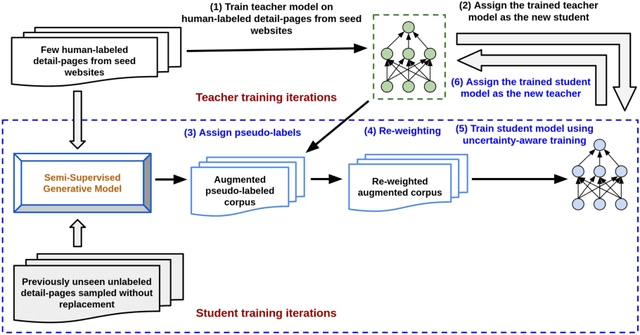
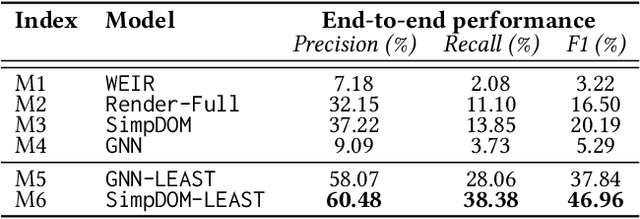
Extracting structured information from HTML documents is a long-studied problem with a broad range of applications, including knowledge base construction, faceted search, and personalized recommendation. Prior works rely on a few human-labeled web pages from each target website or thousands of human-labeled web pages from some seed websites to train a transferable extraction model that generalizes on unseen target websites. Noisy content, low site-level consistency, and lack of inter-annotator agreement make labeling web pages a time-consuming and expensive ordeal. We develop LEAST -- a Label-Efficient Self-Training method for Semi-Structured Web Documents to overcome these limitations. LEAST utilizes a few human-labeled pages to pseudo-annotate a large number of unlabeled web pages from the target vertical. It trains a transferable web-extraction model on both human-labeled and pseudo-labeled samples using self-training. To mitigate error propagation due to noisy training samples, LEAST re-weights each training sample based on its estimated label accuracy and incorporates it in training. To the best of our knowledge, this is the first work to propose end-to-end training for transferable web extraction models utilizing only a few human-labeled pages. Experiments on a large-scale public dataset show that using less than ten human-labeled pages from each seed website for training, a LEAST-trained model outperforms previous state-of-the-art by more than 26 average F1 points on unseen websites, reducing the number of human-labeled pages to achieve similar performance by more than 10x.
DOM-LM: Learning Generalizable Representations for HTML Documents
Jan 25, 2022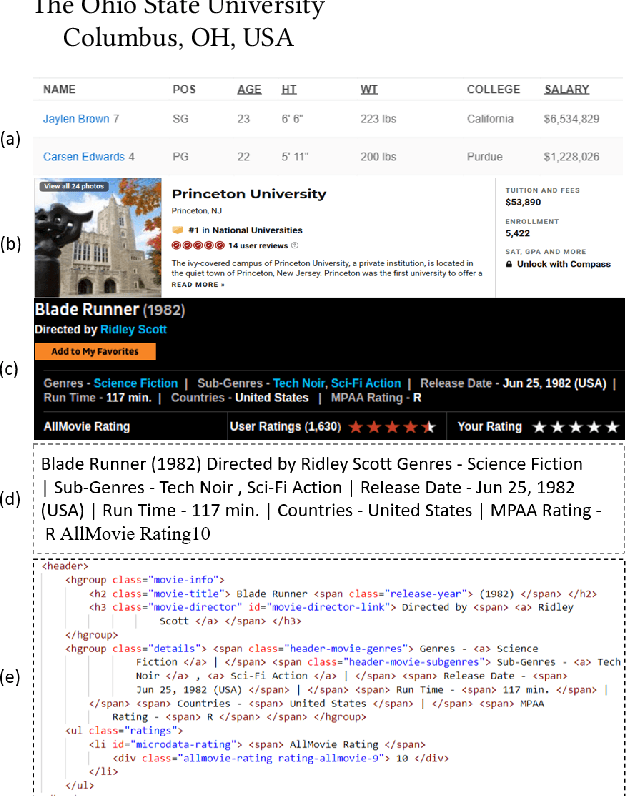

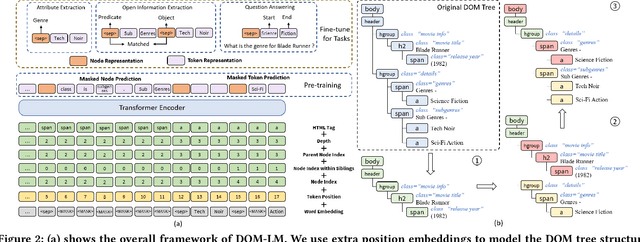
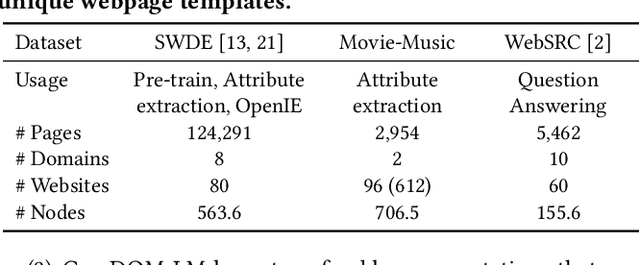
HTML documents are an important medium for disseminating information on the Web for human consumption. An HTML document presents information in multiple text formats including unstructured text, structured key-value pairs, and tables. Effective representation of these documents is essential for machine understanding to enable a wide range of applications, such as Question Answering, Web Search, and Personalization. Existing work has either represented these documents using visual features extracted by rendering them in a browser, which is typically computationally expensive, or has simply treated them as plain text documents, thereby failing to capture useful information presented in their HTML structure. We argue that the text and HTML structure together convey important semantics of the content and therefore warrant a special treatment for their representation learning. In this paper, we introduce a novel representation learning approach for web pages, dubbed DOM-LM, which addresses the limitations of existing approaches by encoding both text and DOM tree structure with a transformer-based encoder and learning generalizable representations for HTML documents via self-supervised pre-training. We evaluate DOM-LM on a variety of webpage understanding tasks, including Attribute Extraction, Open Information Extraction, and Question Answering. Our extensive experiments show that DOM-LM consistently outperforms all baselines designed for these tasks. In particular, DOM-LM demonstrates better generalization performance both in few-shot and zero-shot settings, making it attractive for making it suitable for real-world application settings with limited labeled data.
TCN: Table Convolutional Network for Web Table Interpretation
Feb 17, 2021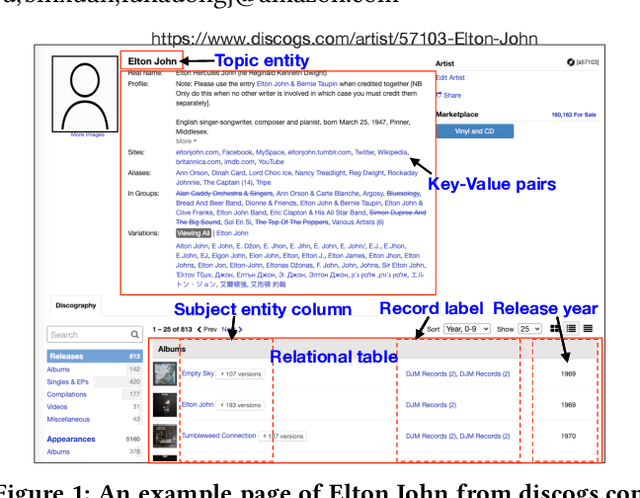
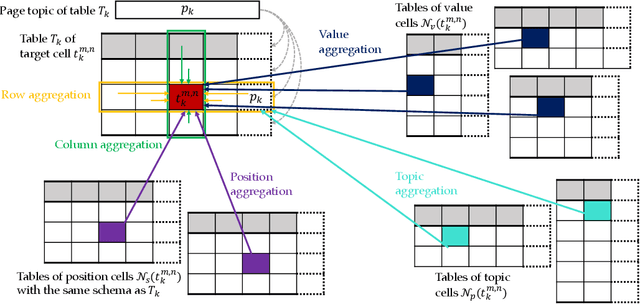
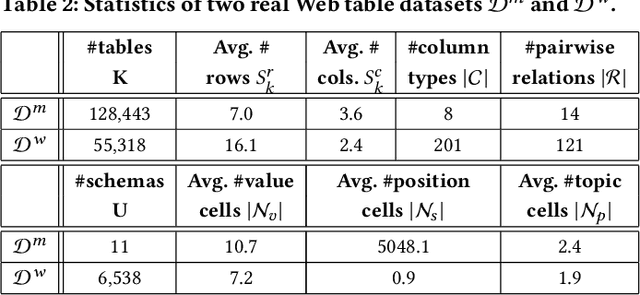
Information extraction from semi-structured webpages provides valuable long-tailed facts for augmenting knowledge graph. Relational Web tables are a critical component containing additional entities and attributes of rich and diverse knowledge. However, extracting knowledge from relational tables is challenging because of sparse contextual information. Existing work linearize table cells and heavily rely on modifying deep language models such as BERT which only captures related cells information in the same table. In this work, we propose a novel relational table representation learning approach considering both the intra- and inter-table contextual information. On one hand, the proposed Table Convolutional Network model employs the attention mechanism to adaptively focus on the most informative intra-table cells of the same row or column; and, on the other hand, it aggregates inter-table contextual information from various types of implicit connections between cells across different tables. Specifically, we propose three novel aggregation modules for (i) cells of the same value, (ii) cells of the same schema position, and (iii) cells linked to the same page topic. We further devise a supervised multi-task training objective for jointly predicting column type and pairwise column relation, as well as a table cell recovery objective for pre-training. Experiments on real Web table datasets demonstrate our method can outperform competitive baselines by +4.8% of F1 for column type prediction and by +4.1% of F1 for pairwise column relation prediction.
ZeroShotCeres: Zero-Shot Relation Extraction from Semi-Structured Webpages
May 14, 2020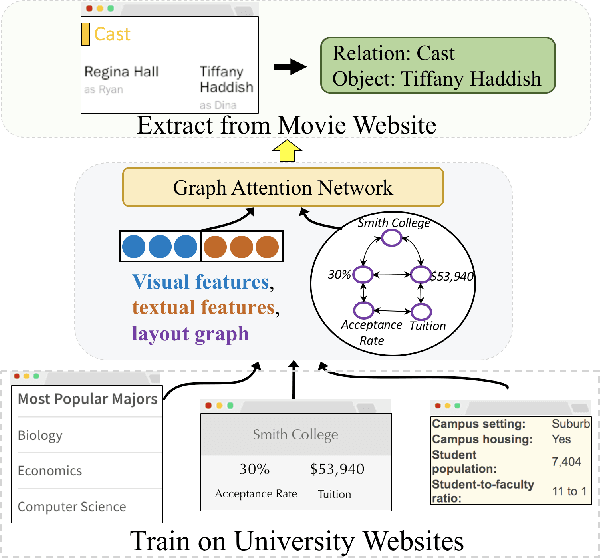

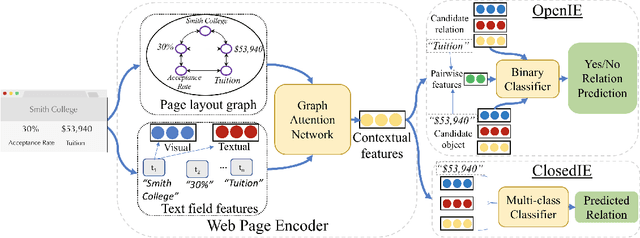

In many documents, such as semi-structured webpages, textual semantics are augmented with additional information conveyed using visual elements including layout, font size, and color. Prior work on information extraction from semi-structured websites has required learning an extraction model specific to a given template via either manually labeled or distantly supervised data from that template. In this work, we propose a solution for "zero-shot" open-domain relation extraction from webpages with a previously unseen template, including from websites with little overlap with existing sources of knowledge for distant supervision and websites in entirely new subject verticals. Our model uses a graph neural network-based approach to build a rich representation of text fields on a webpage and the relationships between them, enabling generalization to new templates. Experiments show this approach provides a 31% F1 gain over a baseline for zero-shot extraction in a new subject vertical.
TriggerNER: Learning with Entity Triggers as Explanations for Named Entity Recognition
Apr 24, 2020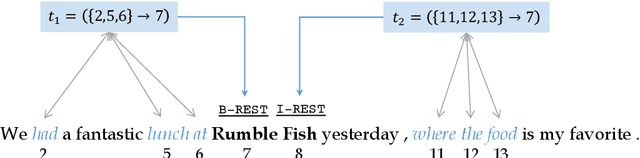
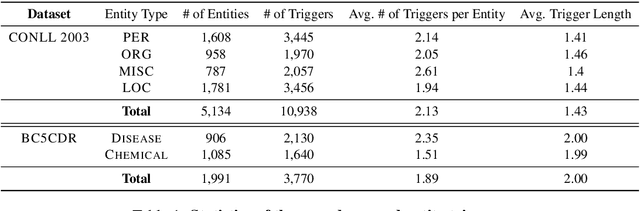
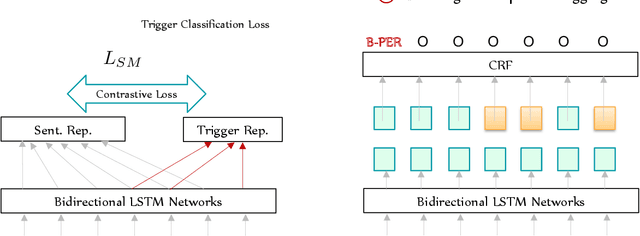
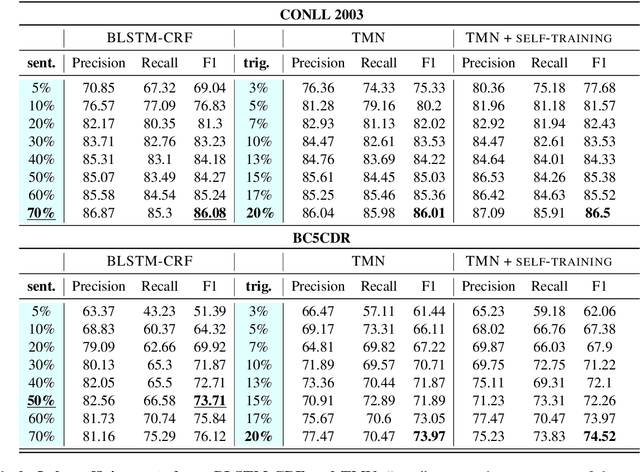
Training neural models for named entity recognition (NER) in a new domain often requires additional human annotations (e.g., tens of thousands of labeled instances) that are usually expensive and time-consuming to collect. Thus, a crucial research question is how to obtain supervision in a cost-effective way. In this paper, we introduce "entity triggers," an effective proxy of human explanations for facilitating label-efficient learning of NER models. An entity trigger is defined as a group of words in a sentence that helps to explain why humans would recognize an entity in the sentence. We crowd-sourced 14k entity triggers for two well-studied NER datasets. Our proposed model, Trigger Matching Network, jointly learns trigger representations and soft matching module with self-attention such that can generalize to unseen sentences easily for tagging. Our framework is significantly more cost-effective than the traditional neural NER frameworks. Experiments show that using only 20% of the trigger-annotated sentences results in a comparable performance as using 70% of conventional annotated sentences.
CERES: Distantly Supervised Relation Extraction from the Semi-Structured Web
Apr 12, 2018



The web contains countless semi-structured websites, which can be a rich source of information for populating knowledge bases. Existing methods for extracting relations from the DOM trees of semi-structured webpages can achieve high precision and recall only when manual annotations for each website are available. Although there have been efforts to learn extractors from automatically-generated labels, these methods are not sufficiently robust to succeed in settings with complex schemas and information-rich websites. In this paper we present a new method for automatic extraction from semi-structured websites based on distant supervision. We automatically generate training labels by aligning an existing knowledge base with a web page and leveraging the unique structural characteristics of semi-structured websites. We then train a classifier based on the potentially noisy and incomplete labels to predict new relation instances. Our method can compete with annotation-based techniques in the literature in terms of extraction quality. A large-scale experiment on over 400,000 pages from dozens of multi-lingual long-tail websites harvested 1.25 million facts at a precision of 90%.
Finding Streams in Knowledge Graphs to Support Fact Checking
Aug 24, 2017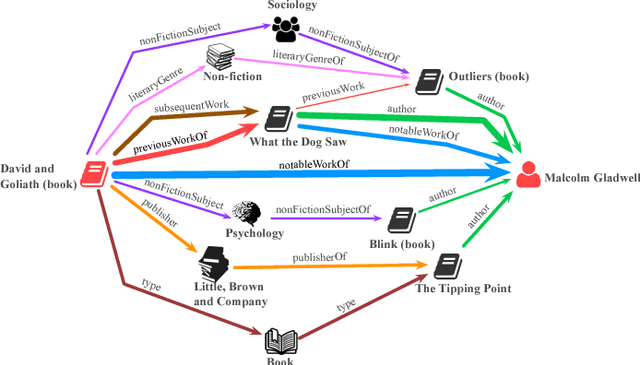

The volume and velocity of information that gets generated online limits current journalistic practices to fact-check claims at the same rate. Computational approaches for fact checking may be the key to help mitigate the risks of massive misinformation spread. Such approaches can be designed to not only be scalable and effective at assessing veracity of dubious claims, but also to boost a human fact checker's productivity by surfacing relevant facts and patterns to aid their analysis. To this end, we present a novel, unsupervised network-flow based approach to determine the truthfulness of a statement of fact expressed in the form of a (subject, predicate, object) triple. We view a knowledge graph of background information about real-world entities as a flow network, and knowledge as a fluid, abstract commodity. We show that computational fact checking of such a triple then amounts to finding a "knowledge stream" that emanates from the subject node and flows toward the object node through paths connecting them. Evaluation on a range of real-world and hand-crafted datasets of facts related to entertainment, business, sports, geography and more reveals that this network-flow model can be very effective in discerning true statements from false ones, outperforming existing algorithms on many test cases. Moreover, the model is expressive in its ability to automatically discover several useful path patterns and surface relevant facts that may help a human fact checker corroborate or refute a claim.
The DARPA Twitter Bot Challenge
Apr 21, 2016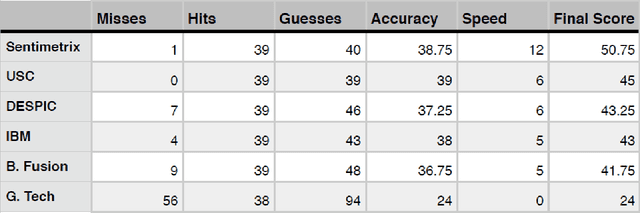
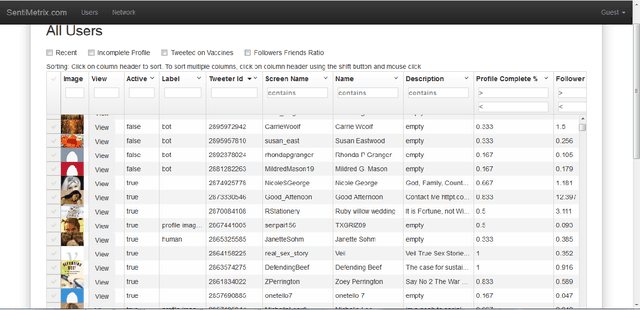
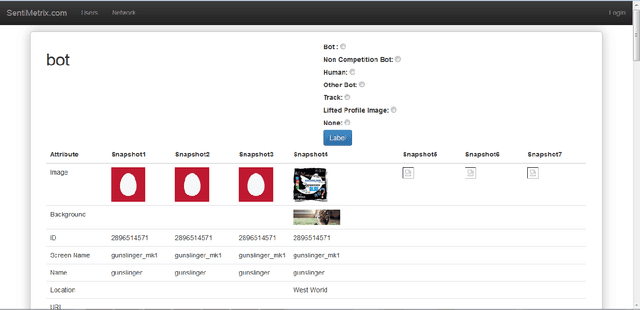
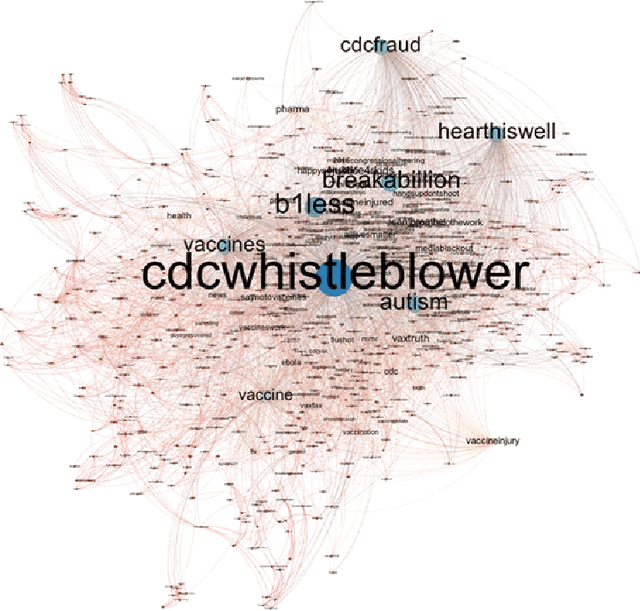
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press