 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Creation and Detection of AI-Generated Social Bot Content
Jun 05, 2026The convergence of large language models and social bots allows malicious actors to manipulate the information ecosystem by generating human-like content at scale. Existing models for detecting AI-generated content often fail in the wild, primarily due to the lack of ground-truth data. We address this gap through an adversarial methodology that models the impersonation of real social media users by malicious actors. Using this methodology, we curate a multilingual, cross-platform dataset of paired human and AI-generated messages. Training on such adversarial data yields accurate detection of AI-generated text. Our approach significantly outperforms existing models for content-based bot detection in real-world, out-of-distribution data.
LLMs Can Infer Political Alignment from Online Conversations
Mar 11, 2026Due to the correlational structure in our traits such as identities, cultures, and political attitudes, seemingly innocuous preferences such as following a band or using a specific slang, can reveal private traits. This possibility, especially when combined with massive, public social data and advanced computational methods, poses a fundamental privacy risk. Given our increasing data exposure online and the rapid advancement of AI are increasing the misuse potential of such risk, it is therefore critical to understand capacity of large language models (LLMs) to exploit it. Here, using online discussions on Debate.org and Reddit, we show that LLMs can reliably infer hidden political alignment, significantly outperforming traditional machine learning models. Prediction accuracy further improves as we aggregate multiple text-level inferences into a user-level prediction, and as we use more politics-adjacent domains. We demonstrate that LLMs leverage the words that can be highly predictive of political alignment while not being explicitly political. Our findings underscore the capacity and risks of LLMs for exploiting socio-cultural correlates.
A Marketplace for AI-Generated Adult Content and Deepfakes
Jan 14, 2026Generative AI systems increasingly enable the production of highly realistic synthetic media. Civitai, a popular community-driven platform for AI-generated content, operates a monetized feature called Bounties, which allows users to commission the generation of content in exchange for payment. To examine how this mechanism is used and what content it incentivizes, we conduct a longitudinal analysis of all publicly available bounty requests collected over a 14-month period following the platform's launch. We find that the bounty marketplace is dominated by tools that let users steer AI models toward content they were not trained to generate. At the same time, requests for content that is "Not Safe For Work" are widespread and have increased steadily over time, now comprising a majority of all bounties. Participation in bounty creation is uneven, with 20% of requesters accounting for roughly half of requests. Requests for "deepfake" - media depicting identifiable real individuals - exhibit a higher concentration than other types of bounties. A nontrivial subset of these requests involves explicit deepfakes despite platform policies prohibiting such content. These bounties disproportionately target female celebrities, revealing a pronounced gender asymmetry in social harm. Together, these findings show how monetized, community-driven generative AI platforms can produce gendered harms, raising questions about consent, governance, and enforcement.
Community Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
Coordinated Reply Attacks in Influence Operations: Characterization and Detection
Oct 25, 2024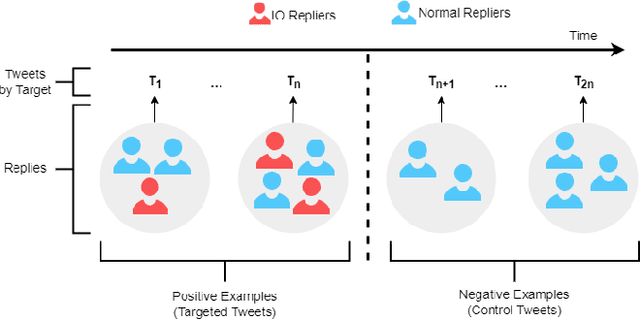

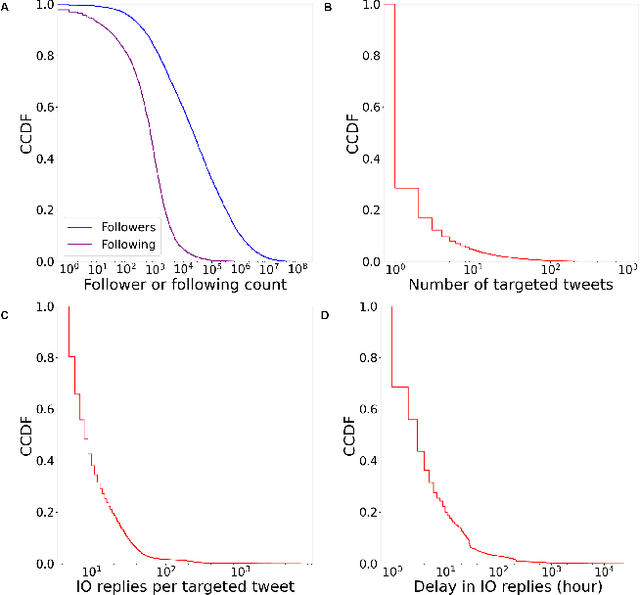
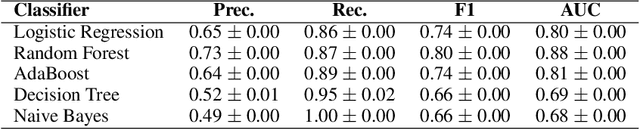
Coordinated reply attacks are a tactic observed in online influence operations and other coordinated campaigns to support or harass targeted individuals, or influence them or their followers. Despite its potential to influence the public, past studies have yet to analyze or provide a methodology to detect this tactic. In this study, we characterize coordinated reply attacks in the context of influence operations on Twitter. Our analysis reveals that the primary targets of these attacks are influential people such as journalists, news media, state officials, and politicians. We propose two supervised machine-learning models, one to classify tweets to determine whether they are targeted by a reply attack, and one to classify accounts that reply to a targeted tweet to determine whether they are part of a coordinated attack. The classifiers achieve AUC scores of 0.88 and 0.97, respectively. These results indicate that accounts involved in reply attacks can be detected, and the targeted accounts themselves can serve as sensors for influence operation detection.
Rematch: Robust and Efficient Matching of Local Knowledge Graphs to Improve Structural and Semantic Similarity
Apr 02, 2024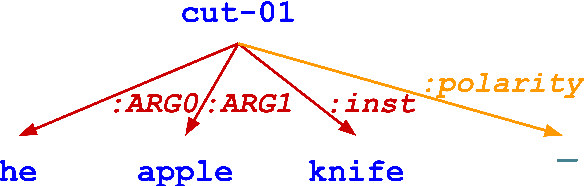



Knowledge graphs play a pivotal role in various applications, such as question-answering and fact-checking. Abstract Meaning Representation (AMR) represents text as knowledge graphs. Evaluating the quality of these graphs involves matching them structurally to each other and semantically to the source text. Existing AMR metrics are inefficient and struggle to capture semantic similarity. We also lack a systematic evaluation benchmark for assessing structural similarity between AMR graphs. To overcome these limitations, we introduce a novel AMR similarity metric, rematch, alongside a new evaluation for structural similarity called RARE. Among state-of-the-art metrics, rematch ranks second in structural similarity; and first in semantic similarity by 1--5 percentage points on the STS-B and SICK-R benchmarks. Rematch is also five times faster than the next most efficient metric.
Characteristics and prevalence of fake social media profiles with AI-generated faces
Jan 05, 2024

Recent advancements in generative artificial intelligence (AI) have raised concerns about their potential to create convincing fake social media accounts, but empirical evidence is lacking. In this paper, we present a systematic analysis of Twitter(X) accounts using human faces generated by Generative Adversarial Networks (GANs) for their profile pictures. We present a dataset of 1,353 such accounts and show that they are used to spread scams, spam, and amplify coordinated messages, among other inauthentic activities. Leveraging a feature of GAN-generated faces -- consistent eye placement -- and supplementing it with human annotation, we devise an effective method for identifying GAN-generated profiles in the wild. Applying this method to a random sample of active Twitter users, we estimate a lower bound for the prevalence of profiles using GAN-generated faces between 0.021% and 0.044% -- around 10K daily active accounts. These findings underscore the emerging threats posed by multimodal generative AI. We release the source code of our detection method and the data we collect to facilitate further investigation. Additionally, we provide practical heuristics to assist social media users in recognizing such accounts.
Factuality Challenges in the Era of Large Language Models
Oct 10, 2023The emergence of tools based on Large Language Models (LLMs), such as OpenAI's ChatGPT, Microsoft's Bing Chat, and Google's Bard, has garnered immense public attention. These incredibly useful, natural-sounding tools mark significant advances in natural language generation, yet they exhibit a propensity to generate false, erroneous, or misleading content -- commonly referred to as "hallucinations." Moreover, LLMs can be exploited for malicious applications, such as generating false but credible-sounding content and profiles at scale. This poses a significant challenge to society in terms of the potential deception of users and the increasing dissemination of inaccurate information. In light of these risks, we explore the kinds of technological innovations, regulatory reforms, and AI literacy initiatives needed from fact-checkers, news organizations, and the broader research and policy communities. By identifying the risks, the imminent threats, and some viable solutions, we seek to shed light on navigating various aspects of veracity in the era of generative AI.
Artificial intelligence is ineffective and potentially harmful for fact checking
Sep 01, 2023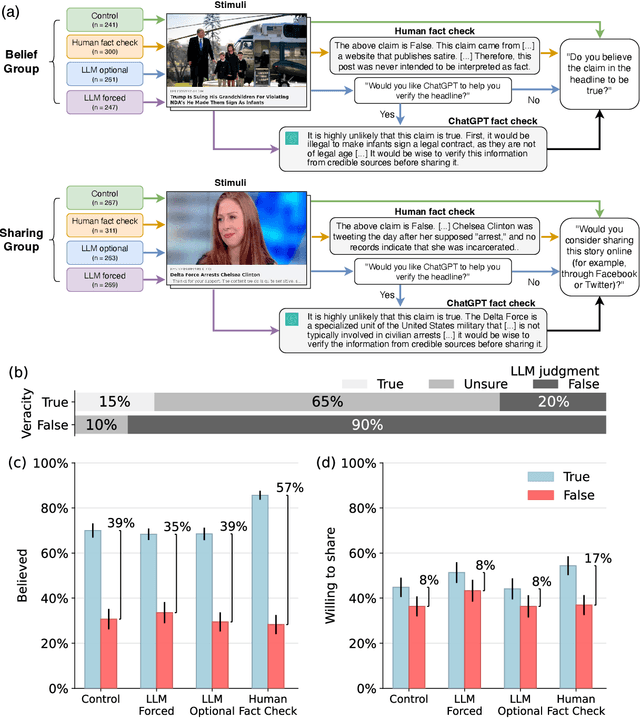
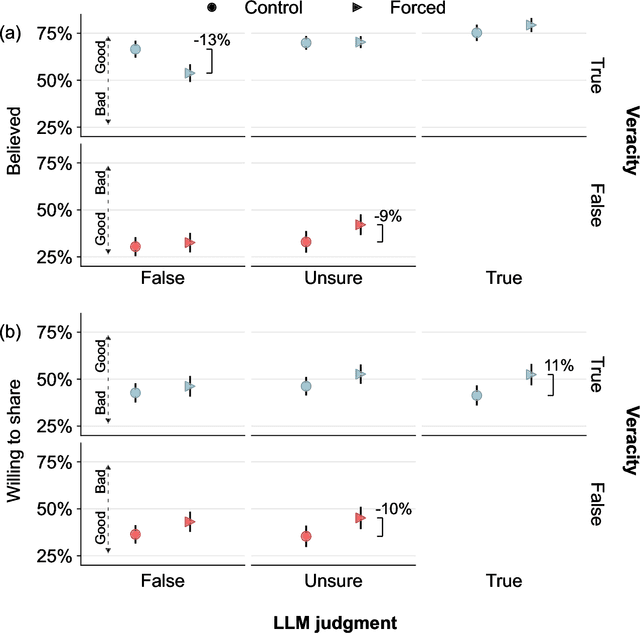
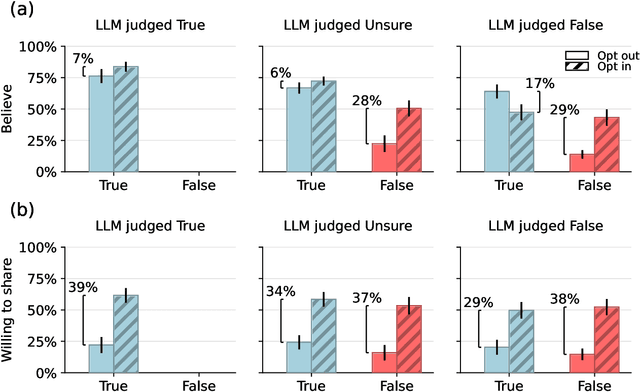
Fact checking can be an effective strategy against misinformation, but its implementation at scale is impeded by the overwhelming volume of information online. Recent artificial intelligence (AI) language models have shown impressive ability in fact-checking tasks, but how humans interact with fact-checking information provided by these models is unclear. Here we investigate the impact of fact checks generated by a popular AI model on belief in, and sharing intent of, political news in a preregistered randomized control experiment. Although the AI performs reasonably well in debunking false headlines, we find that it does not significantly affect participants' ability to discern headline accuracy or share accurate news. However, the AI fact-checker is harmful in specific cases: it decreases beliefs in true headlines that it mislabels as false and increases beliefs for false headlines that it is unsure about. On the positive side, the AI increases sharing intents for correctly labeled true headlines. When participants are given the option to view AI fact checks and choose to do so, they are significantly more likely to share both true and false news but only more likely to believe false news. Our findings highlight an important source of potential harm stemming from AI applications and underscore the critical need for policies to prevent or mitigate such unintended consequences.
Anatomy of an AI-powered malicious social botnet
Jul 30, 2023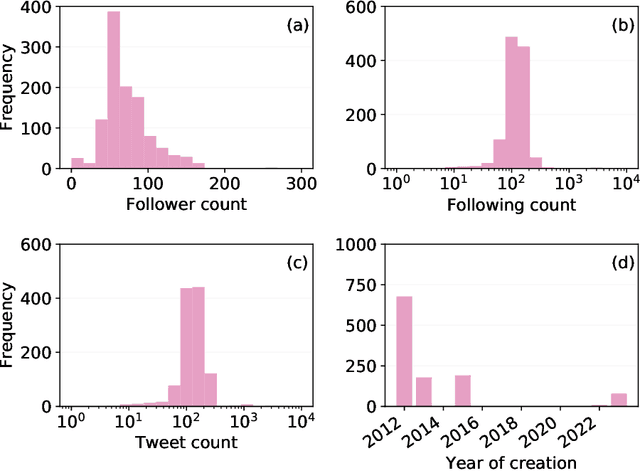

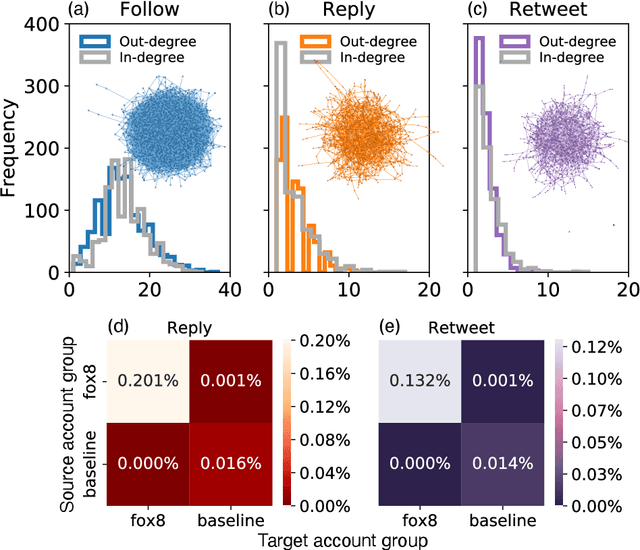
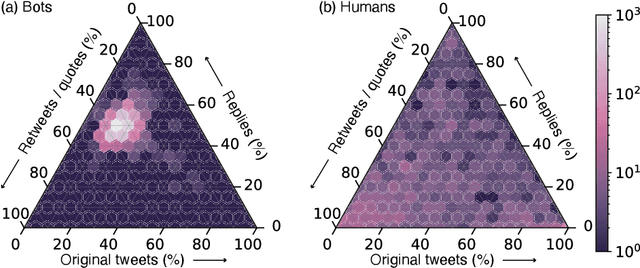
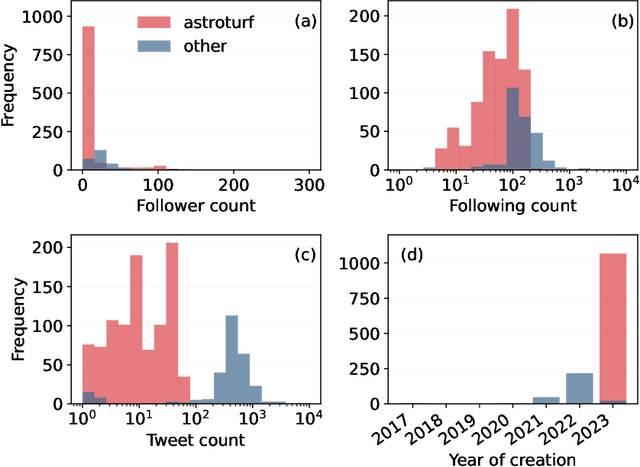
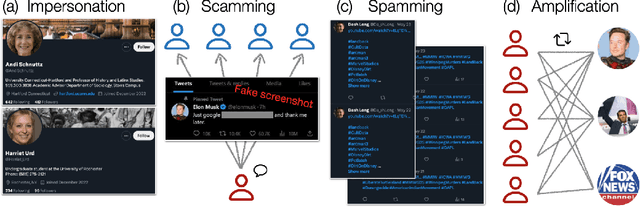
Large language models (LLMs) exhibit impressive capabilities in generating realistic text across diverse subjects. Concerns have been raised that they could be utilized to produce fake content with a deceptive intention, although evidence thus far remains anecdotal. This paper presents a case study about a Twitter botnet that appears to employ ChatGPT to generate human-like content. Through heuristics, we identify 1,140 accounts and validate them via manual annotation. These accounts form a dense cluster of fake personas that exhibit similar behaviors, including posting machine-generated content and stolen images, and engage with each other through replies and retweets. ChatGPT-generated content promotes suspicious websites and spreads harmful comments. While the accounts in the AI botnet can be detected through their coordination patterns, current state-of-the-art LLM content classifiers fail to discriminate between them and human accounts in the wild. These findings highlight the threats posed by AI-enabled social bots.