 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacteristics and prevalence of fake social media profiles with AI-generated faces
Jan 05, 2024

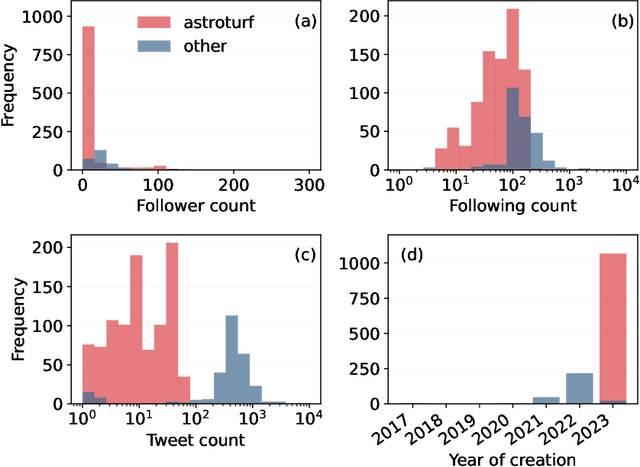
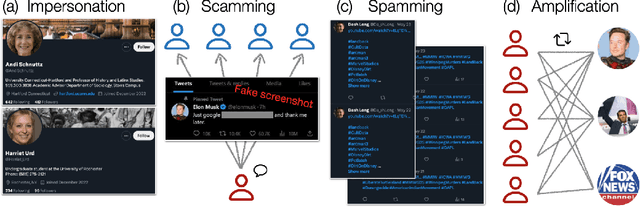
Recent advancements in generative artificial intelligence (AI) have raised concerns about their potential to create convincing fake social media accounts, but empirical evidence is lacking. In this paper, we present a systematic analysis of Twitter(X) accounts using human faces generated by Generative Adversarial Networks (GANs) for their profile pictures. We present a dataset of 1,353 such accounts and show that they are used to spread scams, spam, and amplify coordinated messages, among other inauthentic activities. Leveraging a feature of GAN-generated faces -- consistent eye placement -- and supplementing it with human annotation, we devise an effective method for identifying GAN-generated profiles in the wild. Applying this method to a random sample of active Twitter users, we estimate a lower bound for the prevalence of profiles using GAN-generated faces between 0.021% and 0.044% -- around 10K daily active accounts. These findings underscore the emerging threats posed by multimodal generative AI. We release the source code of our detection method and the data we collect to facilitate further investigation. Additionally, we provide practical heuristics to assist social media users in recognizing such accounts.
Constructing Vec-tionaries to Extract Latent Message Features from Texts: A Case Study of Moral Appeals
Dec 10, 2023While communication research frequently studies latent message features like moral appeals, their quantification remains a challenge. Conventional human coding struggles with scalability and intercoder reliability. While dictionary-based methods are cost-effective and computationally efficient, they often lack contextual sensitivity and are limited by the vocabularies developed for the original applications. In this paper, we present a novel approach to construct vec-tionary measurement tools that boost validated dictionaries with word embeddings through nonlinear optimization. By harnessing semantic relationships encoded by embeddings, vec-tionaries improve the measurement of latent message features by expanding the applicability of original vocabularies to other contexts. Vec-tionaries can also help extract semantic information from texts, especially those in short format, beyond the original vocabulary of a dictionary. Importantly, a vec-tionary can produce additional metrics to capture the valence and ambivalence of a latent feature beyond its strength in texts. Using moral appeals in COVID-19-related tweets as a case study, we illustrate the steps to construct the moral foundations vec-tionary, showcasing its ability to process posts missed by dictionary methods and to produce measurements better aligned with crowdsourced human assessments. Furthermore, additional metrics from the moral foundations vec-tionary unveiled unique insights that facilitated predicting outcomes such as message retransmission.
Artificial intelligence is ineffective and potentially harmful for fact checking
Sep 01, 2023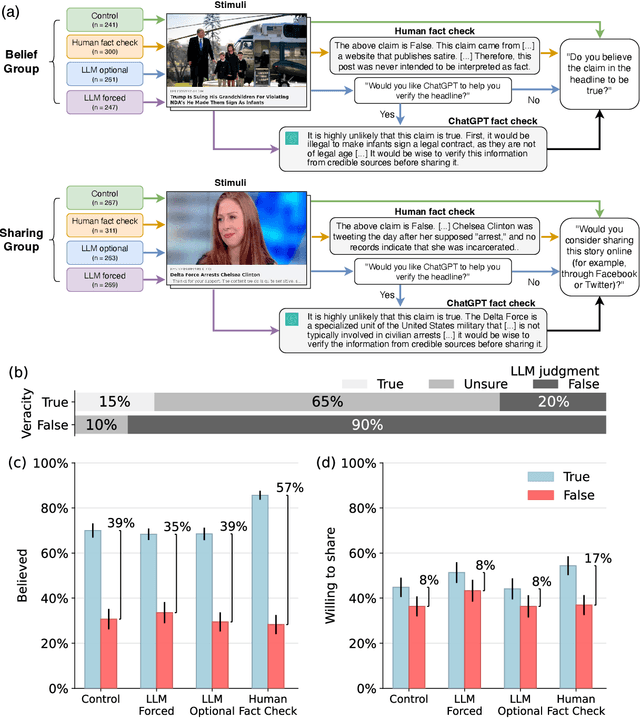
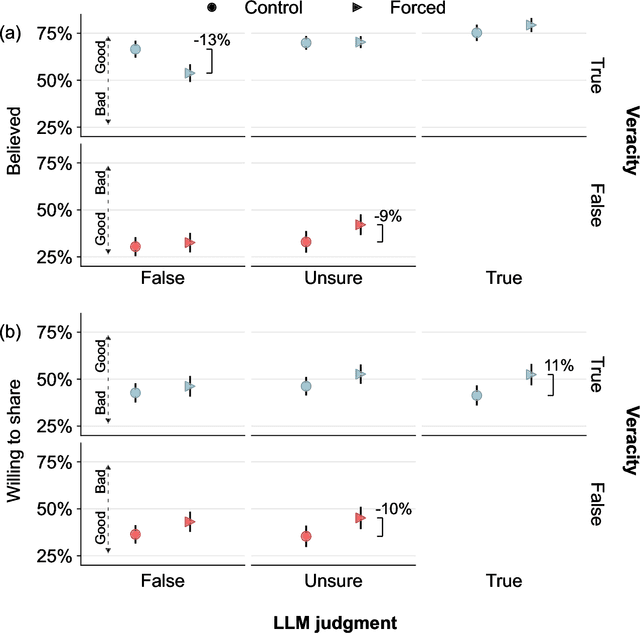
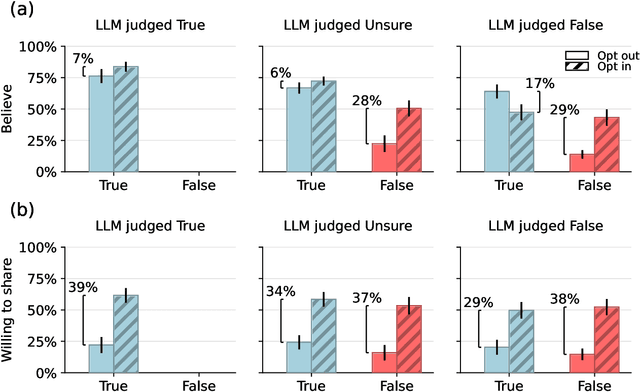
Fact checking can be an effective strategy against misinformation, but its implementation at scale is impeded by the overwhelming volume of information online. Recent artificial intelligence (AI) language models have shown impressive ability in fact-checking tasks, but how humans interact with fact-checking information provided by these models is unclear. Here we investigate the impact of fact checks generated by a popular AI model on belief in, and sharing intent of, political news in a preregistered randomized control experiment. Although the AI performs reasonably well in debunking false headlines, we find that it does not significantly affect participants' ability to discern headline accuracy or share accurate news. However, the AI fact-checker is harmful in specific cases: it decreases beliefs in true headlines that it mislabels as false and increases beliefs for false headlines that it is unsure about. On the positive side, the AI increases sharing intents for correctly labeled true headlines. When participants are given the option to view AI fact checks and choose to do so, they are significantly more likely to share both true and false news but only more likely to believe false news. Our findings highlight an important source of potential harm stemming from AI applications and underscore the critical need for policies to prevent or mitigate such unintended consequences.
Anatomy of an AI-powered malicious social botnet
Jul 30, 2023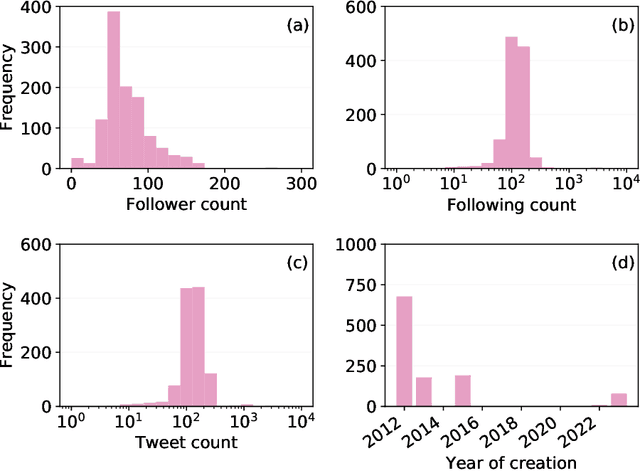

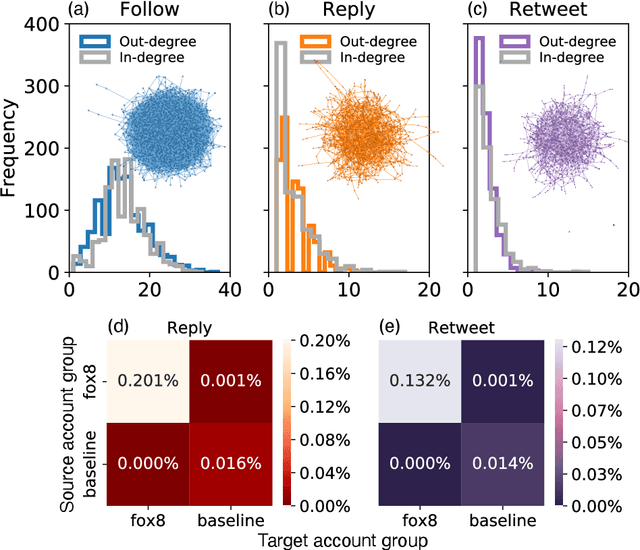
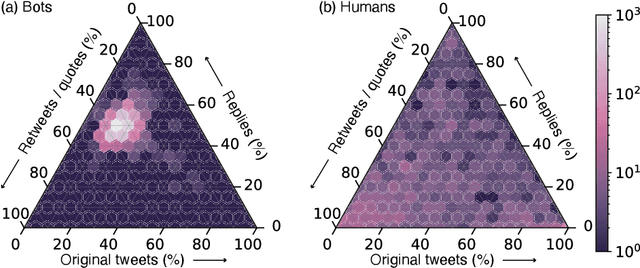
Large language models (LLMs) exhibit impressive capabilities in generating realistic text across diverse subjects. Concerns have been raised that they could be utilized to produce fake content with a deceptive intention, although evidence thus far remains anecdotal. This paper presents a case study about a Twitter botnet that appears to employ ChatGPT to generate human-like content. Through heuristics, we identify 1,140 accounts and validate them via manual annotation. These accounts form a dense cluster of fake personas that exhibit similar behaviors, including posting machine-generated content and stolen images, and engage with each other through replies and retweets. ChatGPT-generated content promotes suspicious websites and spreads harmful comments. While the accounts in the AI botnet can be detected through their coordination patterns, current state-of-the-art LLM content classifiers fail to discriminate between them and human accounts in the wild. These findings highlight the threats posed by AI-enabled social bots.
Large language models can rate news outlet credibility
Apr 01, 2023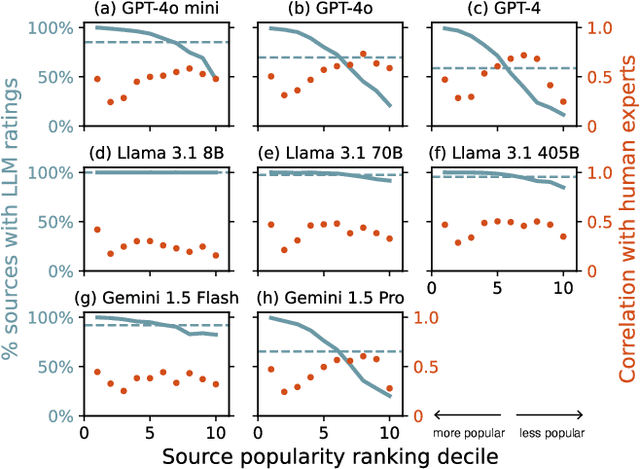
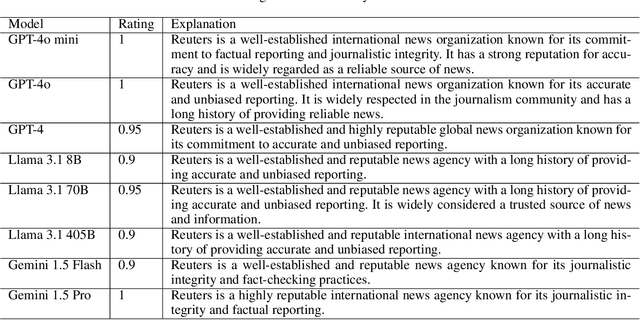
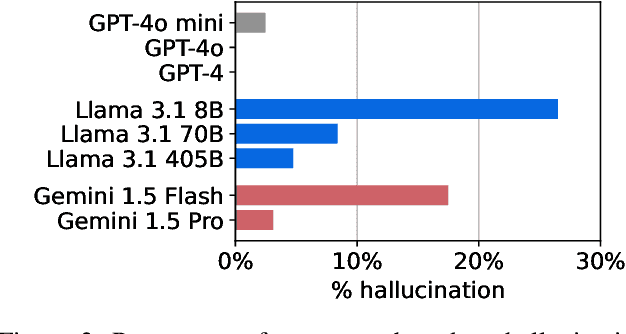

Although large language models (LLMs) have shown exceptional performance in various natural language processing tasks, they are prone to hallucinations. State-of-the-art chatbots, such as the new Bing, attempt to mitigate this issue by gathering information directly from the internet to ground their answers. In this setting, the capacity to distinguish trustworthy sources is critical for providing appropriate accuracy contexts to users. Here we assess whether ChatGPT, a prominent LLM, can evaluate the credibility of news outlets. With appropriate instructions, ChatGPT can provide ratings for a diverse set of news outlets, including those in non-English languages and satirical sources, along with contextual explanations. Our results show that these ratings correlate with those from human experts (Spearmam's $\rho=0.54, p<0.001$). These findings suggest that LLMs could be an affordable reference for credibility ratings in fact-checking applications. Future LLMs should enhance their alignment with human expert judgments of source credibility to improve information accuracy.
Detection of Novel Social Bots by Ensembles of Specialized Classifiers
Jun 11, 2020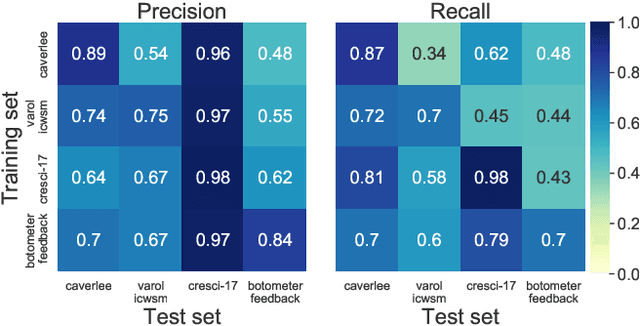
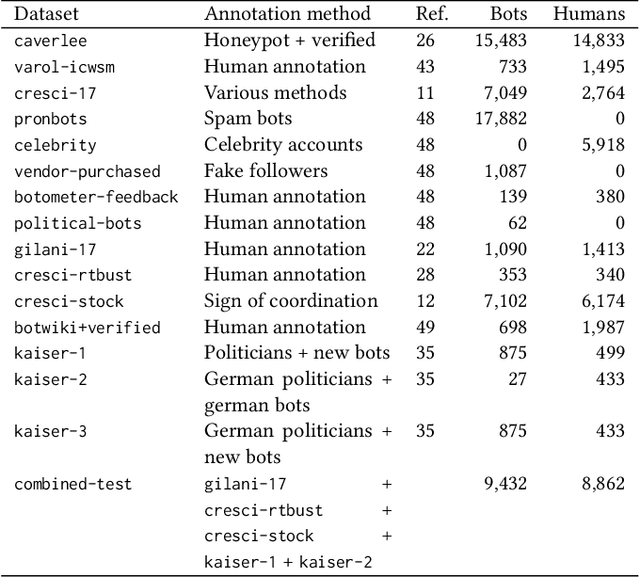
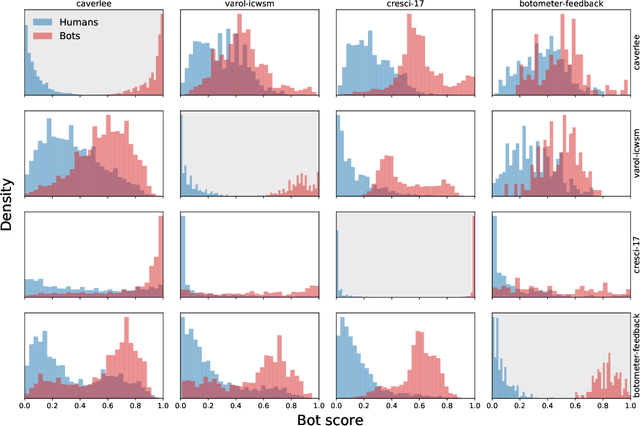

Malicious actors create inauthentic social media accounts controlled in part by algorithms, known as social bots, to disseminate misinformation and agitate online discussion. While researchers have developed sophisticated methods to detect abuse, novel bots with diverse behaviors evade detection. We show that different types of bots are characterized by different behavioral features. As a result, commonly used supervised learning techniques suffer severe performance deterioration when attempting to detect behaviors not observed in the training data. Moreover, tuning these models to recognize novel bots requires retraining with a significant amount of new annotations, which are expensive to obtain. To address these issues, we propose a new supervised learning method that trains classifiers specialized for each class of bots and combines their decisions through the maximum rule. The ensemble of specialized classifiers (ESC) can better generalize, leading to an average improvement of 56% in F1 score for unseen accounts across datasets. Furthermore, novel bot behaviors are learned with fewer labeled examples during retraining. We are deploying ESC in the newest version of Botometer, a popular tool to detect social bots in the wild.
Persona2vec: A Flexible Multi-role Representations Learning Framework for Graphs
Jun 04, 2020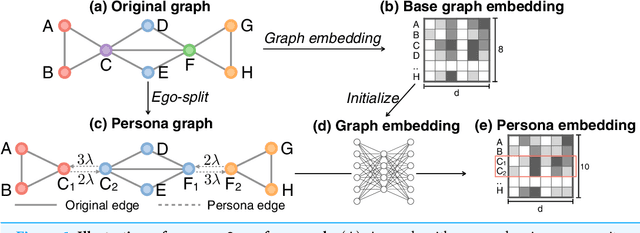
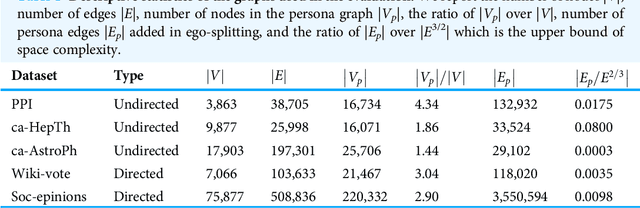
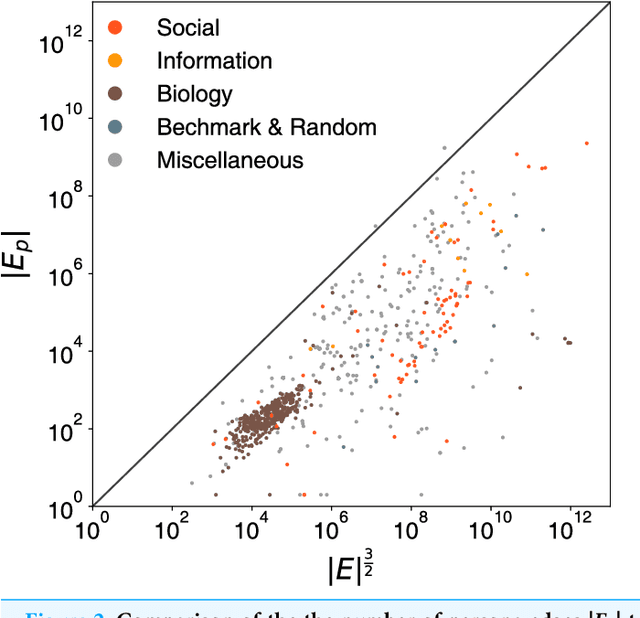
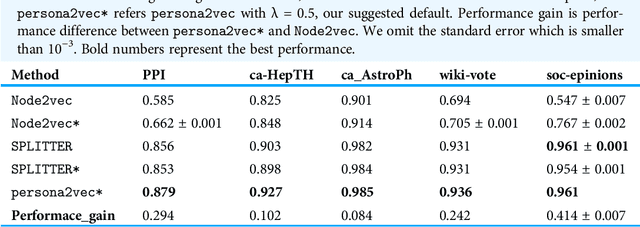
Graph embedding techniques, which learn low-dimensional representations of a graph, are achieving state-of-the-art performance in many graph mining tasks. Most existing embedding algorithms assign a single vector to each node, implicitly assuming that a single representation is enough to capture all characteristics of the node. However, across many domains, it is common to observe pervasively overlapping community structure, where most nodes belong to multiple communities, playing different roles depending on the contexts. Here, we propose persona2vec, a graph embedding framework that efficiently learns multiple representations of nodes based on their structural contexts. Using link prediction-based evaluation, we show that our framework is significantly faster than the existing state-of-the-art model while achieving better performance. Graph embedding techniques, which learn low-dimensional representations of a graph, are achieving state-of-the-art performance in many graph mining tasks. Most existing embedding algorithms assign a single vector to each node, implicitly assuming that a single representation is enough to capture all characteristics of the node. However, across many domains, it is common to observe pervasively overlapping community structure, where most nodes belong to multiple communities, playing different roles depending on the contexts. Here, we propose persona2vec, a graph embedding framework that efficiently learns multiple representations of nodes based on their structural contexts. Using link prediction-based evaluation, we show that our framework is significantly faster than the existing state-of-the-art model while achieving better performance.
Scalable and Generalizable Social Bot Detection through Data Selection
Nov 20, 2019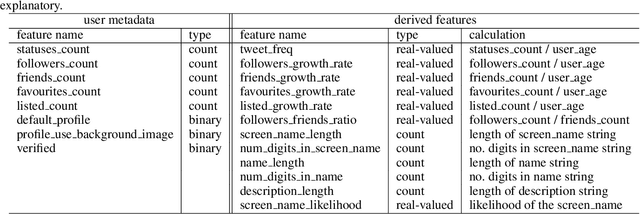
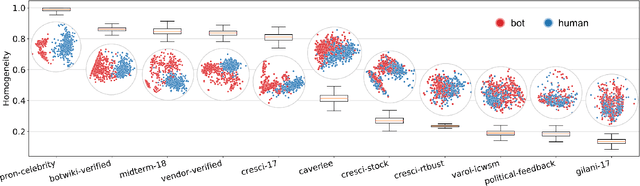
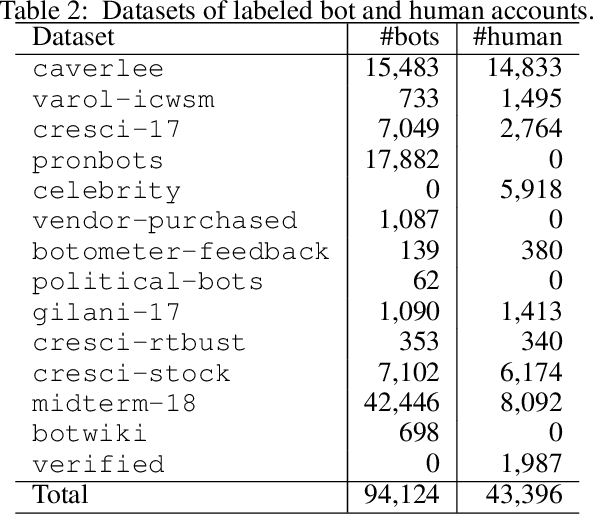
Efficient and reliable social bot classification is crucial for detecting information manipulation on social media. Despite rapid development, state-of-the-art bot detection models still face generalization and scalability challenges, which greatly limit their applications. In this paper we propose a framework that uses minimal account metadata, enabling efficient analysis that scales up to handle the full stream of public tweets of Twitter in real time. To ensure model accuracy, we build a rich collection of labeled datasets for training and validation. We deploy a strict validation system so that model performance on unseen datasets is also optimized, in addition to traditional cross-validation. We find that strategically selecting a subset of training data yields better model accuracy and generalization than exhaustively training on all available data. Thanks to the simplicity of the proposed model, its logic can be interpreted to provide insights into social bot characteristics.