 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Reasoning to Generative Recommendation Through the Lens of Cascaded Ranking
Feb 03, 2026Generative Recommendation (GR) has become a promising end-to-end approach with high FLOPS utilization for resource-efficient recommendation. Despite the effectiveness, we show that current GR models suffer from a critical \textbf{bias amplification} issue, where token-level bias escalates as token generation progresses, ultimately limiting the recommendation diversity and hurting the user experience. By comparing against the key factor behind the success of traditional multi-stage pipelines, we reveal two limitations in GR that can amplify the bias: homogeneous reliance on the encoded history, and fixed computational budgets that prevent deeper user preference understanding. To combat the bias amplification issue, it is crucial for GR to 1) incorporate more heterogeneous information, and 2) allocate greater computational resources at each token generation step. To this end, we propose CARE, a simple yet effective cascaded reasoning framework for debiased GR. To incorporate heterogeneous information, we introduce a progressive history encoding mechanism, which progressively incorporates increasingly fine-grained history information as the generation process advances. To allocate more computations, we propose a query-anchored reasoning mechanism, which seeks to perform a deeper understanding of historical information through parallel reasoning steps. We instantiate CARE on three GR backbones. Empirical results on four datasets show the superiority of CARE in recommendation accuracy, diversity, efficiency, and promising scalability. The codes and datasets are available at https://github.com/Linxyhaha/CARE.
Nested ResNet: A Vision-Based Method for Detecting the Sensing Area of a Drop-in Gamma Probe
Oct 30, 2024

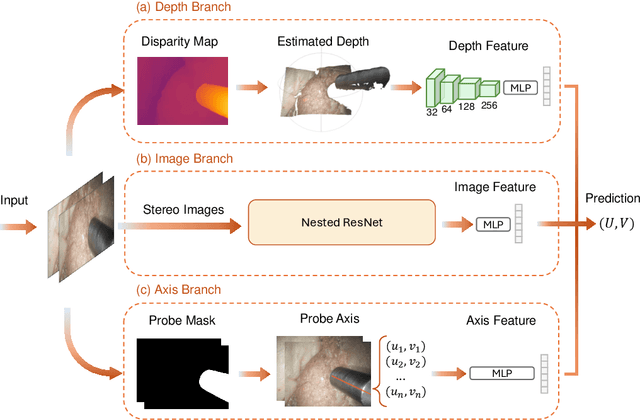
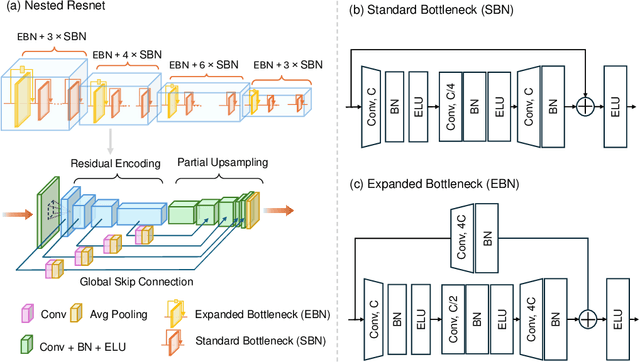
Purpose: Drop-in gamma probes are widely used in robotic-assisted minimally invasive surgery (RAMIS) for lymph node detection. However, these devices only provide audio feedback on signal intensity, lacking the visual feedback necessary for precise localisation. Previous work attempted to predict the sensing area location using laparoscopic images, but the prediction accuracy was unsatisfactory. Improvements are needed in the deep learning-based regression approach. Methods: We introduce a three-branch deep learning framework to predict the sensing area of the probe. Specifically, we utilise the stereo laparoscopic images as input for the main branch and develop a Nested ResNet architecture. The framework also incorporates depth estimation via transfer learning and orientation guidance through probe axis sampling. The combined features from each branch enhanced the accuracy of the prediction. Results: Our approach has been evaluated on a publicly available dataset, demonstrating superior performance over previous methods. In particular, our method resulted in a 22.10\% decrease in 2D mean error and a 41.67\% reduction in 3D mean error. Additionally, qualitative comparisons further demonstrated the improved precision of our approach. Conclusion: With extensive evaluation, our solution significantly enhances the accuracy and reliability of sensing area predictions. This advancement enables visual feedback during the use of the drop-in gamma probe in surgery, providing surgeons with more accurate and reliable localisation.}
Constructing Vec-tionaries to Extract Latent Message Features from Texts: A Case Study of Moral Appeals
Dec 10, 2023While communication research frequently studies latent message features like moral appeals, their quantification remains a challenge. Conventional human coding struggles with scalability and intercoder reliability. While dictionary-based methods are cost-effective and computationally efficient, they often lack contextual sensitivity and are limited by the vocabularies developed for the original applications. In this paper, we present a novel approach to construct vec-tionary measurement tools that boost validated dictionaries with word embeddings through nonlinear optimization. By harnessing semantic relationships encoded by embeddings, vec-tionaries improve the measurement of latent message features by expanding the applicability of original vocabularies to other contexts. Vec-tionaries can also help extract semantic information from texts, especially those in short format, beyond the original vocabulary of a dictionary. Importantly, a vec-tionary can produce additional metrics to capture the valence and ambivalence of a latent feature beyond its strength in texts. Using moral appeals in COVID-19-related tweets as a case study, we illustrate the steps to construct the moral foundations vec-tionary, showcasing its ability to process posts missed by dictionary methods and to produce measurements better aligned with crowdsourced human assessments. Furthermore, additional metrics from the moral foundations vec-tionary unveiled unique insights that facilitated predicting outcomes such as message retransmission.
Detecting the Sensing Area of A Laparoscopic Probe in Minimally Invasive Cancer Surgery
Jul 07, 2023



In surgical oncology, it is challenging for surgeons to identify lymph nodes and completely resect cancer even with pre-operative imaging systems like PET and CT, because of the lack of reliable intraoperative visualization tools. Endoscopic radio-guided cancer detection and resection has recently been evaluated whereby a novel tethered laparoscopic gamma detector is used to localize a preoperatively injected radiotracer. This can both enhance the endoscopic imaging and complement preoperative nuclear imaging data. However, gamma activity visualization is challenging to present to the operator because the probe is non-imaging and it does not visibly indicate the activity origination on the tissue surface. Initial failed attempts used segmentation or geometric methods, but led to the discovery that it could be resolved by leveraging high-dimensional image features and probe position information. To demonstrate the effectiveness of this solution, we designed and implemented a simple regression network that successfully addressed the problem. To further validate the proposed solution, we acquired and publicly released two datasets captured using a custom-designed, portable stereo laparoscope system. Through intensive experimentation, we demonstrated that our method can successfully and effectively detect the sensing area, establishing a new performance benchmark. Code and data are available at https://github.com/br0202/Sensing_area_detection.git
SyntheX: Scaling Up Learning-based X-ray Image Analysis Through In Silico Experiments
Jun 13, 2022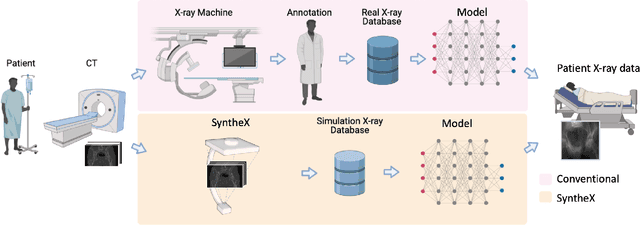

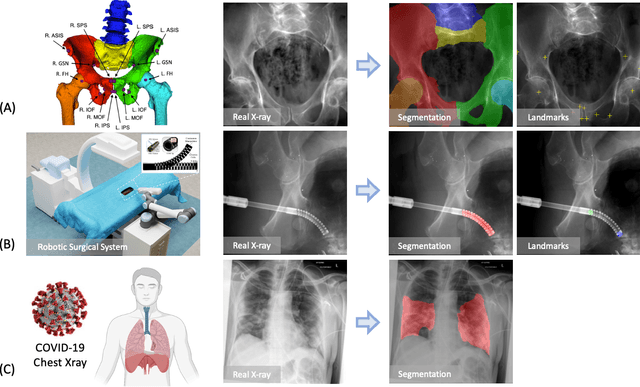

Artificial intelligence (AI) now enables automated interpretation of medical images for clinical use. However, AI's potential use for interventional images (versus those involved in triage or diagnosis), such as for guidance during surgery, remains largely untapped. This is because surgical AI systems are currently trained using post hoc analysis of data collected during live surgeries, which has fundamental and practical limitations, including ethical considerations, expense, scalability, data integrity, and a lack of ground truth. Here, we demonstrate that creating realistic simulated images from human models is a viable alternative and complement to large-scale in situ data collection. We show that training AI image analysis models on realistically synthesized data, combined with contemporary domain generalization or adaptation techniques, results in models that on real data perform comparably to models trained on a precisely matched real data training set. Because synthetic generation of training data from human-based models scales easily, we find that our model transfer paradigm for X-ray image analysis, which we refer to as SyntheX, can even outperform real data-trained models due to the effectiveness of training on a larger dataset. We demonstrate the potential of SyntheX on three clinical tasks: Hip image analysis, surgical robotic tool detection, and COVID-19 lung lesion segmentation. SyntheX provides an opportunity to drastically accelerate the conception, design, and evaluation of intelligent systems for X-ray-based medicine. In addition, simulated image environments provide the opportunity to test novel instrumentation, design complementary surgical approaches, and envision novel techniques that improve outcomes, save time, or mitigate human error, freed from the ethical and practical considerations of live human data collection.
The Impact of Machine Learning on 2D/3D Registration for Image-guided Interventions: A Systematic Review and Perspective
Aug 04, 2021
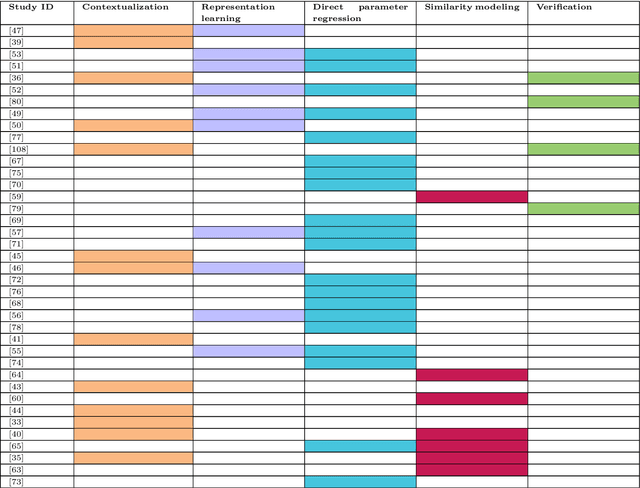

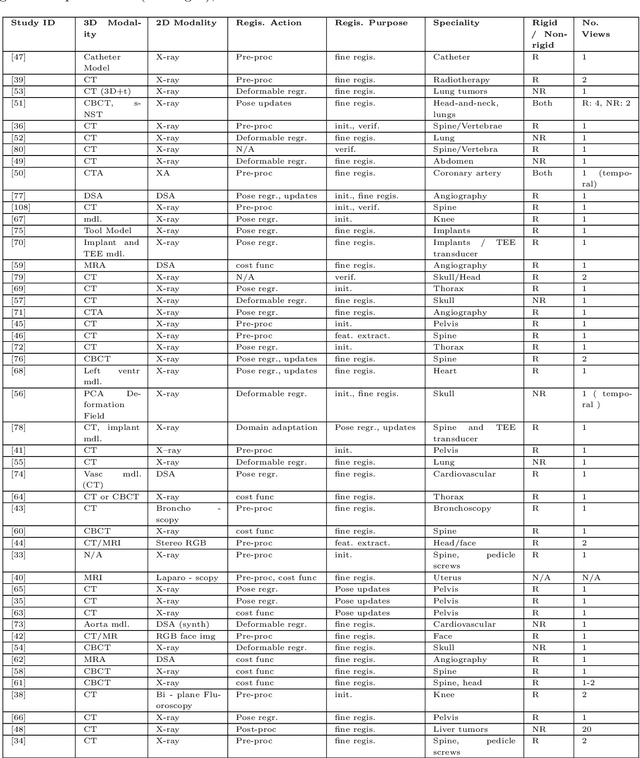
Image-based navigation is widely considered the next frontier of minimally invasive surgery. It is believed that image-based navigation will increase the access to reproducible, safe, and high-precision surgery as it may then be performed at acceptable costs and effort. This is because image-based techniques avoid the need of specialized equipment and seamlessly integrate with contemporary workflows. Further, it is expected that image-based navigation will play a major role in enabling mixed reality environments and autonomous, robotic workflows. A critical component of image guidance is 2D/3D registration, a technique to estimate the spatial relationships between 3D structures, e.g., volumetric imagery or tool models, and 2D images thereof, such as fluoroscopy or endoscopy. While image-based 2D/3D registration is a mature technique, its transition from the bench to the bedside has been restrained by well-known challenges, including brittleness of the optimization objective, hyperparameter selection, and initialization, difficulties around inconsistencies or multiple objects, and limited single-view performance. One reason these challenges persist today is that analytical solutions are likely inadequate considering the complexity, variability, and high-dimensionality of generic 2D/3D registration problems. The recent advent of machine learning-based approaches to imaging problems that, rather than specifying the desired functional mapping, approximate it using highly expressive parametric models holds promise for solving some of the notorious challenges in 2D/3D registration. In this manuscript, we review the impact of machine learning on 2D/3D registration to systematically summarize the recent advances made by introduction of this novel technology. Grounded in these insights, we then offer our perspective on the most pressing needs, significant open problems, and possible next steps.