 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMP-HDRL: Segmented Allocation with Momentum-Adjusted Utility for Multi-agent Portfolio Management via Hierarchical Deep Reinforcement Learning
Dec 28, 2025Portfolio optimization in non-stationary markets is challenging due to regime shifts, dynamic correlations, and the limited interpretability of deep reinforcement learning (DRL) policies. We propose a Segmented Allocation with Momentum-Adjusted Utility for Multi-agent Portfolio Management via Hierarchical Deep Reinforcement Learning (SAMP-HDRL). The framework first applies dynamic asset grouping to partition the market into high-quality and ordinary subsets. An upper-level agent extracts global market signals, while lower-level agents perform intra-group allocation under mask constraints. A utility-based capital allocation mechanism integrates risky and risk-free assets, ensuring coherent coordination between global and local decisions. backtests across three market regimes (2019--2021) demonstrate that SAMP-HDRL consistently outperforms nine traditional baselines and nine DRL benchmarks under volatile and oscillating conditions. Compared with the strongest baseline, our method achieves at least 5\% higher Return, 5\% higher Sharpe ratio, 5\% higher Sortino ratio, and 2\% higher Omega ratio, with substantially larger gains observed in turbulent markets. Ablation studies confirm that upper--lower coordination, dynamic clustering, and capital allocation are indispensable to robustness. SHAP-based interpretability further reveals a complementary ``diversified + concentrated'' mechanism across agents, providing transparent insights into decision-making. Overall, SAMP-HDRL embeds structural market constraints directly into the DRL pipeline, offering improved adaptability, robustness, and interpretability in complex financial environments.
PRISM: A Personality-Driven Multi-Agent Framework for Social Media Simulation
Dec 22, 2025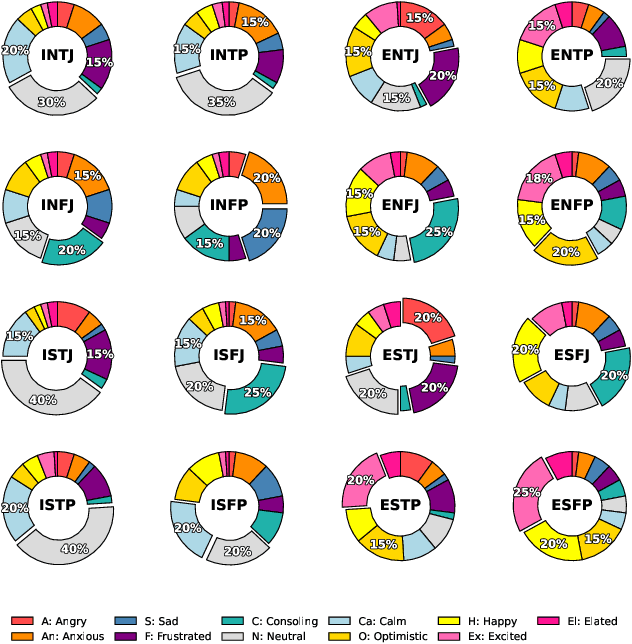
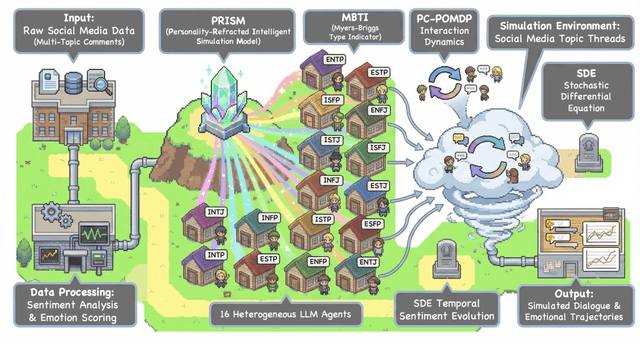
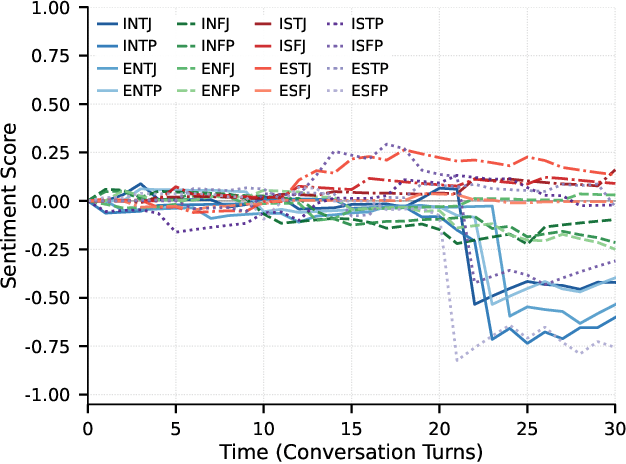

Traditional agent-based models (ABMs) of opinion dynamics often fail to capture the psychological heterogeneity driving online polarization due to simplistic homogeneity assumptions. This limitation obscures the critical interplay between individual cognitive biases and information propagation, thereby hindering a mechanistic understanding of how ideological divides are amplified. To address this challenge, we introduce the Personality-Refracted Intelligent Simulation Model (PRISM), a hybrid framework coupling stochastic differential equations (SDE) for continuous emotional evolution with a personality-conditional partially observable Markov decision process (PC-POMDP) for discrete decision-making. In contrast to continuous trait approaches, PRISM assigns distinct Myers-Briggs Type Indicator (MBTI) based cognitive policies to multimodal large language model (MLLM) agents, initialized via data-driven priors from large-scale social media datasets. PRISM achieves superior personality consistency aligned with human ground truth, significantly outperforming standard homogeneous and Big Five benchmarks. This framework effectively replicates emergent phenomena such as rational suppression and affective resonance, offering a robust tool for analyzing complex social media ecosystems.
ArchMap: Arch-Flattening and Knowledge-Guided Vision Language Model for Tooth Counting and Structured Dental Understanding
Nov 18, 2025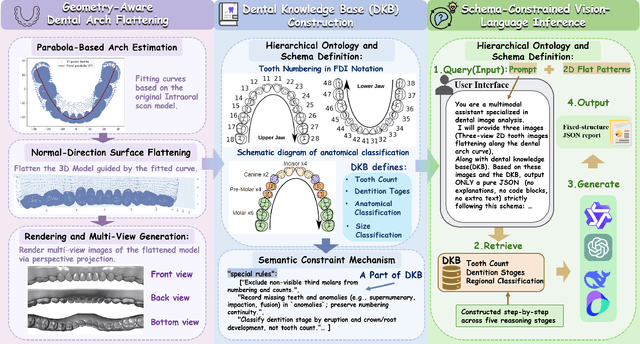
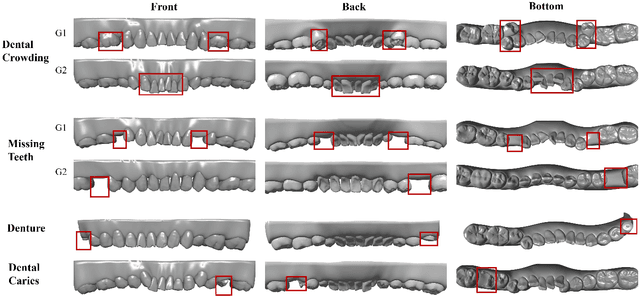
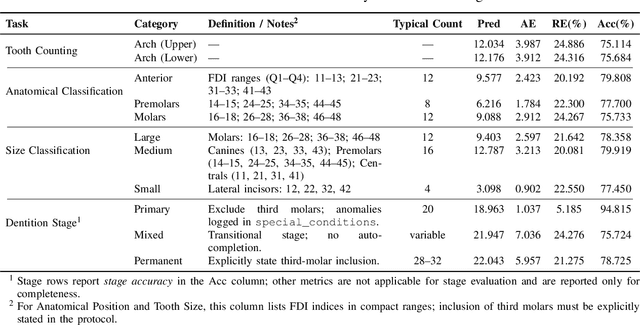
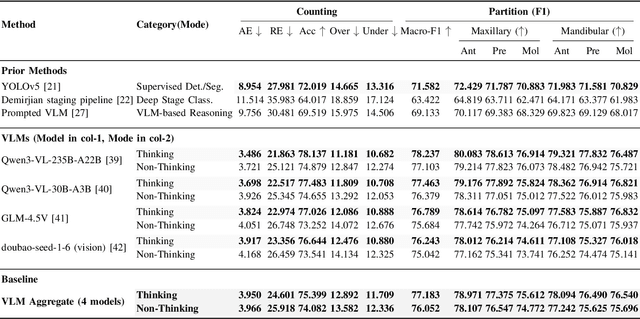
A structured understanding of intraoral 3D scans is essential for digital orthodontics. However, existing deep-learning approaches rely heavily on modality-specific training, large annotated datasets, and controlled scanning conditions, which limit generalization across devices and hinder deployment in real clinical workflows. Moreover, raw intraoral meshes exhibit substantial variation in arch pose, incomplete geometry caused by occlusion or tooth contact, and a lack of texture cues, making unified semantic interpretation highly challenging. To address these limitations, we propose ArchMap, a training-free and knowledge-guided framework for robust structured dental understanding. ArchMap first introduces a geometry-aware arch-flattening module that standardizes raw 3D meshes into spatially aligned, continuity-preserving multi-view projections. We then construct a Dental Knowledge Base (DKB) encoding hierarchical tooth ontology, dentition-stage policies, and clinical semantics to constrain the symbolic reasoning space. We validate ArchMap on 1060 pre-/post-orthodontic cases, demonstrating robust performance in tooth counting, anatomical partitioning, dentition-stage classification, and the identification of clinical conditions such as crowding, missing teeth, prosthetics, and caries. Compared with supervised pipelines and prompted VLM baselines, ArchMap achieves higher accuracy, reduced semantic drift, and superior stability under sparse or artifact-prone conditions. As a fully training-free system, ArchMap demonstrates that combining geometric normalization with ontology-guided multimodal reasoning offers a practical and scalable solution for the structured analysis of 3D intraoral scans in modern digital orthodontics.
Silhouette-to-Contour Registration: Aligning Intraoral Scan Models with Cephalometric Radiographs
Nov 18, 2025Reliable 3D-2D alignment between intraoral scan (IOS) models and lateral cephalometric radiographs is critical for orthodontic diagnosis, yet conventional intensity-driven registration methods struggle under real clinical conditions, where cephalograms exhibit projective magnification, geometric distortion, low-contrast dental crowns, and acquisition-dependent variation. These factors hinder the stability of appearance-based similarity metrics and often lead to convergence failures or anatomically implausible alignments. To address these limitations, we propose DentalSCR, a pose-stable, contour-guided framework for accurate and interpretable silhouette-to-contour registration. Our method first constructs a U-Midline Dental Axis (UMDA) to establish a unified cross-arch anatomical coordinate system, thereby stabilizing initialization and standardizing projection geometry across cases. Using this reference frame, we generate radiograph-like projections via a surface-based DRR formulation with coronal-axis perspective and Gaussian splatting, which preserves clinical source-object-detector magnification and emphasizes external silhouettes. Registration is then formulated as a 2D similarity transform optimized with a symmetric bidirectional Chamfer distance under a hierarchical coarse-to-fine schedule, enabling both large capture range and subpixel-level contour agreement. We evaluate DentalSCR on 34 expert-annotated clinical cases. Experimental results demonstrate substantial reductions in landmark error-particularly at posterior teeth-tighter dispersion on the lower jaw, and low Chamfer and controlled Hausdorff distances at the curve level. These findings indicate that DentalSCR robustly handles real-world cephalograms and delivers high-fidelity, clinically inspectable 3D--2D alignment, outperforming conventional baselines.
Dental3R: Geometry-Aware Pairing for Intraoral 3D Reconstruction from Sparse-View Photographs
Nov 18, 2025Intraoral 3D reconstruction is fundamental to digital orthodontics, yet conventional methods like intraoral scanning are inaccessible for remote tele-orthodontics, which typically relies on sparse smartphone imagery. While 3D Gaussian Splatting (3DGS) shows promise for novel view synthesis, its application to the standard clinical triad of unposed anterior and bilateral buccal photographs is challenging. The large view baselines, inconsistent illumination, and specular surfaces common in intraoral settings can destabilize simultaneous pose and geometry estimation. Furthermore, sparse-view photometric supervision often induces a frequency bias, leading to over-smoothed reconstructions that lose critical diagnostic details. To address these limitations, we propose \textbf{Dental3R}, a pose-free, graph-guided pipeline for robust, high-fidelity reconstruction from sparse intraoral photographs. Our method first constructs a Geometry-Aware Pairing Strategy (GAPS) to intelligently select a compact subgraph of high-value image pairs. The GAPS focuses on correspondence matching, thereby improving the stability of the geometry initialization and reducing memory usage. Building on the recovered poses and point cloud, we train the 3DGS model with a wavelet-regularized objective. By enforcing band-limited fidelity using a discrete wavelet transform, our approach preserves fine enamel boundaries and interproximal edges while suppressing high-frequency artifacts. We validate our approach on a large-scale dataset of 950 clinical cases and an additional video-based test set of 195 cases. Experimental results demonstrate that Dental3R effectively handles sparse, unposed inputs and achieves superior novel view synthesis quality for dental occlusion visualization, outperforming state-of-the-art methods.
EndoFlow-SLAM: Real-Time Endoscopic SLAM with Flow-Constrained Gaussian Splatting
Jun 26, 2025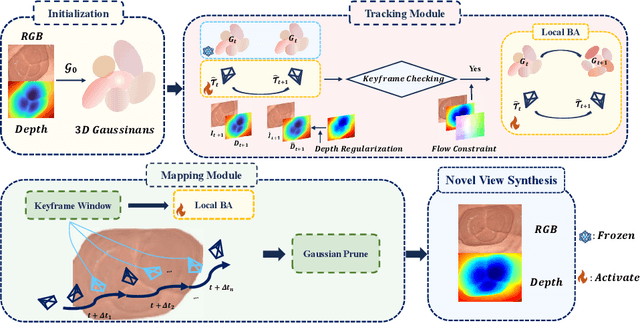
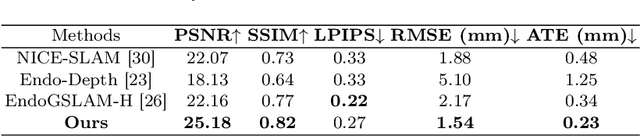
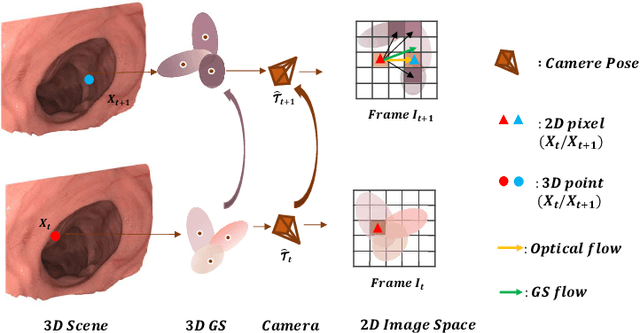
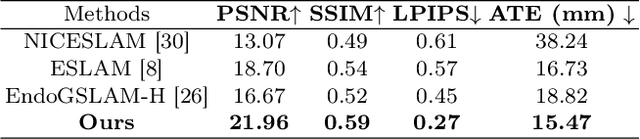
Efficient three-dimensional reconstruction and real-time visualization are critical in surgical scenarios such as endoscopy. In recent years, 3D Gaussian Splatting (3DGS) has demonstrated remarkable performance in efficient 3D reconstruction and rendering. Most 3DGS-based Simultaneous Localization and Mapping (SLAM) methods only rely on the appearance constraints for optimizing both 3DGS and camera poses. However, in endoscopic scenarios, the challenges include photometric inconsistencies caused by non-Lambertian surfaces and dynamic motion from breathing affects the performance of SLAM systems. To address these issues, we additionally introduce optical flow loss as a geometric constraint, which effectively constrains both the 3D structure of the scene and the camera motion. Furthermore, we propose a depth regularisation strategy to mitigate the problem of photometric inconsistencies and ensure the validity of 3DGS depth rendering in endoscopic scenes. In addition, to improve scene representation in the SLAM system, we improve the 3DGS refinement strategy by focusing on viewpoints corresponding to Keyframes with suboptimal rendering quality frames, achieving better rendering results. Extensive experiments on the C3VD static dataset and the StereoMIS dynamic dataset demonstrate that our method outperforms existing state-of-the-art methods in novel view synthesis and pose estimation, exhibiting high performance in both static and dynamic surgical scenes. The source code will be publicly available upon paper acceptance.
Seeing Far and Clearly: Mitigating Hallucinations in MLLMs with Attention Causal Decoding
May 22, 2025Recent advancements in multimodal large language models (MLLMs) have significantly improved performance in visual question answering. However, they often suffer from hallucinations. In this work, hallucinations are categorized into two main types: initial hallucinations and snowball hallucinations. We argue that adequate contextual information can be extracted directly from the token interaction process. Inspired by causal inference in the decoding strategy, we propose to leverage causal masks to establish information propagation between multimodal tokens. The hypothesis is that insufficient interaction between those tokens may lead the model to rely on outlier tokens, overlooking dense and rich contextual cues. Therefore, we propose to intervene in the propagation process by tackling outlier tokens to enhance in-context inference. With this goal, we present FarSight, a versatile plug-and-play decoding strategy to reduce attention interference from outlier tokens merely by optimizing the causal mask. The heart of our method is effective token propagation. We design an attention register structure within the upper triangular matrix of the causal mask, dynamically allocating attention to capture attention diverted to outlier tokens. Moreover, a positional awareness encoding method with a diminishing masking rate is proposed, allowing the model to attend to further preceding tokens, especially for video sequence tasks. With extensive experiments, FarSight demonstrates significant hallucination-mitigating performance across different MLLMs on both image and video benchmarks, proving its effectiveness.
Rhythm of Opinion: A Hawkes-Graph Framework for Dynamic Propagation Analysis
Apr 21, 2025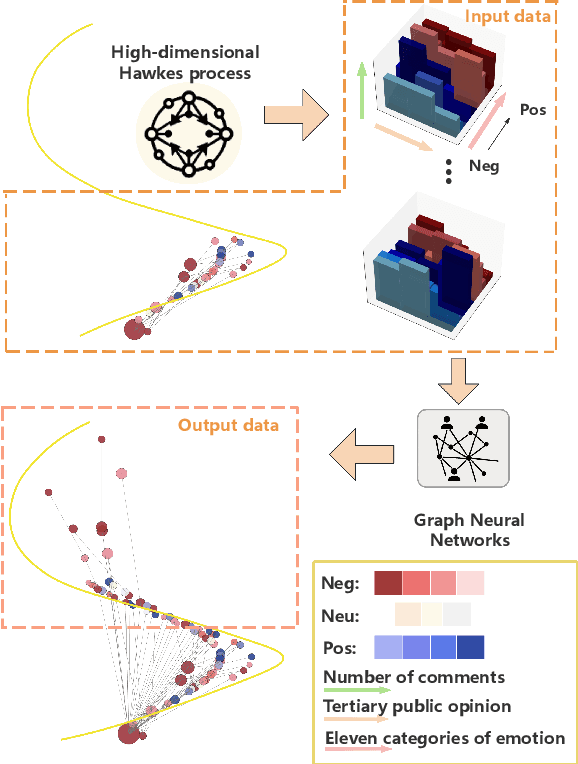
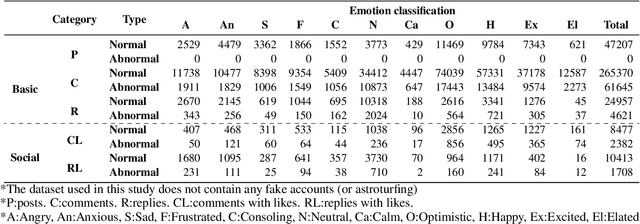
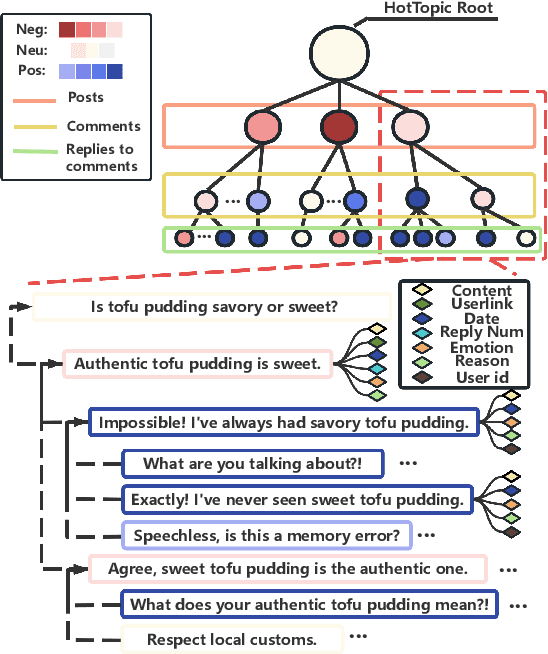
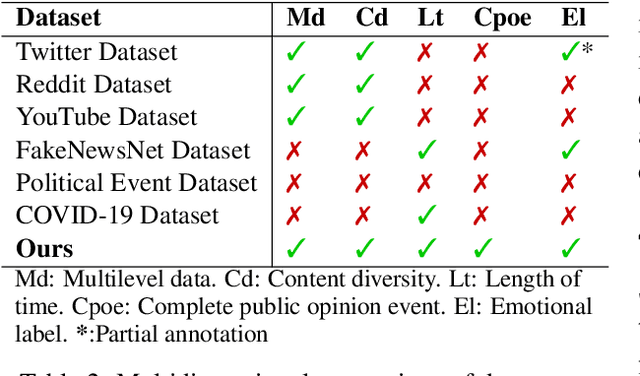
The rapid development of social media has significantly reshaped the dynamics of public opinion, resulting in complex interactions that traditional models fail to effectively capture. To address this challenge, we propose an innovative approach that integrates multi-dimensional Hawkes processes with Graph Neural Network, modeling opinion propagation dynamics among nodes in a social network while considering the intricate hierarchical relationships between comments. The extended multi-dimensional Hawkes process captures the hierarchical structure, multi-dimensional interactions, and mutual influences across different topics, forming a complex propagation network. Moreover, recognizing the lack of high-quality datasets capable of comprehensively capturing the evolution of public opinion dynamics, we introduce a new dataset, VISTA. It includes 159 trending topics, corresponding to 47,207 posts, 327,015 second-level comments, and 29,578 third-level comments, covering diverse domains such as politics, entertainment, sports, health, and medicine. The dataset is annotated with detailed sentiment labels across 11 categories and clearly defined hierarchical relationships. When combined with our method, it offers strong interpretability by linking sentiment propagation to the comment hierarchy and temporal evolution. Our approach provides a robust baseline for future research.
MMformer with Adaptive Transferable Attention: Advancing Multivariate Time Series Forecasting for Environmental Applications
Apr 18, 2025



Environmental crisis remains a global challenge that affects public health and environmental quality. Despite extensive research, accurately forecasting environmental change trends to inform targeted policies and assess prediction efficiency remains elusive. Conventional methods for multivariate time series (MTS) analysis often fail to capture the complex dynamics of environmental change. To address this, we introduce an innovative meta-learning MTS model, MMformer with Adaptive Transferable Multi-head Attention (ATMA), which combines self-attention and meta-learning for enhanced MTS forecasting. Specifically, MMformer is used to model and predict the time series of seven air quality indicators across 331 cities in China from January 2018 to June 2021 and the time series of precipitation and temperature at 2415 monitoring sites during the summer (276 days) from 2012 to 2014, validating the network's ability to perform and forecast MTS data successfully. Experimental results demonstrate that in these datasets, the MMformer model reaching SOTA outperforms iTransformer, Transformer, and the widely used traditional time series prediction algorithm SARIMAX in the prediction of MTS, reducing by 50\% in MSE, 20\% in MAE as compared to others in air quality datasets, reducing by 20\% in MAPE except SARIMAX. Compared with Transformer and SARIMAX in the climate datasets, MSE, MAE, and MAPE are decreased by 30\%, and there is an improvement compared to iTransformer. This approach represents a significant advance in our ability to forecast and respond to dynamic environmental quality challenges in diverse urban and rural environments. Its predictive capabilities provide valuable public health and environmental quality information, informing targeted interventions.
Factor-MCLS: Multi-agent learning system with reward factor matrix and multi-critic framework for dynamic portfolio optimization
Apr 16, 2025Typical deep reinforcement learning (DRL) agents for dynamic portfolio optimization learn the factors influencing portfolio return and risk by analyzing the output values of the reward function while adjusting portfolio weights within the training environment. However, it faces a major limitation where it is difficult for investors to intervene in the training based on different levels of risk aversion towards each portfolio asset. This difficulty arises from another limitation: existing DRL agents may not develop a thorough understanding of the factors responsible for the portfolio return and risk by only learning from the output of the reward function. As a result, the strategy for determining the target portfolio weights is entirely dependent on the DRL agents themselves. To address these limitations, we propose a reward factor matrix for elucidating the return and risk of each asset in the portfolio. Additionally, we propose a novel learning system named Factor-MCLS using a multi-critic framework that facilitates learning of the reward factor matrix. In this way, our DRL-based learning system can effectively learn the factors influencing portfolio return and risk. Moreover, based on the critic networks within the multi-critic framework, we develop a risk constraint term in the training objective function of the policy function. This risk constraint term allows investors to intervene in the training of the DRL agent according to their individual levels of risk aversion towards the portfolio assets.