 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedEFM: Federated Endovascular Foundation Model with Unseen Data
Jan 28, 2025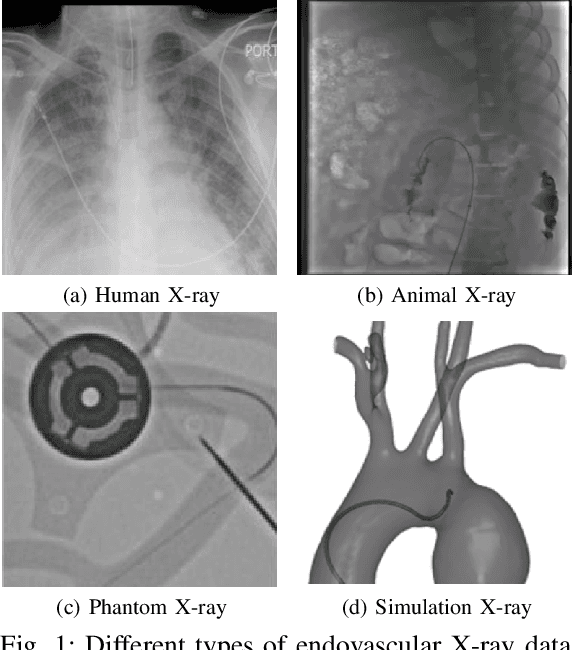
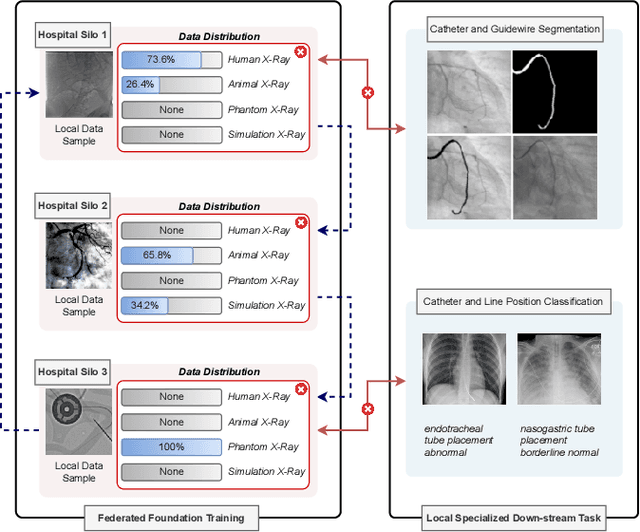

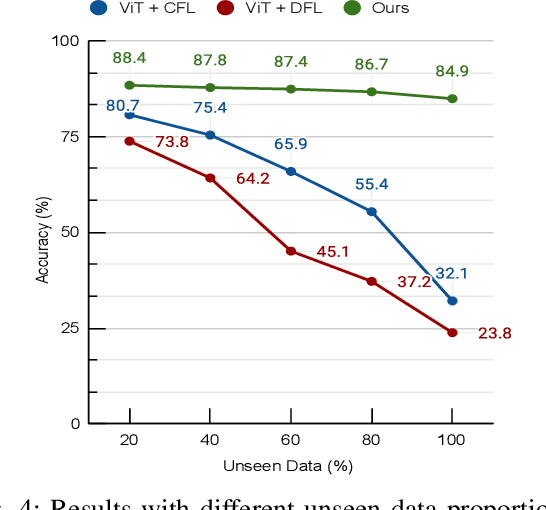
In endovascular surgery, the precise identification of catheters and guidewires in X-ray images is essential for reducing intervention risks. However, accurately segmenting catheter and guidewire structures is challenging due to the limited availability of labeled data. Foundation models offer a promising solution by enabling the collection of similar domain data to train models whose weights can be fine-tuned for downstream tasks. Nonetheless, large-scale data collection for training is constrained by the necessity of maintaining patient privacy. This paper proposes a new method to train a foundation model in a decentralized federated learning setting for endovascular intervention. To ensure the feasibility of the training, we tackle the unseen data issue using differentiable Earth Mover's Distance within a knowledge distillation framework. Once trained, our foundation model's weights provide valuable initialization for downstream tasks, thereby enhancing task-specific performance. Intensive experiments show that our approach achieves new state-of-the-art results, contributing to advancements in endovascular intervention and robotic-assisted endovascular surgery, while addressing the critical issue of data sharing in the medical domain.
Fine-Grained Alignment in Vision-and-Language Navigation through Bayesian Optimization
Nov 22, 2024



This paper addresses the challenge of fine-grained alignment in Vision-and-Language Navigation (VLN) tasks, where robots navigate realistic 3D environments based on natural language instructions. Current approaches use contrastive learning to align language with visual trajectory sequences. Nevertheless, they encounter difficulties with fine-grained vision negatives. To enhance cross-modal embeddings, we introduce a novel Bayesian Optimization-based adversarial optimization framework for creating fine-grained contrastive vision samples. To validate the proposed methodology, we conduct a series of experiments to assess the effectiveness of the enriched embeddings on fine-grained vision negatives. We conduct experiments on two common VLN benchmarks R2R and REVERIE, experiments on the them demonstrate that these embeddings benefit navigation, and can lead to a promising performance enhancement. Our source code and trained models are available at: https://anonymous.4open.science/r/FGVLN.