 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADKnitter: Compositional CAD Generation from Text and Geometry Guidance
Dec 12, 2025Crafting computer-aided design (CAD) models has long been a painstaking and time-intensive task, demanding both precision and expertise from designers. With the emergence of 3D generation, this task has undergone a transformative impact, shifting not only from visual fidelity to functional utility but also enabling editable CAD designs. Prior works have achieved early success in single-part CAD generation, which is not well-suited for real-world applications, as multiple parts need to be assembled under semantic and geometric constraints. In this paper, we propose CADKnitter, a compositional CAD generation framework with a geometry-guided diffusion sampling strategy. CADKnitter is able to generate a complementary CAD part that follows both the geometric constraints of the given CAD model and the semantic constraints of the desired design text prompt. We also curate a dataset, so-called KnitCAD, containing over 310,000 samples of CAD models, along with textual prompts and assembly metadata that provide semantic and geometric constraints. Intensive experiments demonstrate that our proposed method outperforms other state-of-the-art baselines by a clear margin.
EndoWave: Rational-Wavelet 4D Gaussian Splatting for Endoscopic Reconstruction
Oct 27, 2025In robot-assisted minimally invasive surgery, accurate 3D reconstruction from endoscopic video is vital for downstream tasks and improved outcomes. However, endoscopic scenarios present unique challenges, including photometric inconsistencies, non-rigid tissue motion, and view-dependent highlights. Most 3DGS-based methods that rely solely on appearance constraints for optimizing 3DGS are often insufficient in this context, as these dynamic visual artifacts can mislead the optimization process and lead to inaccurate reconstructions. To address these limitations, we present EndoWave, a unified spatio-temporal Gaussian Splatting framework by incorporating an optical flow-based geometric constraint and a multi-resolution rational wavelet supervision. First, we adopt a unified spatio-temporal Gaussian representation that directly optimizes primitives in a 4D domain. Second, we propose a geometric constraint derived from optical flow to enhance temporal coherence and effectively constrain the 3D structure of the scene. Third, we propose a multi-resolution rational orthogonal wavelet as a constraint, which can effectively separate the details of the endoscope and enhance the rendering performance. Extensive evaluations on two real surgical datasets, EndoNeRF and StereoMIS, demonstrate that our method EndoWave achieves state-of-the-art reconstruction quality and visual accuracy compared to the baseline method.
Learning Human Motion with Temporally Conditional Mamba
Oct 14, 2025Learning human motion based on a time-dependent input signal presents a challenging yet impactful task with various applications. The goal of this task is to generate or estimate human movement that consistently reflects the temporal patterns of conditioning inputs. Existing methods typically rely on cross-attention mechanisms to fuse the condition with motion. However, this approach primarily captures global interactions and struggles to maintain step-by-step temporal alignment. To address this limitation, we introduce Temporally Conditional Mamba, a new mamba-based model for human motion generation. Our approach integrates conditional information into the recurrent dynamics of the Mamba block, enabling better temporally aligned motion. To validate the effectiveness of our method, we evaluate it on a variety of human motion tasks. Extensive experiments demonstrate that our model significantly improves temporal alignment, motion realism, and condition consistency over state-of-the-art approaches. Our project page is available at https://zquang2202.github.io/TCM.
I2V-GS: Infrastructure-to-Vehicle View Transformation with Gaussian Splatting for Autonomous Driving Data Generation
Jul 31, 2025Vast and high-quality data are essential for end-to-end autonomous driving systems. However, current driving data is mainly collected by vehicles, which is expensive and inefficient. A potential solution lies in synthesizing data from real-world images. Recent advancements in 3D reconstruction demonstrate photorealistic novel view synthesis, highlighting the potential of generating driving data from images captured on the road. This paper introduces a novel method, I2V-GS, to transfer the Infrastructure view To the Vehicle view with Gaussian Splatting. Reconstruction from sparse infrastructure viewpoints and rendering under large view transformations is a challenging problem. We adopt the adaptive depth warp to generate dense training views. To further expand the range of views, we employ a cascade strategy to inpaint warped images, which also ensures inpainting content is consistent across views. To further ensure the reliability of the diffusion model, we utilize the cross-view information to perform a confidenceguided optimization. Moreover, we introduce RoadSight, a multi-modality, multi-view dataset from real scenarios in infrastructure views. To our knowledge, I2V-GS is the first framework to generate autonomous driving datasets with infrastructure-vehicle view transformation. Experimental results demonstrate that I2V-GS significantly improves synthesis quality under vehicle view, outperforming StreetGaussian in NTA-Iou, NTL-Iou, and FID by 45.7%, 34.2%, and 14.9%, respectively.
StereoMamba: Real-time and Robust Intraoperative Stereo Disparity Estimation via Long-range Spatial Dependencies
Apr 24, 2025Stereo disparity estimation is crucial for obtaining depth information in robot-assisted minimally invasive surgery (RAMIS). While current deep learning methods have made significant advancements, challenges remain in achieving an optimal balance between accuracy, robustness, and inference speed. To address these challenges, we propose the StereoMamba architecture, which is specifically designed for stereo disparity estimation in RAMIS. Our approach is based on a novel Feature Extraction Mamba (FE-Mamba) module, which enhances long-range spatial dependencies both within and across stereo images. To effectively integrate multi-scale features from FE-Mamba, we then introduce a novel Multidimensional Feature Fusion (MFF) module. Experiments against the state-of-the-art on the ex-vivo SCARED benchmark demonstrate that StereoMamba achieves superior performance on EPE of 2.64 px and depth MAE of 2.55 mm, the second-best performance on Bad2 of 41.49% and Bad3 of 26.99%, while maintaining an inference speed of 21.28 FPS for a pair of high-resolution images (1280*1024), striking the optimum balance between accuracy, robustness, and efficiency. Furthermore, by comparing synthesized right images, generated from warping left images using the generated disparity maps, with the actual right image, StereoMamba achieves the best average SSIM (0.8970) and PSNR (16.0761), exhibiting strong zero-shot generalization on the in-vivo RIS2017 and StereoMIS datasets.
Embodied Chain of Action Reasoning with Multi-Modal Foundation Model for Humanoid Loco-manipulation
Apr 13, 2025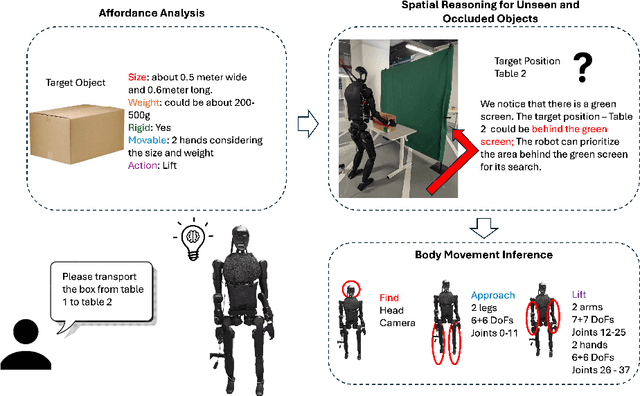
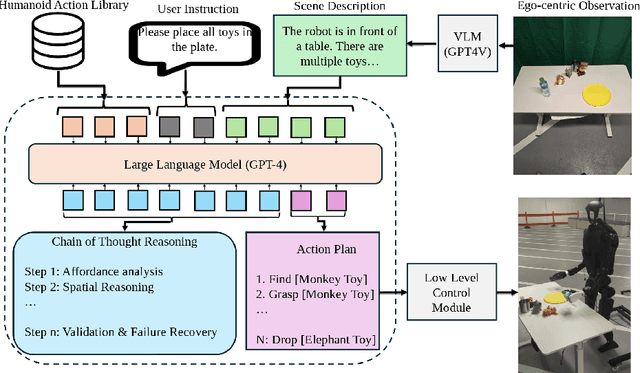
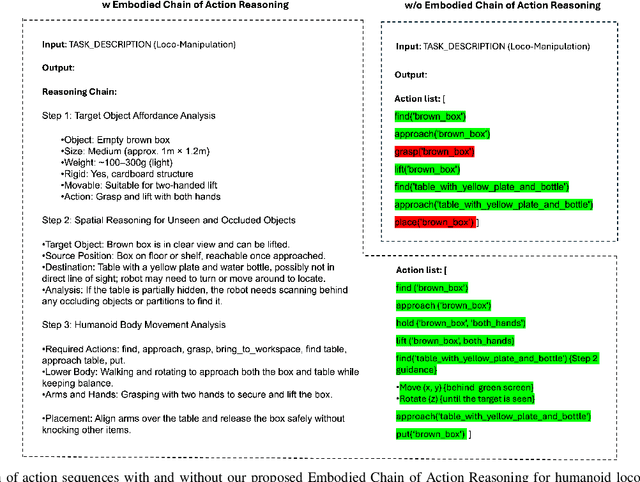

Enabling humanoid robots to autonomously perform loco-manipulation tasks in complex, unstructured environments poses significant challenges. This entails equipping robots with the capability to plan actions over extended horizons while leveraging multi-modality to bridge gaps between high-level planning and actual task execution. Recent advancements in multi-modal foundation models have showcased substantial potential in enhancing planning and reasoning abilities, particularly in the comprehension and processing of semantic information for robotic control tasks. In this paper, we introduce a novel framework based on foundation models that applies the embodied chain of action reasoning methodology to autonomously plan actions from textual instructions for humanoid loco-manipulation. Our method integrates humanoid-specific chain of thought methodology, including detailed affordance and body movement analysis, which provides a breakdown of the task into a sequence of locomotion and manipulation actions. Moreover, we incorporate spatial reasoning based on the observation and target object properties to effectively navigate where target position may be unseen or occluded. Through rigorous experimental setups on object rearrangement, manipulations and loco-manipulation tasks on a real-world environment, we evaluate our method's efficacy on the decoupled upper and lower body control and demonstrate the effectiveness of the chain of robotic action reasoning strategies in comprehending human instructions.
EndoLRMGS: Complete Endoscopic Scene Reconstruction combining Large Reconstruction Modelling and Gaussian Splatting
Mar 28, 2025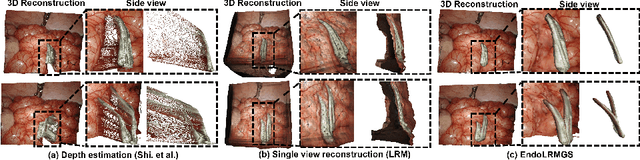
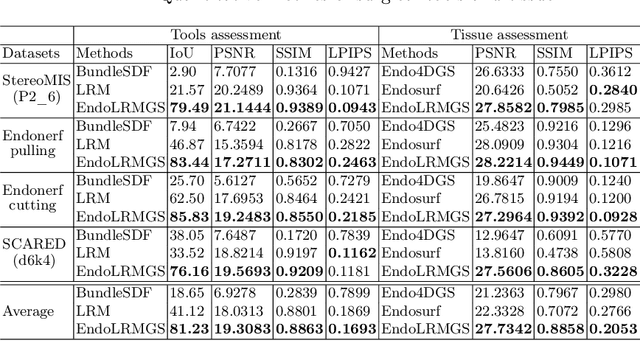
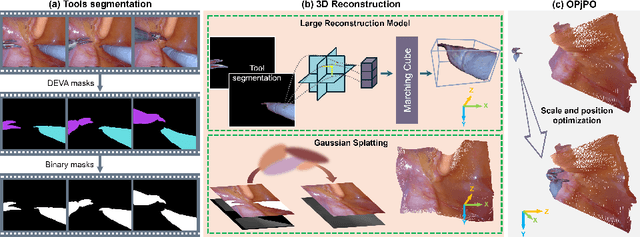
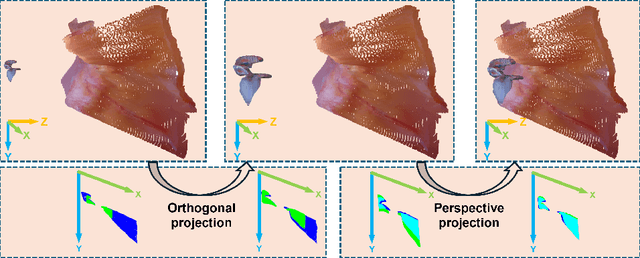
Complete reconstruction of surgical scenes is crucial for robot-assisted surgery (RAS). Deep depth estimation is promising but existing works struggle with depth discontinuities, resulting in noisy predictions at object boundaries and do not achieve complete reconstruction omitting occluded surfaces. To address these issues we propose EndoLRMGS, that combines Large Reconstruction Modelling (LRM) and Gaussian Splatting (GS), for complete surgical scene reconstruction. GS reconstructs deformable tissues and LRM generates 3D models for surgical tools while position and scale are subsequently optimized by introducing orthogonal perspective joint projection optimization (OPjPO) to enhance accuracy. In experiments on four surgical videos from three public datasets, our method improves the Intersection-over-union (IoU) of tool 3D models in 2D projections by>40%. Additionally, EndoLRMGS improves the PSNR of the tools projection from 3.82% to 11.07%. Tissue rendering quality also improves, with PSNR increasing from 0.46% to 49.87%, and SSIM from 1.53% to 29.21% across all test videos.
Hybrid Deep Reinforcement Learning for Radio Tracer Localisation in Robotic-assisted Radioguided Surgery
Mar 11, 2025



Radioguided surgery, such as sentinel lymph node biopsy, relies on the precise localization of radioactive targets by non-imaging gamma/beta detectors. Manual radioactive target detection based on visual display or audible indication of gamma level is highly dependent on the ability of the surgeon to track and interpret the spatial information. This paper presents a learning-based method to realize the autonomous radiotracer detection in robot-assisted surgeries by navigating the probe to the radioactive target. We proposed novel hybrid approach that combines deep reinforcement learning (DRL) with adaptive robotic scanning. The adaptive grid-based scanning could provide initial direction estimation while the DRL-based agent could efficiently navigate to the target utilising historical data. Simulation experiments demonstrate a 95% success rate, and improved efficiency and robustness compared to conventional techniques. Real-world evaluation on the da Vinci Research Kit (dVRK) further confirms the feasibility of the approach, achieving an 80% success rate in radiotracer detection. This method has the potential to enhance consistency, reduce operator dependency, and improve procedural accuracy in radioguided surgeries.
RoboDesign1M: A Large-scale Dataset for Robot Design Understanding
Mar 09, 2025Robot design is a complex and time-consuming process that requires specialized expertise. Gaining a deeper understanding of robot design data can enable various applications, including automated design generation, retrieving example designs from text, and developing AI-powered design assistants. While recent advancements in foundation models present promising approaches to addressing these challenges, progress in this field is hindered by the lack of large-scale design datasets. In this paper, we introduce RoboDesign1M, a large-scale dataset comprising 1 million samples. Our dataset features multimodal data collected from scientific literature, covering various robotics domains. We propose a semi-automated data collection pipeline, enabling efficient and diverse data acquisition. To assess the effectiveness of RoboDesign1M, we conduct extensive experiments across multiple tasks, including design image generation, visual question answering about designs, and design image retrieval. The results demonstrate that our dataset serves as a challenging new benchmark for design understanding tasks and has the potential to advance research in this field. RoboDesign1M will be released to support further developments in AI-driven robotic design automation.
FedEFM: Federated Endovascular Foundation Model with Unseen Data
Jan 28, 2025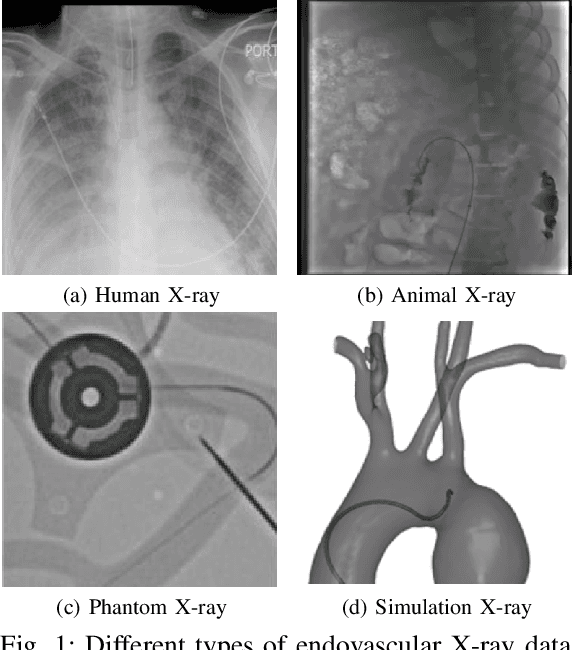
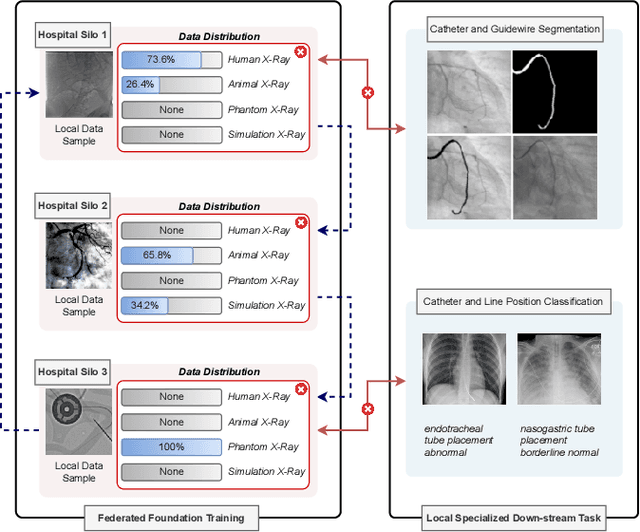

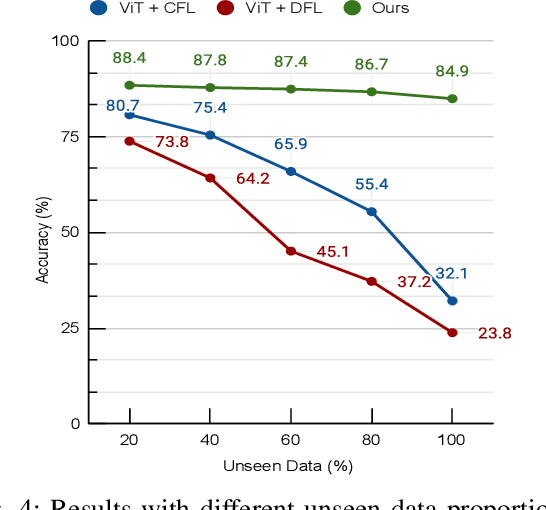
In endovascular surgery, the precise identification of catheters and guidewires in X-ray images is essential for reducing intervention risks. However, accurately segmenting catheter and guidewire structures is challenging due to the limited availability of labeled data. Foundation models offer a promising solution by enabling the collection of similar domain data to train models whose weights can be fine-tuned for downstream tasks. Nonetheless, large-scale data collection for training is constrained by the necessity of maintaining patient privacy. This paper proposes a new method to train a foundation model in a decentralized federated learning setting for endovascular intervention. To ensure the feasibility of the training, we tackle the unseen data issue using differentiable Earth Mover's Distance within a knowledge distillation framework. Once trained, our foundation model's weights provide valuable initialization for downstream tasks, thereby enhancing task-specific performance. Intensive experiments show that our approach achieves new state-of-the-art results, contributing to advancements in endovascular intervention and robotic-assisted endovascular surgery, while addressing the critical issue of data sharing in the medical domain.