 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBT-Bleed: Dual-Branch Temporal Modeling with Key-Frame Selection for Surgical Bleeding Detection
Jun 22, 2026Intraoperative Adverse Events (IAEs) detection is critical for improving surgical safety, with bleeding being among the most frequent events across many surgery types. Existing methods struggle to distinguish bleeding IAE from visually similar residual blood due to limited temporal reasoning. Moreover, modeling long surgical videos while preserving fine-grained temporal dynamics remains computationally challenging. We propose DBT-Bleed, a dual-branch multi-scale temporal modeling framework disentangling bleeding and normal representations using layer-wise temporal adapters for short- and long-term bleeding progression. To efficiently process long surgical videos without sacrificing fine-grained temporal information, we introduce HiRED, a Hierarchical Entropy-Driven frame selection strategy that retains temporally informative segments while removing redundancy. Experiments on the MultiBypass dataset demonstrate gains of 6.53% in F1, 5.62% in Recall and 9% in MCC values for bleeding IAE detection, consistently outperforming video-level baselines. Additionally, we evaluate cross-procedure generalization on a newly curated dataset from a different surgical procedure type, where DBT-Bleed demonstrates robust transferability by achieving gain of 6% in F1 and 8% in MCC under zero-shot setting. To support this evaluation, we introduce EndoPit-IAE, an Endonasal Pituitary Surgery dataset annotated for IAEs, representing the first IAE-annotated dataset in neurosurgery. Code will be made publicly available upon acceptance.
CoRe-DA: Contrastive Regression for Unsupervised Domain Adaptation in Surgical Skill Assessment
Mar 31, 2026Vision-based surgical skill assessment (SSA) enables objective and scalable evaluation of operative performance. Progress in this field is constrained by the high cost and time demands for manual annotation of quantitative skill scores, as well as the poor generalization of existing regression models to new surgical tasks and environments. Meanwhile, appreciable volumes of unlabeled video data are now available, motivating the development of unsupervised domain adaptation (UDA) methods for SSA. We introduce the first benchmark for UDA in SSA regression, spanning four datasets across dry-lab and clinical settings as well as open and robotic surgery. We evaluate eight representative models under challenging domain shifts and propose CoRe-DA, a novel contrastive regression-based adaptation framework. Our method learns domain-invariant representations through relative-score supervision and target-domain self-training. Comprehensive experiments across two UDA settings show that CoRe-DA is superior to state-of-the-art methods, achieving Spearman Correlation Coefficients of 0.46 and 0.41 on dry-lab and clinical target datasets, respectively, without using any labeled target data for training. Overall, CoRe-DA enables scalable SSA with reliable cross-domain generalization, where existing methods underperform. Our code and datasets will be released at https://github.com/anastadimi/CoRe-DA.
FoundationPose-Initialized 3D-2D Liver Registration for Surgical Augmented Reality
Feb 19, 2026Augmented reality can improve tumor localization in laparoscopic liver surgery. Existing registration pipelines typically depend on organ contours; deformable (non-rigid) alignment is often handled with finite-element (FE) models coupled to dimensionality-reduction or machine-learning components. We integrate laparoscopic depth maps with a foundation pose estimator for camera-liver pose estimation and replace FE-based deformation with non-rigid iterative closest point (NICP) to lower engineering/modeling complexity and expertise requirements. On real patient data, the depth-augmented foundation pose approach achieved 9.91 mm mean registration error in 3 cases. Combined rigid-NICP registration outperformed rigid-only registration, demonstrating NICP as an efficient substitute for finite-element deformable models. This pipeline achieves clinically relevant accuracy while offering a lightweight, engineering-friendly alternative to FE-based deformation.
Learning from Single Timestamps: Complexity Estimation in Laparoscopic Cholecystectomy
Nov 06, 2025Purpose: Accurate assessment of surgical complexity is essential in Laparoscopic Cholecystectomy (LC), where severe inflammation is associated with longer operative times and increased risk of postoperative complications. The Parkland Grading Scale (PGS) provides a clinically validated framework for stratifying inflammation severity; however, its automation in surgical videos remains largely unexplored, particularly in realistic scenarios where complete videos must be analyzed without prior manual curation. Methods: In this work, we introduce STC-Net, a novel framework for SingleTimestamp-based Complexity estimation in LC via the PGS, designed to operate under weak temporal supervision. Unlike prior methods limited to static images or manually trimmed clips, STC-Net operates directly on full videos. It jointly performs temporal localization and grading through a localization, window proposal, and grading module. We introduce a novel loss formulation combining hard and soft localization objectives and background-aware grading supervision. Results: Evaluated on a private dataset of 1,859 LC videos, STC-Net achieves an accuracy of 62.11% and an F1-score of 61.42%, outperforming non-localized baselines by over 10% in both metrics and highlighting the effectiveness of weak supervision for surgical complexity assessment. Conclusion: STC-Net demonstrates a scalable and effective approach for automated PGS-based surgical complexity estimation from full LC videos, making it promising for post-operative analysis and surgical training.
Exploring Pre-training Across Domains for Few-Shot Surgical Skill Assessment
Sep 11, 2025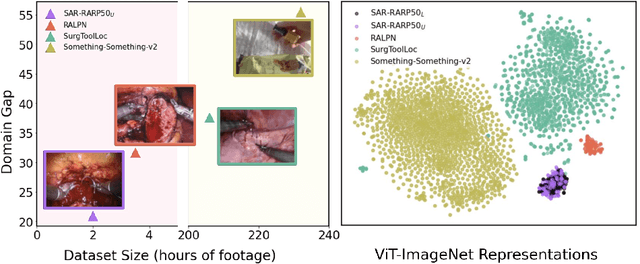

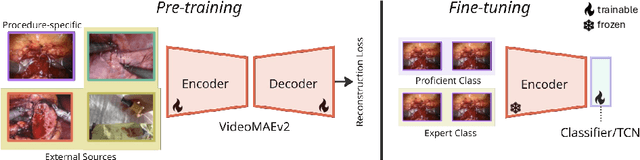
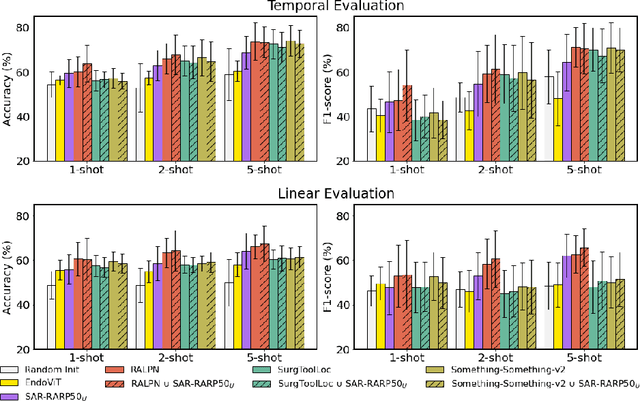
Automated surgical skill assessment (SSA) is a central task in surgical computer vision. Developing robust SSA models is challenging due to the scarcity of skill annotations, which are time-consuming to produce and require expert consensus. Few-shot learning (FSL) offers a scalable alternative enabling model development with minimal supervision, though its success critically depends on effective pre-training. While widely studied for several surgical downstream tasks, pre-training has remained largely unexplored in SSA. In this work, we formulate SSA as a few-shot task and investigate how self-supervised pre-training strategies affect downstream few-shot SSA performance. We annotate a publicly available robotic surgery dataset with Objective Structured Assessment of Technical Skill (OSATS) scores, and evaluate various pre-training sources across three few-shot settings. We quantify domain similarity and analyze how domain gap and the inclusion of procedure-specific data into pre-training influence transferability. Our results show that small but domain-relevant datasets can outperform large scale, less aligned ones, achieving accuracies of 60.16%, 66.03%, and 73.65% in the 1-, 2-, and 5-shot settings, respectively. Moreover, incorporating procedure-specific data into pre-training with a domain-relevant external dataset significantly boosts downstream performance, with an average gain of +1.22% in accuracy and +2.28% in F1-score; however, applying the same strategy with less similar but large-scale sources can instead lead to performance degradation. Code and models are available at https://github.com/anastadimi/ssa-fsl.
StereoMamba: Real-time and Robust Intraoperative Stereo Disparity Estimation via Long-range Spatial Dependencies
Apr 24, 2025Stereo disparity estimation is crucial for obtaining depth information in robot-assisted minimally invasive surgery (RAMIS). While current deep learning methods have made significant advancements, challenges remain in achieving an optimal balance between accuracy, robustness, and inference speed. To address these challenges, we propose the StereoMamba architecture, which is specifically designed for stereo disparity estimation in RAMIS. Our approach is based on a novel Feature Extraction Mamba (FE-Mamba) module, which enhances long-range spatial dependencies both within and across stereo images. To effectively integrate multi-scale features from FE-Mamba, we then introduce a novel Multidimensional Feature Fusion (MFF) module. Experiments against the state-of-the-art on the ex-vivo SCARED benchmark demonstrate that StereoMamba achieves superior performance on EPE of 2.64 px and depth MAE of 2.55 mm, the second-best performance on Bad2 of 41.49% and Bad3 of 26.99%, while maintaining an inference speed of 21.28 FPS for a pair of high-resolution images (1280*1024), striking the optimum balance between accuracy, robustness, and efficiency. Furthermore, by comparing synthesized right images, generated from warping left images using the generated disparity maps, with the actual right image, StereoMamba achieves the best average SSIM (0.8970) and PSNR (16.0761), exhibiting strong zero-shot generalization on the in-vivo RIS2017 and StereoMIS datasets.
EndoLRMGS: Complete Endoscopic Scene Reconstruction combining Large Reconstruction Modelling and Gaussian Splatting
Mar 28, 2025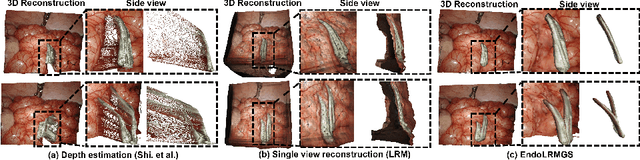
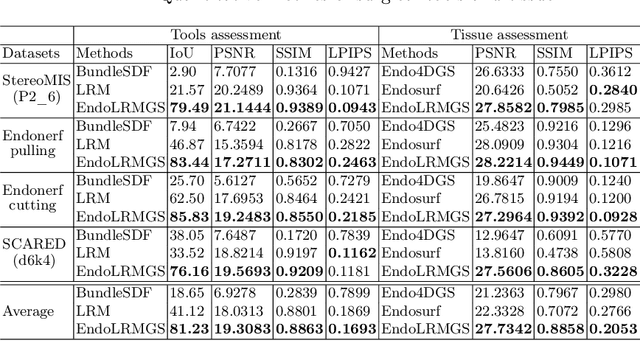
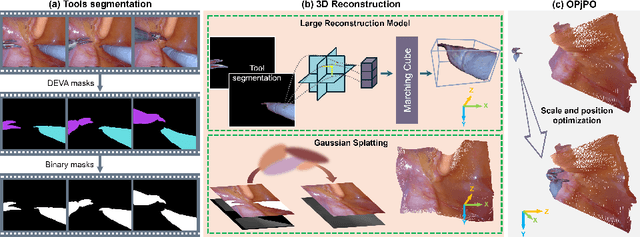
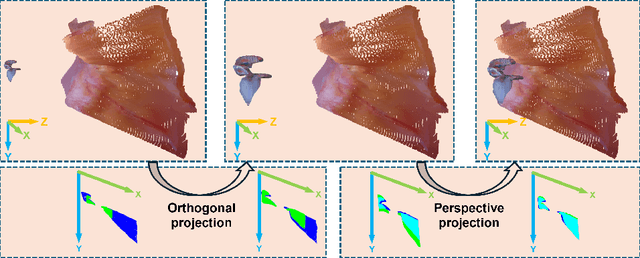
Complete reconstruction of surgical scenes is crucial for robot-assisted surgery (RAS). Deep depth estimation is promising but existing works struggle with depth discontinuities, resulting in noisy predictions at object boundaries and do not achieve complete reconstruction omitting occluded surfaces. To address these issues we propose EndoLRMGS, that combines Large Reconstruction Modelling (LRM) and Gaussian Splatting (GS), for complete surgical scene reconstruction. GS reconstructs deformable tissues and LRM generates 3D models for surgical tools while position and scale are subsequently optimized by introducing orthogonal perspective joint projection optimization (OPjPO) to enhance accuracy. In experiments on four surgical videos from three public datasets, our method improves the Intersection-over-union (IoU) of tool 3D models in 2D projections by>40%. Additionally, EndoLRMGS improves the PSNR of the tools projection from 3.82% to 11.07%. Tissue rendering quality also improves, with PSNR increasing from 0.46% to 49.87%, and SSIM from 1.53% to 29.21% across all test videos.
KEVS: Enhancing Segmentation of Visceral Adipose Tissue in Pre-Cystectomy CT with Gaussian Kernel Density Estimation
Mar 28, 2025Purpose: The distribution of visceral adipose tissue (VAT) in cystectomy patients is indicative of the incidence of post-operative complications. Existing VAT segmentation methods for computed tomography (CT) employing intensity thresholding have limitations relating to inter-observer variability. Moreover, the difficulty in creating ground-truth masks limits the development of deep learning (DL) models for this task. This paper introduces a novel method for VAT prediction in pre-cystectomy CT, which is fully automated and does not require ground-truth VAT masks for training, overcoming aforementioned limitations. Methods: We introduce the Kernel density Enhanced VAT Segmentator ( KEVS), combining a DL semantic segmentation model, for multi-body feature prediction, with Gaussian kernel density estimation analysis of predicted subcutaneous adipose tissue to achieve accurate scan-specific predictions of VAT in the abdominal cavity. Uniquely for a DL pipeline, KEVS does not require ground-truth VAT masks. Results: We verify the ability of KEVS to accurately segment abdominal organs in unseen CT data and compare KEVS VAT segmentation predictions to existing state-of-the-art (SOTA) approaches in a dataset of 20 pre-cystectomy CT scans, collected from University College London Hospital (UCLH-Cyst), with expert ground-truth annotations. KEVS presents a 4.80% and 6.02% improvement in Dice Coefficient over the second best DL and thresholding-based VAT segmentation techniques respectively when evaluated on UCLH-Cyst. Conclusion: This research introduces KEVS; an automated, SOTA method for the prediction of VAT in pre-cystectomy CT which eliminates inter-observer variability and is trained entirely on open-source CT datasets which do not contain ground-truth VAT masks.
3D Acetabular Surface Reconstruction from 2D Pre-operative X-ray Images using SRVF Elastic Registration and Deformation Graph
Mar 28, 2025



Accurate and reliable selection of the appropriate acetabular cup size is crucial for restoring joint biomechanics in total hip arthroplasty (THA). This paper proposes a novel framework that integrates square-root velocity function (SRVF)-based elastic shape registration technique with an embedded deformation (ED) graph approach to reconstruct the 3D articular surface of the acetabulum by fusing multiple views of 2D pre-operative pelvic X-ray images and a hemispherical surface model. The SRVF-based elastic registration establishes 2D-3D correspondences between the parametric hemispherical model and X-ray images, and the ED framework incorporates the SRVF-derived correspondences as constraints to optimize the 3D acetabular surface reconstruction using nonlinear least-squares optimization. Validations using both simulation and real patient datasets are performed to demonstrate the robustness and the potential clinical value of the proposed algorithm. The reconstruction result can assist surgeons in selecting the correct acetabular cup on the first attempt in primary THA, minimising the need for revision surgery.
SurgRAW: Multi-Agent Workflow with Chain-of-Thought Reasoning for Surgical Intelligence
Mar 13, 2025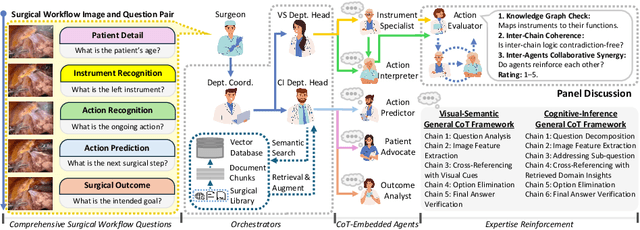
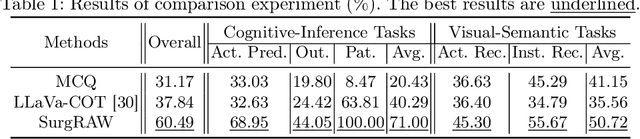
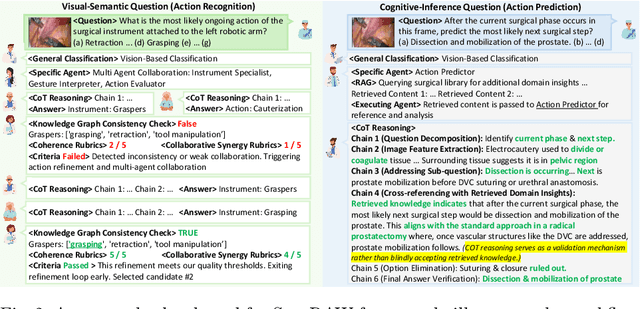
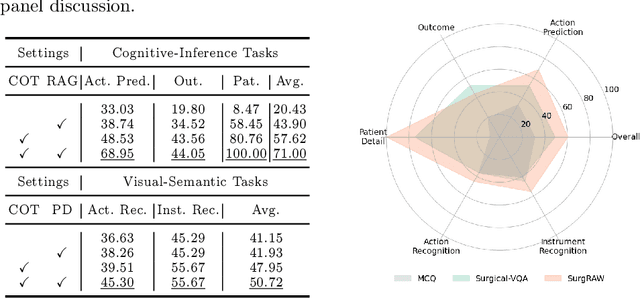
Integration of Vision-Language Models (VLMs) in surgical intelligence is hindered by hallucinations, domain knowledge gaps, and limited understanding of task interdependencies within surgical scenes, undermining clinical reliability. While recent VLMs demonstrate strong general reasoning and thinking capabilities, they still lack the domain expertise and task-awareness required for precise surgical scene interpretation. Although Chain-of-Thought (CoT) can structure reasoning more effectively, current approaches rely on self-generated CoT steps, which often exacerbate inherent domain gaps and hallucinations. To overcome this, we present SurgRAW, a CoT-driven multi-agent framework that delivers transparent, interpretable insights for most tasks in robotic-assisted surgery. By employing specialized CoT prompts across five tasks: instrument recognition, action recognition, action prediction, patient data extraction, and outcome assessment, SurgRAW mitigates hallucinations through structured, domain-aware reasoning. Retrieval-Augmented Generation (RAG) is also integrated to external medical knowledge to bridge domain gaps and improve response reliability. Most importantly, a hierarchical agentic system ensures that CoT-embedded VLM agents collaborate effectively while understanding task interdependencies, with a panel discussion mechanism promotes logical consistency. To evaluate our method, we introduce SurgCoTBench, the first reasoning-based dataset with structured frame-level annotations. With comprehensive experiments, we demonstrate the effectiveness of proposed SurgRAW with 29.32% accuracy improvement over baseline VLMs on 12 robotic procedures, achieving the state-of-the-art performance and advancing explainable, trustworthy, and autonomous surgical assistance.