 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgicalVLM-Agent: Towards an Interactive AI Co-Pilot for Pituitary Surgery
Mar 12, 2025



Image-guided surgery demands adaptive, real-time decision support, yet static AI models struggle with structured task planning and providing interactive guidance. Large vision-language models (VLMs) offer a promising solution by enabling dynamic task planning and predictive decision support. We introduce SurgicalVLM-Agent, an AI co-pilot for image-guided pituitary surgery, capable of conversation, planning, and task execution. The agent dynamically processes surgeon queries and plans the tasks such as MRI tumor segmentation, endoscope anatomy segmentation, overlaying preoperative imaging with intraoperative views, instrument tracking, and surgical visual question answering (VQA). To enable structured task planning, we develop the PitAgent dataset, a surgical context-aware dataset covering segmentation, overlaying, instrument localization, tool tracking, tool-tissue interactions, phase identification, and surgical activity recognition. Additionally, we propose FFT-GaLore, a fast Fourier transform (FFT)-based gradient projection technique for efficient low-rank adaptation, optimizing fine-tuning for LLaMA 3.2 in surgical environments. We validate SurgicalVLM-Agent by assessing task planning and prompt generation on our PitAgent dataset and evaluating zero-shot VQA using a public pituitary dataset. Results demonstrate state-of-the-art performance in task planning and query interpretation, with highly semantically meaningful VQA responses, advancing AI-driven surgical assistance.
PitVQA++: Vector Matrix-Low-Rank Adaptation for Open-Ended Visual Question Answering in Pituitary Surgery
Feb 19, 2025


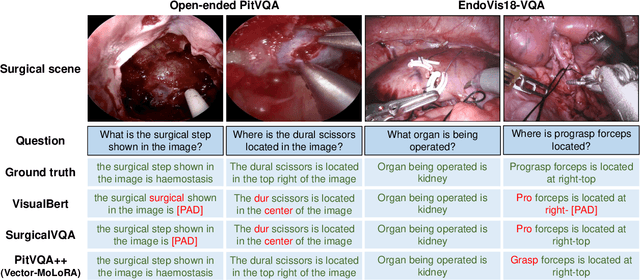
Vision-Language Models (VLMs) in visual question answering (VQA) offer a unique opportunity to enhance intra-operative decision-making, promote intuitive interactions, and significantly advancing surgical education. However, the development of VLMs for surgical VQA is challenging due to limited datasets and the risk of overfitting and catastrophic forgetting during full fine-tuning of pretrained weights. While parameter-efficient techniques like Low-Rank Adaptation (LoRA) and Matrix of Rank Adaptation (MoRA) address adaptation challenges, their uniform parameter distribution overlooks the feature hierarchy in deep networks, where earlier layers, that learn general features, require more parameters than later ones. This work introduces PitVQA++ with an open-ended PitVQA dataset and vector matrix-low-rank adaptation (Vector-MoLoRA), an innovative VLM fine-tuning approach for adapting GPT-2 to pituitary surgery. Open-Ended PitVQA comprises around 101,803 frames from 25 procedural videos with 745,972 question-answer sentence pairs, covering key surgical elements such as phase and step recognition, context understanding, tool detection, localization, and interactions recognition. Vector-MoLoRA incorporates the principles of LoRA and MoRA to develop a matrix-low-rank adaptation strategy that employs vector ranking to allocate more parameters to earlier layers, gradually reducing them in the later layers. Our approach, validated on the Open-Ended PitVQA and EndoVis18-VQA datasets, effectively mitigates catastrophic forgetting while significantly enhancing performance over recent baselines. Furthermore, our risk-coverage analysis highlights its enhanced reliability and trustworthiness in handling uncertain predictions. Our source code and dataset is available at~\url{https://github.com/HRL-Mike/PitVQA-Plus}.
PitRSDNet: Predicting Intra-operative Remaining Surgery Duration in Endoscopic Pituitary Surgery
Sep 25, 2024



Accurate intra-operative Remaining Surgery Duration (RSD) predictions allow for anaesthetists to more accurately decide when to administer anaesthetic agents and drugs, as well as to notify hospital staff to send in the next patient. Therefore RSD plays an important role in improving patient care and minimising surgical theatre costs via efficient scheduling. In endoscopic pituitary surgery, it is uniquely challenging due to variable workflow sequences with a selection of optional steps contributing to high variability in surgery duration. This paper presents PitRSDNet for predicting RSD during pituitary surgery, a spatio-temporal neural network model that learns from historical data focusing on workflow sequences. PitRSDNet integrates workflow knowledge into RSD prediction in two forms: 1) multi-task learning for concurrently predicting step and RSD; and 2) incorporating prior steps as context in temporal learning and inference. PitRSDNet is trained and evaluated on a new endoscopic pituitary surgery dataset with 88 videos to show competitive performance improvements over previous statistical and machine learning methods. The findings also highlight how PitRSDNet improve RSD precision on outlier cases utilising the knowledge of prior steps.
Automated Surgical Skill Assessment in Endoscopic Pituitary Surgery using Real-time Instrument Tracking on a High-fidelity Bench-top Phantom
Sep 25, 2024Improved surgical skill is generally associated with improved patient outcomes, although assessment is subjective; labour-intensive; and requires domain specific expertise. Automated data driven metrics can alleviate these difficulties, as demonstrated by existing machine learning instrument tracking models in minimally invasive surgery. However, these models have been tested on limited datasets of laparoscopic surgery, with a focus on isolated tasks and robotic surgery. In this paper, a new public dataset is introduced, focusing on simulated surgery, using the nasal phase of endoscopic pituitary surgery as an exemplar. Simulated surgery allows for a realistic yet repeatable environment, meaning the insights gained from automated assessment can be used by novice surgeons to hone their skills on the simulator before moving to real surgery. PRINTNet (Pituitary Real-time INstrument Tracking Network) has been created as a baseline model for this automated assessment. Consisting of DeepLabV3 for classification and segmentation; StrongSORT for tracking; and the NVIDIA Holoscan SDK for real-time performance, PRINTNet achieved 71.9% Multiple Object Tracking Precision running at 22 Frames Per Second. Using this tracking output, a Multilayer Perceptron achieved 87% accuracy in predicting surgical skill level (novice or expert), with the "ratio of total procedure time to instrument visible time" correlated with higher surgical skill. This therefore demonstrates the feasibility of automated surgical skill assessment in simulated endoscopic pituitary surgery. The new publicly available dataset can be found here: https://doi.org/10.5522/04/26511049.
PitVis-2023 Challenge: Workflow Recognition in videos of Endoscopic Pituitary Surgery
Sep 02, 2024

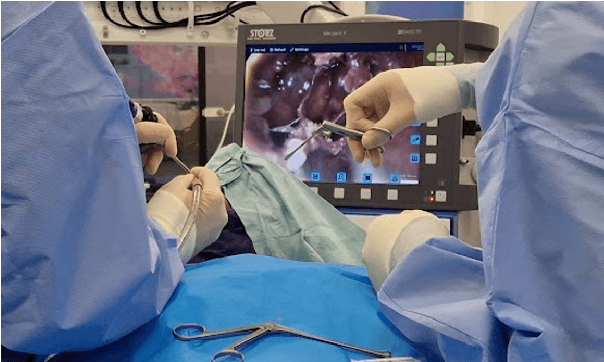
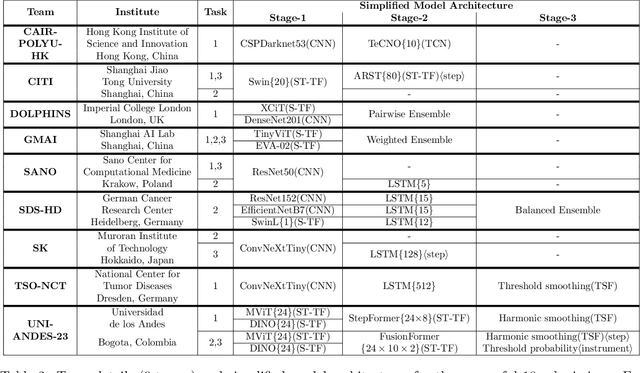
The field of computer vision applied to videos of minimally invasive surgery is ever-growing. Workflow recognition pertains to the automated recognition of various aspects of a surgery: including which surgical steps are performed; and which surgical instruments are used. This information can later be used to assist clinicians when learning the surgery; during live surgery; and when writing operation notes. The Pituitary Vision (PitVis) 2023 Challenge tasks the community to step and instrument recognition in videos of endoscopic pituitary surgery. This is a unique task when compared to other minimally invasive surgeries due to the smaller working space, which limits and distorts vision; and higher frequency of instrument and step switching, which requires more precise model predictions. Participants were provided with 25-videos, with results presented at the MICCAI-2023 conference as part of the Endoscopic Vision 2023 Challenge in Vancouver, Canada, on 08-Oct-2023. There were 18-submissions from 9-teams across 6-countries, using a variety of deep learning models. A commonality between the top performing models was incorporating spatio-temporal and multi-task methods, with greater than 50% and 10% macro-F1-score improvement over purely spacial single-task models in step and instrument recognition respectively. The PitVis-2023 Challenge therefore demonstrates state-of-the-art computer vision models in minimally invasive surgery are transferable to a new dataset, with surgery specific techniques used to enhance performance, progressing the field further. Benchmark results are provided in the paper, and the dataset is publicly available at: https://doi.org/10.5522/04/26531686.
PitVQA: Image-grounded Text Embedding LLM for Visual Question Answering in Pituitary Surgery
May 22, 2024



Visual Question Answering (VQA) within the surgical domain, utilizing Large Language Models (LLMs), offers a distinct opportunity to improve intra-operative decision-making and facilitate intuitive surgeon-AI interaction. However, the development of LLMs for surgical VQA is hindered by the scarcity of diverse and extensive datasets with complex reasoning tasks. Moreover, contextual fusion of the image and text modalities remains an open research challenge due to the inherent differences between these two types of information and the complexity involved in aligning them. This paper introduces PitVQA, a novel dataset specifically designed for VQA in endonasal pituitary surgery and PitVQA-Net, an adaptation of the GPT2 with a novel image-grounded text embedding for surgical VQA. PitVQA comprises 25 procedural videos and a rich collection of question-answer pairs spanning crucial surgical aspects such as phase and step recognition, context understanding, tool detection and localization, and tool-tissue interactions. PitVQA-Net consists of a novel image-grounded text embedding that projects image and text features into a shared embedding space and GPT2 Backbone with an excitation block classification head to generate contextually relevant answers within the complex domain of endonasal pituitary surgery. Our image-grounded text embedding leverages joint embedding, cross-attention and contextual representation to understand the contextual relationship between questions and surgical images. We demonstrate the effectiveness of PitVQA-Net on both the PitVQA and the publicly available EndoVis18-VQA dataset, achieving improvements in balanced accuracy of 8% and 9% over the most recent baselines, respectively. Our code and dataset is available at https://github.com/mobarakol/PitVQA.
Shifted-Windows Transformers for the Detection of Cerebral Aneurysms in Microsurgery
Mar 16, 2023Purpose: Microsurgical Aneurysm Clipping Surgery (MACS) carries a high risk for intraoperative aneurysm rupture. Automated recognition of instances when the aneurysm is exposed in the surgical video would be a valuable reference point for neuronavigation, indicating phase transitioning and more importantly designating moments of high risk for rupture. This article introduces the MACS dataset containing 16 surgical videos with frame-level expert annotations and proposes a learning methodology for surgical scene understanding identifying video frames with the aneurysm present in the operating microscope's field-of-view. Methods: Despite the dataset imbalance (80% no presence, 20% presence) and developed without explicit annotations, we demonstrate the applicability of Transformer-based deep learning architectures (MACSSwin-T, vidMACSSwin-T) to detect the aneurysm and classify MACS frames accordingly. We evaluate the proposed models in multiple-fold cross-validation experiments with independent sets and in an unseen set of 15 images against 10 human experts (neurosurgeons). Results: Average (across folds) accuracy of 80.8% (range 78.5%-82.4%) and 87.1% (range 85.1%-91.3%) is obtained for the image- and video-level approach respectively, demonstrating that the models effectively learn the classification task. Qualitative evaluation of the models' class activation maps show these to be localized on the aneurysm's actual location. Depending on the decision threshold, MACSWin-T achieves 66.7% to 86.7% accuracy in the unseen images, compared to 82% of human raters, with moderate to strong correlation.
Surgical Video Motion Magnification with Suppression of Instrument Artefacts
Sep 16, 2020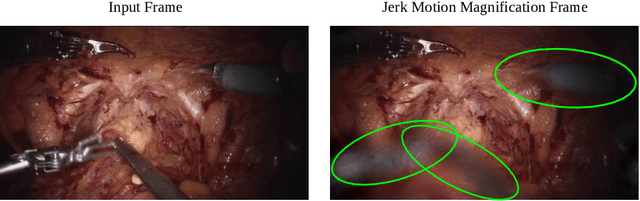
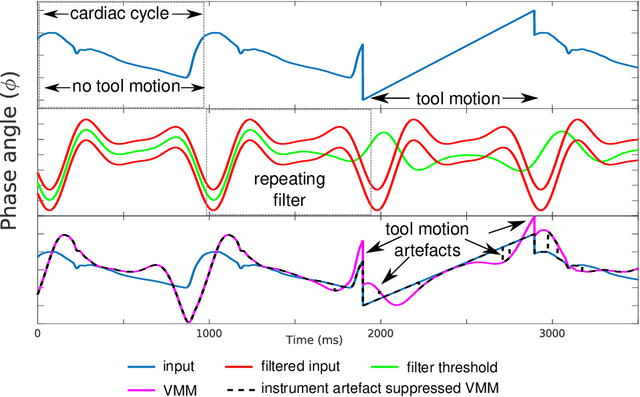
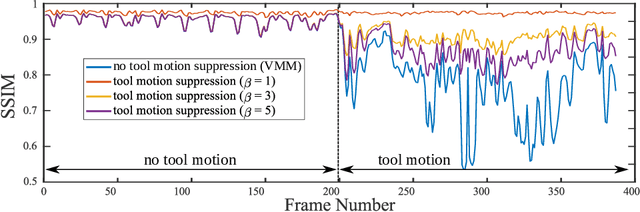

Video motion magnification could directly highlight subsurface blood vessels in endoscopic video in order to prevent inadvertent damage and bleeding. Applying motion filters to the full surgical image is however sensitive to residual motion from the surgical instruments and can impede practical application due to aberration motion artefacts. By storing the temporal filter response from local spatial frequency information for a single cardiovascular cycle prior to tool introduction to the scene, a filter can be used to determine if motion magnification should be active for a spatial region of the surgical image. In this paper, we propose a strategy to reduce aberration due to non-physiological motion for surgical video motion magnification. We present promising results on endoscopic transnasal transsphenoidal pituitary surgery with a quantitative comparison to recent methods using Structural Similarity (SSIM), as well as qualitative analysis by comparing spatio-temporal cross sections of the videos and individual frames.