 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSS: Open Suturing Skills Vision-Based Assessment Challenge 2024-2025
May 21, 2026Achieving high levels of surgical skill through effective training is essential for optimal patient outcomes. Automated, data-driven skill assessment holds significant potential to improve surgical training. While machine learning-based methods are increasingly popular for assessing skills in minimally invasive surgery, their application to open surgery remains limited. We present the results of a dedicated MICCAI challenge designed to benchmark and advance vision-based skill assessment in open surgery. The challenge dataset comprises videos of an open suturing training task recorded with a static GoPro camera in a dry-lab setting, with instrument trajectories available in addition to the primary video modality. The OSS Challenge was hosted over two consecutive years, comprising two and three independent tasks, respectively: (1) classifying skill level into four classes, (2) predicting the full Objective Structured Assessment of Technical Skills across eight categories, and (3) tracking hands and surgical tools. Participants submitted diverse solutions including deep learning-based video models, tracking-driven methods, and hybrid approaches. General-purpose spatiotemporal video models consistently achieved the strongest performance, though conceptually diverse approaches reached competitive levels when well-executed. Predicting fine-grained OSATS scores remains challenging but benefits substantially from increased training data. Keypoint tracking proves difficult given frequent occlusions and out-of-frame instances, limiting current applicability for motion-based skill analysis. This work benchmarks innovative and diverse solutions for surgical skill assessment, highlighting both the promise and current limitations of video-based evaluation in open surgery and identifying critical directions for advancing automated skill assessment toward clinical impact.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
SurgicalVLM-Agent: Towards an Interactive AI Co-Pilot for Pituitary Surgery
Mar 12, 2025



Image-guided surgery demands adaptive, real-time decision support, yet static AI models struggle with structured task planning and providing interactive guidance. Large vision-language models (VLMs) offer a promising solution by enabling dynamic task planning and predictive decision support. We introduce SurgicalVLM-Agent, an AI co-pilot for image-guided pituitary surgery, capable of conversation, planning, and task execution. The agent dynamically processes surgeon queries and plans the tasks such as MRI tumor segmentation, endoscope anatomy segmentation, overlaying preoperative imaging with intraoperative views, instrument tracking, and surgical visual question answering (VQA). To enable structured task planning, we develop the PitAgent dataset, a surgical context-aware dataset covering segmentation, overlaying, instrument localization, tool tracking, tool-tissue interactions, phase identification, and surgical activity recognition. Additionally, we propose FFT-GaLore, a fast Fourier transform (FFT)-based gradient projection technique for efficient low-rank adaptation, optimizing fine-tuning for LLaMA 3.2 in surgical environments. We validate SurgicalVLM-Agent by assessing task planning and prompt generation on our PitAgent dataset and evaluating zero-shot VQA using a public pituitary dataset. Results demonstrate state-of-the-art performance in task planning and query interpretation, with highly semantically meaningful VQA responses, advancing AI-driven surgical assistance.
Endo-FASt3r: Endoscopic Foundation model Adaptation for Structure from motion
Mar 10, 2025Accurate depth and camera pose estimation is essential for achieving high-quality 3D visualisations in robotic-assisted surgery. Despite recent advancements in foundation model adaptation to monocular depth estimation of endoscopic scenes via self-supervised learning (SSL), no prior work has explored their use for pose estimation. These methods rely on low rank-based adaptation approaches, which constrain model updates to a low-rank space. We propose Endo-FASt3r, the first monocular SSL depth and pose estimation framework that uses foundation models for both tasks. We extend the Reloc3r relative pose estimation foundation model by designing Reloc3rX, introducing modifications necessary for convergence in SSL. We also present DoMoRA, a novel adaptation technique that enables higher-rank updates and faster convergence. Experiments on the SCARED dataset show that Endo-FASt3r achieves a substantial $10\%$ improvement in pose estimation and a $2\%$ improvement in depth estimation over prior work. Similar performance gains on the Hamlyn and StereoMIS datasets reinforce the generalisability of Endo-FASt3r across different datasets.
DARES: Depth Anything in Robotic Endoscopic Surgery with Self-supervised Vector-LoRA of the Foundation Model
Aug 30, 2024



Robotic-assisted surgery (RAS) relies on accurate depth estimation for 3D reconstruction and visualization. While foundation models like Depth Anything Models (DAM) show promise, directly applying them to surgery often yields suboptimal results. Fully fine-tuning on limited surgical data can cause overfitting and catastrophic forgetting, compromising model robustness and generalization. Although Low-Rank Adaptation (LoRA) addresses some adaptation issues, its uniform parameter distribution neglects the inherent feature hierarchy, where earlier layers, learning more general features, require more parameters than later ones. To tackle this issue, we introduce Depth Anything in Robotic Endoscopic Surgery (DARES), a novel approach that employs a new adaptation technique, Vector Low-Rank Adaptation (Vector-LoRA) on the DAM V2 to perform self-supervised monocular depth estimation in RAS scenes. To enhance learning efficiency, we introduce Vector-LoRA by integrating more parameters in earlier layers and gradually decreasing parameters in later layers. We also design a reprojection loss based on the multi-scale SSIM error to enhance depth perception by better tailoring the foundation model to the specific requirements of the surgical environment. The proposed method is validated on the SCARED dataset and demonstrates superior performance over recent state-of-the-art self-supervised monocular depth estimation techniques, achieving an improvement of 13.3% in the absolute relative error metric. The code and pre-trained weights are available at https://github.com/mobarakol/DARES.
SEDMamba: Enhancing Selective State Space Modelling with Bottleneck Mechanism and Fine-to-Coarse Temporal Fusion for Efficient Error Detection in Robot-Assisted Surgery
Jun 22, 2024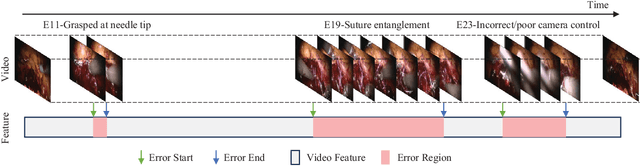
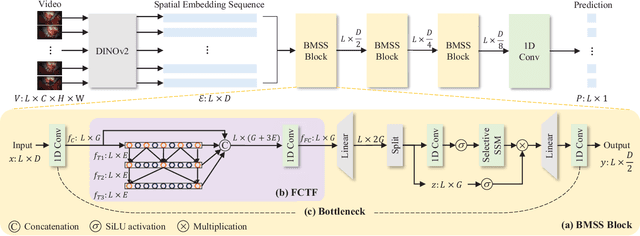
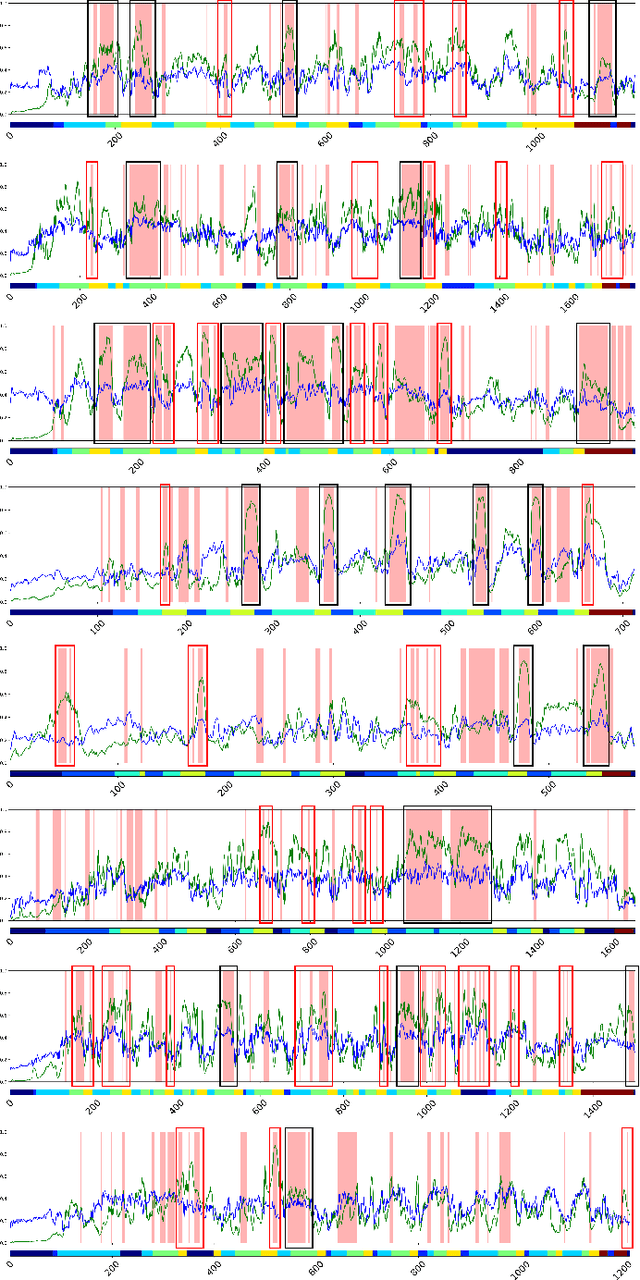
Automated detection of surgical errors can improve robotic-assisted surgery. Despite promising progress, existing methods still face challenges in capturing rich temporal context to establish long-term dependencies while maintaining computational efficiency. In this paper, we propose a novel hierarchical model named SEDMamba, which incorporates the selective state space model (SSM) into surgical error detection, facilitating efficient long sequence modelling with linear complexity. SEDMamba enhances selective SSM with bottleneck mechanism and fine-to-coarse temporal fusion (FCTF) to detect and temporally localize surgical errors in long videos. The bottleneck mechanism compresses and restores features within their spatial dimension, thereby reducing computational complexity. FCTF utilizes multiple dilated 1D convolutional layers to merge temporal information across diverse scale ranges, accommodating errors of varying durations. Besides, we deploy an established observational clinical human reliability assessment tool (OCHRA) to annotate the errors of suturing tasks in an open-source radical prostatectomy dataset (SAR-RARP50), constructing the first frame-level in-vivo surgical error detection dataset to support error detection in real-world scenarios. Experimental results demonstrate that our SEDMamba outperforms state-of-the-art methods with at least 1.82% AUC and 3.80% AP performance gain with significantly reduced computational complexity.
Objective Surgical Skills Assessment and Tool Localization: Results from the MICCAI 2021 SimSurgSkill Challenge
Dec 08, 2022Timely and effective feedback within surgical training plays a critical role in developing the skills required to perform safe and efficient surgery. Feedback from expert surgeons, while especially valuable in this regard, is challenging to acquire due to their typically busy schedules, and may be subject to biases. Formal assessment procedures like OSATS and GEARS attempt to provide objective measures of skill, but remain time-consuming. With advances in machine learning there is an opportunity for fast and objective automated feedback on technical skills. The SimSurgSkill 2021 challenge (hosted as a sub-challenge of EndoVis at MICCAI 2021) aimed to promote and foster work in this endeavor. Using virtual reality (VR) surgical tasks, competitors were tasked with localizing instruments and predicting surgical skill. Here we summarize the winning approaches and how they performed. Using this publicly available dataset and results as a springboard, future work may enable more efficient training of surgeons with advances in surgical data science. The dataset can be accessed from https://console.cloud.google.com/storage/browser/isi-simsurgskill-2021.
Towards a Computed-Aided Diagnosis System in Colonoscopy: Automatic Polyp Segmentation Using Convolution Neural Networks
Jan 15, 2021
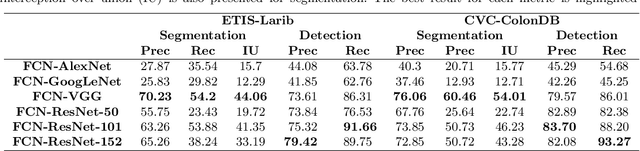
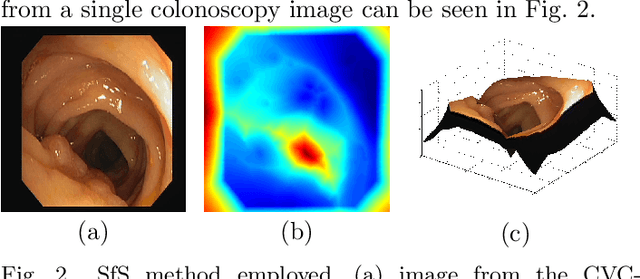

Early diagnosis is essential for the successful treatment of bowel cancers including colorectal cancer (CRC) and capsule endoscopic imaging with robotic actuation can be a valuable diagnostic tool when combined with automated image analysis. We present a deep learning rooted detection and segmentation framework for recognizing lesions in colonoscopy and capsule endoscopy images. We restructure established convolution architectures, such as VGG and ResNets, by converting them into fully-connected convolution networks (FCNs), fine-tune them and study their capabilities for polyp segmentation and detection. We additionally use Shape from-Shading (SfS) to recover depth and provide a richer representation of the tissue's structure in colonoscopy images. Depth is incorporated into our network models as an additional input channel to the RGB information and we demonstrate that the resulting network yields improved performance. Our networks are tested on publicly available datasets and the most accurate segmentation model achieved a mean segmentation IU of 47.78% and 56.95% on the ETIS-Larib and CVC-Colon datasets, respectively. For polyp detection, the top performing models we propose surpass the current state of the art with detection recalls superior to 90% for all datasets tested. To our knowledge, we present the first work to use FCNs for polyp segmentation in addition to proposing a novel combination of SfS and RGB that boosts performance
* 10 pages, 6 figures
Widening siamese architectures for stereo matching
Nov 01, 2017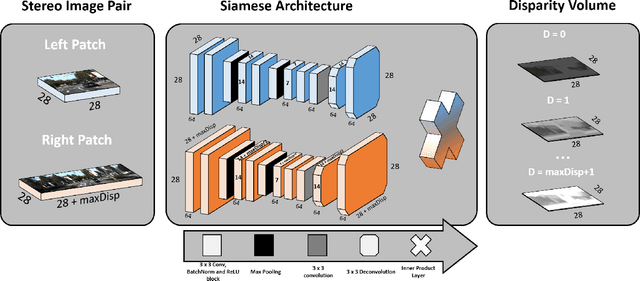
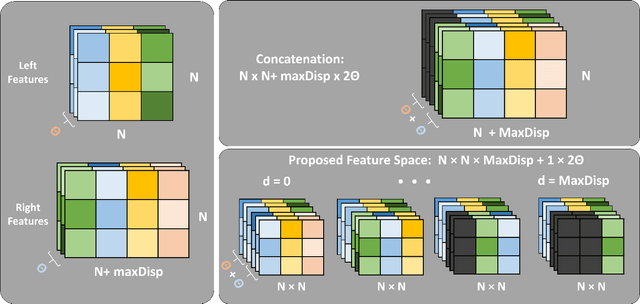
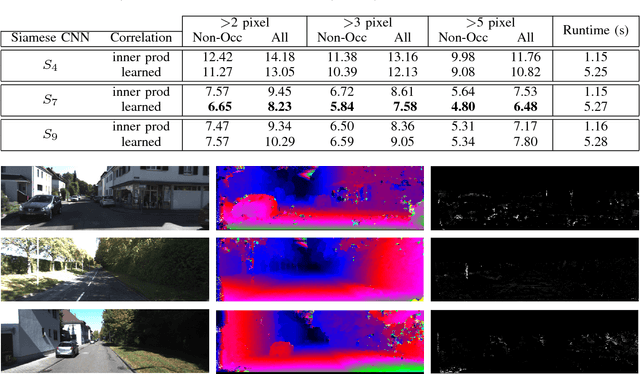
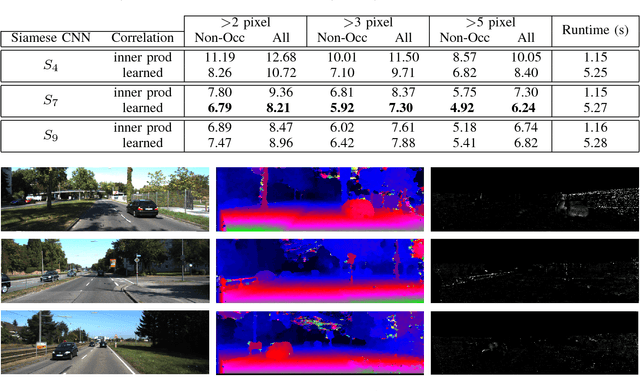
Computational stereo is one of the classical problems in computer vision. Numerous algorithms and solutions have been reported in recent years focusing on developing methods for computing similarity, aggregating it to obtain spatial support and finally optimizing an energy function to find the final disparity. In this paper, we focus on the feature extraction component of stereo matching architecture and we show standard CNNs operation can be used to improve the quality of the features used to find point correspondences. Furthermore, we propose a simple space aggregation that hugely simplifies the correlation learning problem. Our results on benchmark data are compelling and show promising potential even without refining the solution.