 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Depth in Surgical Vision Foundation Models: An Empirical Study of RGB-D Pre-training
Jan 26, 2026Vision foundation models (VFMs) have emerged as powerful tools for surgical scene understanding. However, current approaches predominantly rely on unimodal RGB pre-training, overlooking the complex 3D geometry inherent to surgical environments. Although several architectures support multimodal or geometry-aware inputs in general computer vision, the benefits of incorporating depth information in surgical settings remain underexplored. We conduct a large-scale empirical study comparing eight ViT-based VFMs that differ in pre-training domain, learning objective, and input modality (RGB vs. RGB-D). For pre-training, we use a curated dataset of 1.4 million robotic surgical images paired with depth maps generated from an off-the-shelf network. We evaluate these models under both frozen-backbone and end-to-end fine-tuning protocols across eight surgical datasets spanning object detection, segmentation, depth estimation, and pose estimation. Our experiments yield several consistent findings. Models incorporating explicit geometric tokenization, such as MultiMAE, substantially outperform unimodal baselines across all tasks. Notably, geometric-aware pre-training enables remarkable data efficiency: models fine-tuned on just 25% of labeled data consistently surpass RGB-only models trained on the full dataset. Importantly, these gains require no architectural or runtime changes at inference; depth is used only during pre-training, making adoption straightforward. These findings suggest that multimodal pre-training offers a viable path towards building more capable surgical vision systems.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
SurgPose: a Dataset for Articulated Robotic Surgical Tool Pose Estimation and Tracking
Feb 17, 2025Accurate and efficient surgical robotic tool pose estimation is of fundamental significance to downstream applications such as augmented reality (AR) in surgical training and learning-based autonomous manipulation. While significant advancements have been made in pose estimation for humans and animals, it is still a challenge in surgical robotics due to the scarcity of published data. The relatively large absolute error of the da Vinci end effector kinematics and arduous calibration procedure make calibrated kinematics data collection expensive. Driven by this limitation, we collected a dataset, dubbed SurgPose, providing instance-aware semantic keypoints and skeletons for visual surgical tool pose estimation and tracking. By marking keypoints using ultraviolet (UV) reactive paint, which is invisible under white light and fluorescent under UV light, we execute the same trajectory under different lighting conditions to collect raw videos and keypoint annotations, respectively. The SurgPose dataset consists of approximately 120k surgical instrument instances (80k for training and 40k for validation) of 6 categories. Each instrument instance is labeled with 7 semantic keypoints. Since the videos are collected in stereo pairs, the 2D pose can be lifted to 3D based on stereo-matching depth. In addition to releasing the dataset, we test a few baseline approaches to surgical instrument tracking to demonstrate the utility of SurgPose. More details can be found at surgpose.github.io.
Image Retrieval with Intra-Sweep Representation Learning for Neck Ultrasound Scanning Guidance
Dec 10, 2024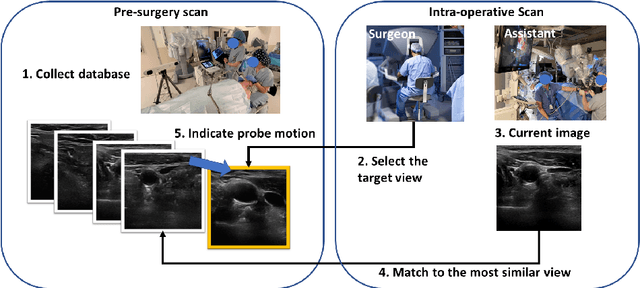

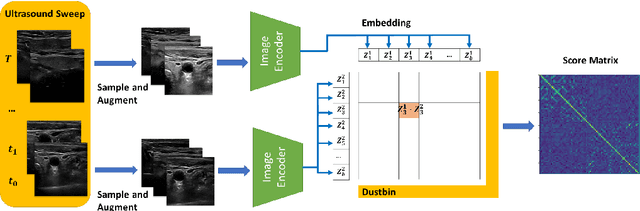

Purpose: Intraoperative ultrasound (US) can enhance real-time visualization in transoral robotic surgery. The surgeon creates a mental map with a pre-operative scan. Then, a surgical assistant performs freehand US scanning during the surgery while the surgeon operates at the remote surgical console. Communicating the target scanning plane in the surgeon's mental map is difficult. Automatic image retrieval can help match intraoperative images to preoperative scans, guiding the assistant to adjust the US probe toward the target plane. Methods: We propose a self-supervised contrastive learning approach to match intraoperative US views to a preoperative image database. We introduce a novel contrastive learning strategy that leverages intra-sweep similarity and US probe location to improve feature encoding. Additionally, our model incorporates a flexible threshold to reject unsatisfactory matches. Results: Our method achieves 92.30% retrieval accuracy on simulated data and outperforms state-of-the-art temporal-based contrastive learning approaches. Our ablation study demonstrates that using probe location in the optimization goal improves image representation, suggesting that semantic information can be extracted from probe location. We also present our approach on real patient data to show the feasibility of the proposed US probe localization system despite tissue deformation from tongue retraction. Conclusion: Our contrastive learning method, which utilizes intra-sweep similarity and US probe location, enhances US image representation learning. We also demonstrate the feasibility of using our image retrieval method to provide neck US localization on real patient US after tongue retraction.
A-MFST: Adaptive Multi-Flow Sparse Tracker for Real-Time Tissue Tracking Under Occlusion
Oct 25, 2024



Purpose: Tissue tracking is critical for downstream tasks in robot-assisted surgery. The Sparse Efficient Neural Depth and Deformation (SENDD) model has previously demonstrated accurate and real-time sparse point tracking, but struggled with occlusion handling. This work extends SENDD to enhance occlusion detection and tracking consistency while maintaining real-time performance. Methods: We use the Segment Anything Model2 (SAM2) to detect and mask occlusions by surgical tools, and we develop and integrate into SENDD an Adaptive Multi-Flow Sparse Tracker (A-MFST) with forward-backward consistency metrics, to enhance occlusion and uncertainty estimation. A-MFST is an unsupervised variant of the Multi-Flow Dense Tracker (MFT). Results: We evaluate our approach on the STIR dataset and demonstrate a significant improvement in tracking accuracy under occlusion, reducing average tracking errors by 12 percent in Mean Endpoint Error (MEE) and showing a 6 percent improvement in the averaged accuracy over thresholds of 4, 8, 16, 32, and 64 pixels. The incorporation of forward-backward consistency further improves the selection of optimal tracking paths, reducing drift and enhancing robustness. Notably, these improvements were achieved without compromising the model's real-time capabilities. Conclusions: Using A-MFST and SAM2, we enhance SENDD's ability to track tissue in real time under instrument and tissue occlusions.
Real-time Surgical Instrument Segmentation in Video Using Point Tracking and Segment Anything
Mar 12, 2024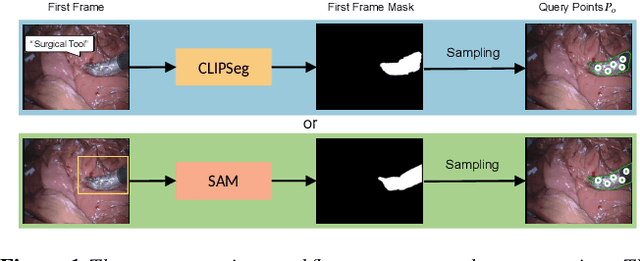
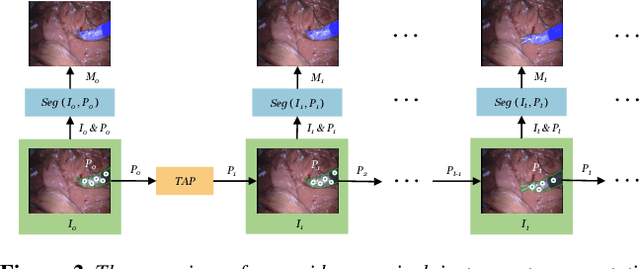
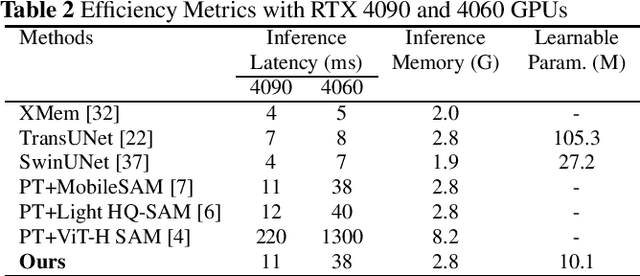
The Segment Anything Model (SAM) is a powerful vision foundation model that is revolutionizing the traditional paradigm of segmentation. Despite this, a reliance on prompting each frame and large computational cost limit its usage in robotically assisted surgery. Applications, such as augmented reality guidance, require little user intervention along with efficient inference to be usable clinically. In this study, we address these limitations by adopting lightweight SAM variants to meet the speed requirement and employing fine-tuning techniques to enhance their generalization in surgical scenes. Recent advancements in Tracking Any Point (TAP) have shown promising results in both accuracy and efficiency, particularly when points are occluded or leave the field of view. Inspired by this progress, we present a novel framework that combines an online point tracker with a lightweight SAM model that is fine-tuned for surgical instrument segmentation. Sparse points within the region of interest are tracked and used to prompt SAM throughout the video sequence, providing temporal consistency. The quantitative results surpass the state-of-the-art semi-supervised video object segmentation method on the EndoVis 2015 dataset, with an over 25 FPS inference speed running on a single GeForce RTX 4060 GPU.
PIPsUS: Self-Supervised Dense Point Tracking in Ultrasound
Mar 08, 2024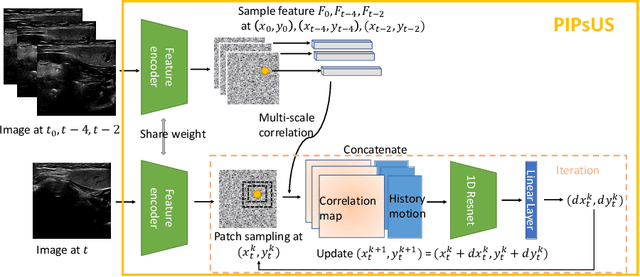
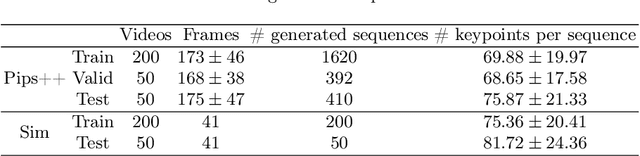
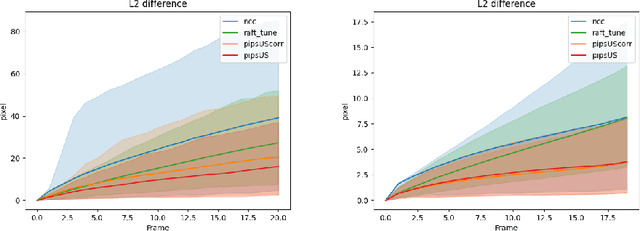
Finding point-level correspondences is a fundamental problem in ultrasound (US), since it can enable US landmark tracking for intraoperative image guidance in different surgeries, including head and neck. Most existing US tracking methods, e.g., those based on optical flow or feature matching, were initially designed for RGB images before being applied to US. Therefore domain shift can impact their performance. Training could be supervised by ground-truth correspondences, but these are expensive to acquire in US. To solve these problems, we propose a self-supervised pixel-level tracking model called PIPsUS. Our model can track an arbitrary number of points in one forward pass and exploits temporal information by considering multiple, instead of just consecutive, frames. We developed a new self-supervised training strategy that utilizes a long-term point-tracking model trained for RGB images as a teacher to guide the model to learn realistic motions and use data augmentation to enforce tracking from US appearance. We evaluate our method on neck and oral US and echocardiography, showing higher point tracking accuracy when compared with fast normalized cross-correlation and tuned optical flow. Code will be available once the paper is accepted.
Tracking and Mapping in Medical Computer Vision: A Review
Oct 17, 2023



As computer vision algorithms are becoming more capable, their applications in clinical systems will become more pervasive. These applications include diagnostics such as colonoscopy and bronchoscopy, guiding biopsies and minimally invasive interventions and surgery, automating instrument motion and providing image guidance using pre-operative scans. Many of these applications depend on the specific visual nature of medical scenes and require designing and applying algorithms to perform in this environment. In this review, we provide an update to the field of camera-based tracking and scene mapping in surgery and diagnostics in medical computer vision. We begin with describing our review process, which results in a final list of 515 papers that we cover. We then give a high-level summary of the state of the art and provide relevant background for those who need tracking and mapping for their clinical applications. We then review datasets provided in the field and the clinical needs therein. Then, we delve in depth into the algorithmic side, and summarize recent developments, which should be especially useful for algorithm designers and to those looking to understand the capability of off-the-shelf methods. We focus on algorithms for deformable environments while also reviewing the essential building blocks in rigid tracking and mapping since there is a large amount of crossover in methods. Finally, we discuss the current state of the tracking and mapping methods along with needs for future algorithms, needs for quantification, and the viability of clinical applications in the field. We conclude that new methods need to be designed or combined to support clinical applications in deformable environments, and more focus needs to be put into collecting datasets for training and evaluation.
STIR: Surgical Tattoos in Infrared
Sep 28, 2023Quantifying performance of methods for tracking and mapping tissue in endoscopic environments is essential for enabling image guidance and automation of medical interventions and surgery. Datasets developed so far either use rigid environments, visible markers, or require annotators to label salient points in videos after collection. These are respectively: not general, visible to algorithms, or costly and error-prone. We introduce a novel labeling methodology along with a dataset that uses said methodology, Surgical Tattoos in Infrared (STIR). STIR has labels that are persistent but invisible to visible spectrum algorithms. This is done by labelling tissue points with IR-flourescent dye, indocyanine green (ICG), and then collecting visible light video clips. STIR comprises hundreds of stereo video clips in both in-vivo and ex-vivo scenes with start and end points labelled in the IR spectrum. With over 3,000 labelled points, STIR will help to quantify and enable better analysis of tracking and mapping methods. After introducing STIR, we analyze multiple different frame-based tracking methods on STIR using both 3D and 2D endpoint error and accuracy metrics. STIR is available at https://dx.doi.org/10.21227/w8g4-g548
SENDD: Sparse Efficient Neural Depth and Deformation for Tissue Tracking
May 10, 2023Deformable tracking and real-time estimation of 3D tissue motion is essential to enable automation and image guidance applications in robotically assisted surgery. Our model, Sparse Efficient Neural Depth and Deformation (SENDD), extends prior 2D tracking work to estimate flow in 3D space. SENDD introduces novel contributions of learned detection, and sparse per-point depth and 3D flow estimation, all with less than half a million parameters. SENDD does this by using graph neural networks of sparse keypoint matches to estimate both depth and 3D flow. We quantify and benchmark SENDD on a comprehensively labelled tissue dataset, and compare it to an equivalent 2D flow model. SENDD performs comparably while enabling applications that 2D flow cannot. SENDD can track points and estimate depth at 10fps on an NVIDIA RTX 4000 for 1280 tracked (query) points and its cost scales linearly with an increasing/decreasing number of points. SENDD enables multiple downstream applications that require 3D motion estimation.