 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIPsUS: Self-Supervised Dense Point Tracking in Ultrasound
Paper and Code
Mar 08, 2024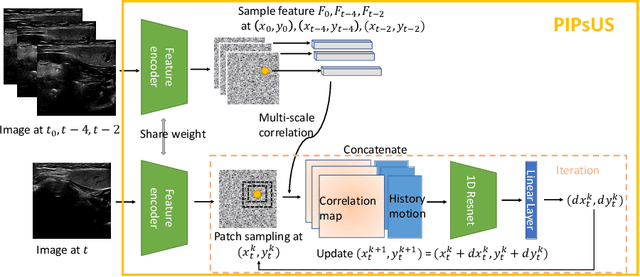
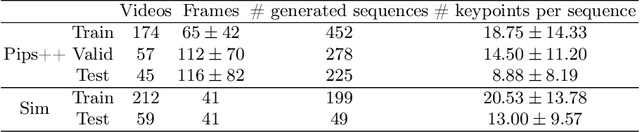
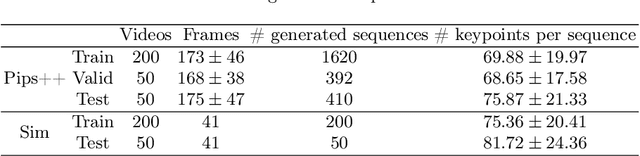
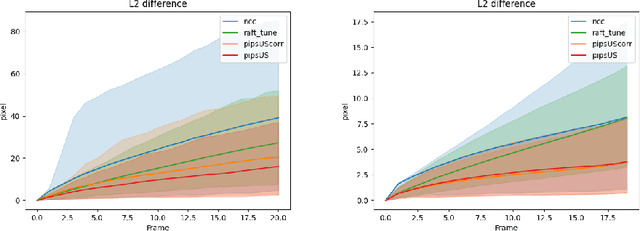
Finding point-level correspondences is a fundamental problem in ultrasound (US), since it can enable US landmark tracking for intraoperative image guidance in different surgeries, including head and neck. Most existing US tracking methods, e.g., those based on optical flow or feature matching, were initially designed for RGB images before being applied to US. Therefore domain shift can impact their performance. Training could be supervised by ground-truth correspondences, but these are expensive to acquire in US. To solve these problems, we propose a self-supervised pixel-level tracking model called PIPsUS. Our model can track an arbitrary number of points in one forward pass and exploits temporal information by considering multiple, instead of just consecutive, frames. We developed a new self-supervised training strategy that utilizes a long-term point-tracking model trained for RGB images as a teacher to guide the model to learn realistic motions and use data augmentation to enforce tracking from US appearance. We evaluate our method on neck and oral US and echocardiography, showing higher point tracking accuracy when compared with fast normalized cross-correlation and tuned optical flow. Code will be available once the paper is accepted.