 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement and Potential Field-Based Patient Modeling for Model-Mediated Tele-ultrasound
Sep 18, 2025Teleoperated ultrasound can improve diagnostic medical imaging access for remote communities. Having accurate force feedback is important for enabling sonographers to apply the appropriate probe contact force to optimize ultrasound image quality. However, large time delays in communication make direct force feedback impractical. Prior work investigated using point cloud-based model-mediated teleoperation and internal potential field models to estimate contact forces and torques. We expand on this by introducing a method to update the internal potential field model of the patient with measured positions and forces for more transparent model-mediated tele-ultrasound. We first generate a point cloud model of the patient's surface and transmit this to the sonographer in a compact data structure. This is converted to a static voxelized volume where each voxel contains a potential field value. These values determine the forces and torques, which are rendered based on overlap between the voxelized volume and a point shell model of the ultrasound transducer. We solve for the potential field using a convex quadratic that combines the spatial Laplace operator with measured forces. This was evaluated on volunteer patients ($n=3$) by computing the accuracy of rendered forces. Results showed the addition of measured forces to the model reduced the force magnitude error by an average of 7.23 N and force vector angle error by an average of 9.37$^{\circ}$ compared to using only Laplace's equation.
AutoCam: Hierarchical Path Planning for an Autonomous Auxiliary Camera in Surgical Robotics
May 15, 2025Incorporating an autonomous auxiliary camera into robot-assisted minimally invasive surgery (RAMIS) enhances spatial awareness and eliminates manual viewpoint control. Existing path planning methods for auxiliary cameras track two-dimensional surgical features but do not simultaneously account for camera orientation, workspace constraints, and robot joint limits. This study presents AutoCam: an automatic auxiliary camera placement method to improve visualization in RAMIS. Implemented on the da Vinci Research Kit, the system uses a priority-based, workspace-constrained control algorithm that combines heuristic geometric placement with nonlinear optimization to ensure robust camera tracking. A user study (N=6) demonstrated that the system maintained 99.84% visibility of a salient feature and achieved a pose error of 4.36 $\pm$ 2.11 degrees and 1.95 $\pm$ 5.66 mm. The controller was computationally efficient, with a loop time of 6.8 $\pm$ 12.8 ms. An additional pilot study (N=6), where novices completed a Fundamentals of Laparoscopic Surgery training task, suggests that users can teleoperate just as effectively from AutoCam's viewpoint as from the endoscope's while still benefiting from AutoCam's improved visual coverage of the scene. These results indicate that an auxiliary camera can be autonomously controlled using the da Vinci patient-side manipulators to track a salient feature, laying the groundwork for new multi-camera visualization methods in RAMIS.
Setup-Invariant Augmented Reality for Teaching by Demonstration with Surgical Robots
Apr 09, 2025Augmented reality (AR) is an effective tool in robotic surgery education as it combines exploratory learning with three-dimensional guidance. However, existing AR systems require expert supervision and do not account for differences in the mentor and mentee robot configurations. To enable novices to train outside the operating room while receiving expert-informed guidance, we present dV-STEAR: an open-source system that plays back task-aligned expert demonstrations without assuming identical setup joint positions between expert and novice. Pose estimation was rigorously quantified, showing a registration error of 3.86 (SD=2.01)mm. In a user study (N=24), dV-STEAR significantly improved novice performance on tasks from the Fundamentals of Laparoscopic Surgery. In a single-handed ring-over-wire task, dV-STEAR increased completion speed (p=0.03) and reduced collision time (p=0.01) compared to dry-lab training alone. During a pick-and-place task, it improved success rates (p=0.004). Across both tasks, participants using dV-STEAR exhibited significantly more balanced hand use and reported lower frustration levels. This work presents a novel educational tool implemented on the da Vinci Research Kit, demonstrates its effectiveness in teaching novices, and builds the foundation for further AR integration into robot-assisted surgery.
Point Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
Instrument-Splatting: Controllable Photorealistic Reconstruction of Surgical Instruments Using Gaussian Splatting
Mar 06, 2025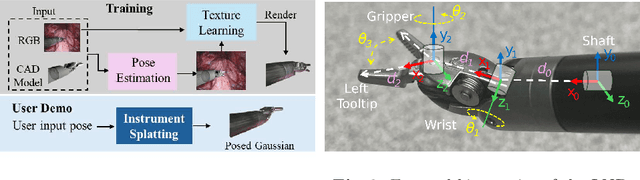
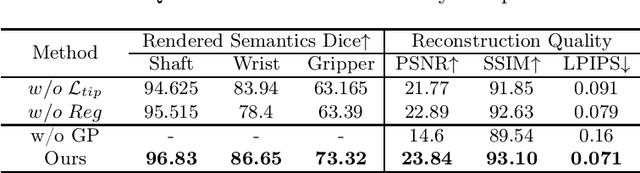
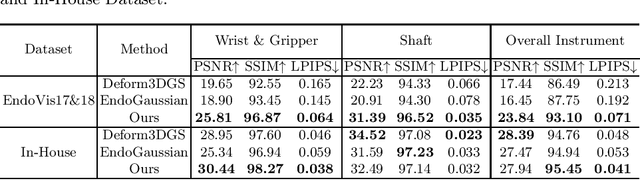
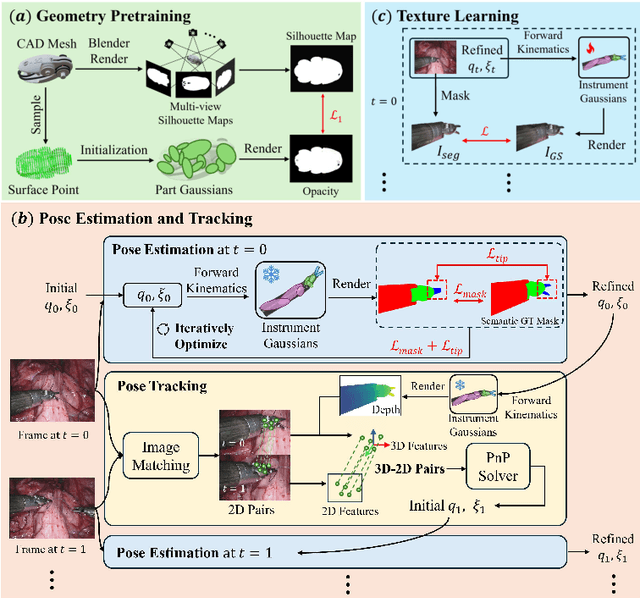
Real2Sim is becoming increasingly important with the rapid development of surgical artificial intelligence (AI) and autonomy. In this work, we propose a novel Real2Sim methodology, \textit{Instrument-Splatting}, that leverages 3D Gaussian Splatting to provide fully controllable 3D reconstruction of surgical instruments from monocular surgical videos. To maintain both high visual fidelity and manipulability, we introduce a geometry pre-training to bind Gaussian point clouds on part mesh with accurate geometric priors and define a forward kinematics to control the Gaussians as flexible as real instruments. Afterward, to handle unposed videos, we design a novel instrument pose tracking method leveraging semantics-embedded Gaussians to robustly refine per-frame instrument poses and joint states in a render-and-compare manner, which allows our instrument Gaussian to accurately learn textures and reach photorealistic rendering. We validated our method on 2 publicly released surgical videos and 4 videos collected on ex vivo tissues and green screens. Quantitative and qualitative evaluations demonstrate the effectiveness and superiority of the proposed method.
Semantic-ICP: Iterative Closest Point for Non-rigid Multi-Organ Point Cloud Registration
Mar 02, 2025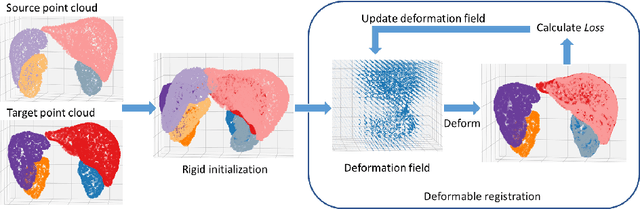
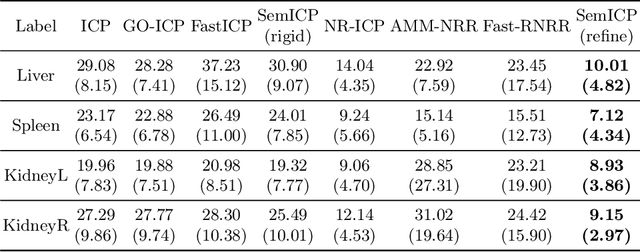
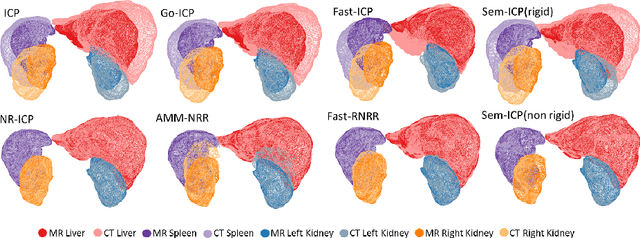
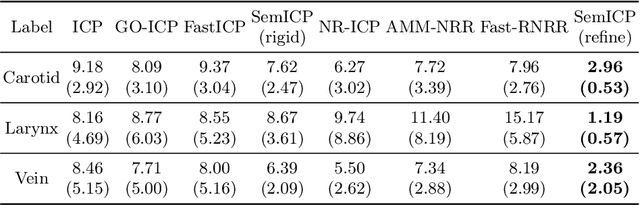
Point cloud registration is important in computer-aided interventions (CAI). While learning-based point cloud registration methods have been developed, their clinical application is hampered by issues of generalizability and explainability. Therefore, classical point cloud registration methods, such as Iterative Closest Point (ICP), are still widely applied in CAI. ICP methods fail to consider that: (1) the points have well-defined semantic meaning, in that each point can be related to a specific anatomical label; (2) the deformation needs to follow biomechanical energy constraints. In this paper, we present a novel semantic ICP (sem-ICP) method that handles multiple point labels and uses linear elastic energy regularization. We use semantic labels to improve the robustness of the closest point matching and propose a new point cloud deformation representation to apply explicit biomechanical energy regularization. Our experiments on the Learn2reg abdominal MR-CT registration dataset and a trans-oral robotic surgery ultrasound-CT registration dataset show that our method improves the Hausdorff distance compared with other state-of-the-art ICP-based registration methods. We also perform a sensitivity study to show that our rigid initialization achieves better convergence with different initializations and visible ratios.
SurgPose: a Dataset for Articulated Robotic Surgical Tool Pose Estimation and Tracking
Feb 17, 2025Accurate and efficient surgical robotic tool pose estimation is of fundamental significance to downstream applications such as augmented reality (AR) in surgical training and learning-based autonomous manipulation. While significant advancements have been made in pose estimation for humans and animals, it is still a challenge in surgical robotics due to the scarcity of published data. The relatively large absolute error of the da Vinci end effector kinematics and arduous calibration procedure make calibrated kinematics data collection expensive. Driven by this limitation, we collected a dataset, dubbed SurgPose, providing instance-aware semantic keypoints and skeletons for visual surgical tool pose estimation and tracking. By marking keypoints using ultraviolet (UV) reactive paint, which is invisible under white light and fluorescent under UV light, we execute the same trajectory under different lighting conditions to collect raw videos and keypoint annotations, respectively. The SurgPose dataset consists of approximately 120k surgical instrument instances (80k for training and 40k for validation) of 6 categories. Each instrument instance is labeled with 7 semantic keypoints. Since the videos are collected in stereo pairs, the 2D pose can be lifted to 3D based on stereo-matching depth. In addition to releasing the dataset, we test a few baseline approaches to surgical instrument tracking to demonstrate the utility of SurgPose. More details can be found at surgpose.github.io.
Image Retrieval with Intra-Sweep Representation Learning for Neck Ultrasound Scanning Guidance
Dec 10, 2024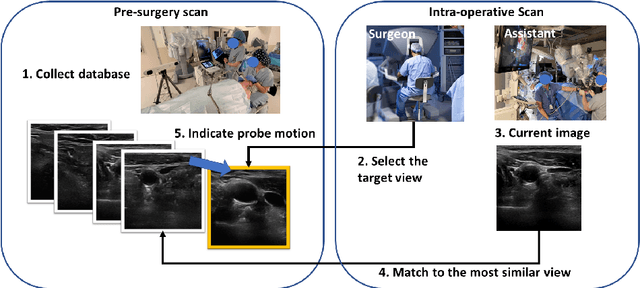

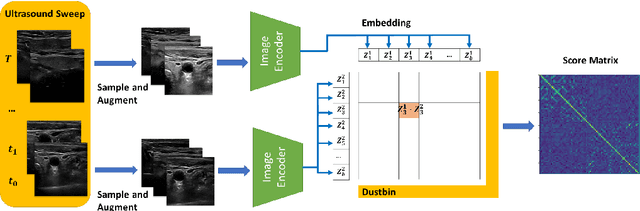

Purpose: Intraoperative ultrasound (US) can enhance real-time visualization in transoral robotic surgery. The surgeon creates a mental map with a pre-operative scan. Then, a surgical assistant performs freehand US scanning during the surgery while the surgeon operates at the remote surgical console. Communicating the target scanning plane in the surgeon's mental map is difficult. Automatic image retrieval can help match intraoperative images to preoperative scans, guiding the assistant to adjust the US probe toward the target plane. Methods: We propose a self-supervised contrastive learning approach to match intraoperative US views to a preoperative image database. We introduce a novel contrastive learning strategy that leverages intra-sweep similarity and US probe location to improve feature encoding. Additionally, our model incorporates a flexible threshold to reject unsatisfactory matches. Results: Our method achieves 92.30% retrieval accuracy on simulated data and outperforms state-of-the-art temporal-based contrastive learning approaches. Our ablation study demonstrates that using probe location in the optimization goal improves image representation, suggesting that semantic information can be extracted from probe location. We also present our approach on real patient data to show the feasibility of the proposed US probe localization system despite tissue deformation from tongue retraction. Conclusion: Our contrastive learning method, which utilizes intra-sweep similarity and US probe location, enhances US image representation learning. We also demonstrate the feasibility of using our image retrieval method to provide neck US localization on real patient US after tongue retraction.
A-MFST: Adaptive Multi-Flow Sparse Tracker for Real-Time Tissue Tracking Under Occlusion
Oct 25, 2024



Purpose: Tissue tracking is critical for downstream tasks in robot-assisted surgery. The Sparse Efficient Neural Depth and Deformation (SENDD) model has previously demonstrated accurate and real-time sparse point tracking, but struggled with occlusion handling. This work extends SENDD to enhance occlusion detection and tracking consistency while maintaining real-time performance. Methods: We use the Segment Anything Model2 (SAM2) to detect and mask occlusions by surgical tools, and we develop and integrate into SENDD an Adaptive Multi-Flow Sparse Tracker (A-MFST) with forward-backward consistency metrics, to enhance occlusion and uncertainty estimation. A-MFST is an unsupervised variant of the Multi-Flow Dense Tracker (MFT). Results: We evaluate our approach on the STIR dataset and demonstrate a significant improvement in tracking accuracy under occlusion, reducing average tracking errors by 12 percent in Mean Endpoint Error (MEE) and showing a 6 percent improvement in the averaged accuracy over thresholds of 4, 8, 16, 32, and 64 pixels. The incorporation of forward-backward consistency further improves the selection of optimal tracking paths, reducing drift and enhancing robustness. Notably, these improvements were achieved without compromising the model's real-time capabilities. Conclusions: Using A-MFST and SAM2, we enhance SENDD's ability to track tissue in real time under instrument and tissue occlusions.
Real-time Surgical Instrument Segmentation in Video Using Point Tracking and Segment Anything
Mar 12, 2024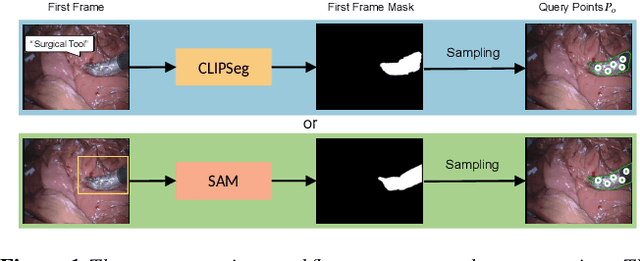
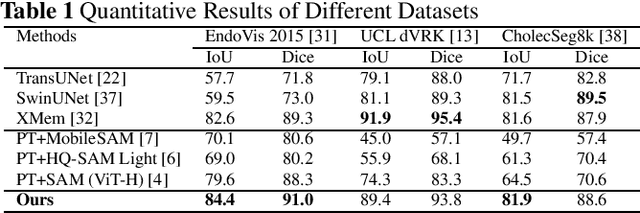
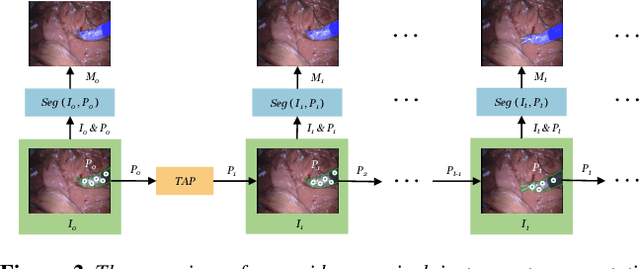
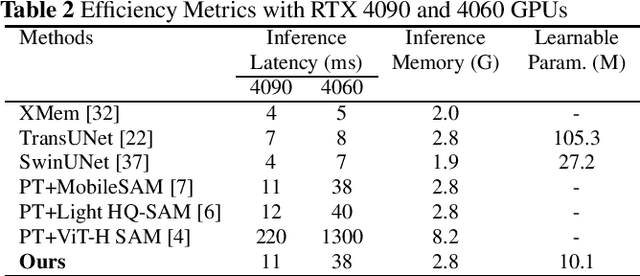
The Segment Anything Model (SAM) is a powerful vision foundation model that is revolutionizing the traditional paradigm of segmentation. Despite this, a reliance on prompting each frame and large computational cost limit its usage in robotically assisted surgery. Applications, such as augmented reality guidance, require little user intervention along with efficient inference to be usable clinically. In this study, we address these limitations by adopting lightweight SAM variants to meet the speed requirement and employing fine-tuning techniques to enhance their generalization in surgical scenes. Recent advancements in Tracking Any Point (TAP) have shown promising results in both accuracy and efficiency, particularly when points are occluded or leave the field of view. Inspired by this progress, we present a novel framework that combines an online point tracker with a lightweight SAM model that is fine-tuned for surgical instrument segmentation. Sparse points within the region of interest are tracked and used to prompt SAM throughout the video sequence, providing temporal consistency. The quantitative results surpass the state-of-the-art semi-supervised video object segmentation method on the EndoVis 2015 dataset, with an over 25 FPS inference speed running on a single GeForce RTX 4060 GPU.