 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstrument-Splatting: Controllable Photorealistic Reconstruction of Surgical Instruments Using Gaussian Splatting
Mar 06, 2025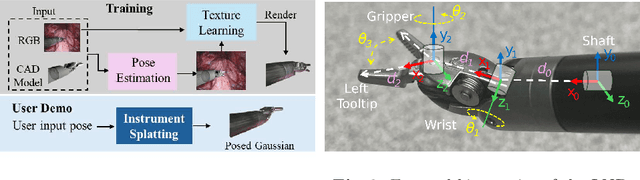
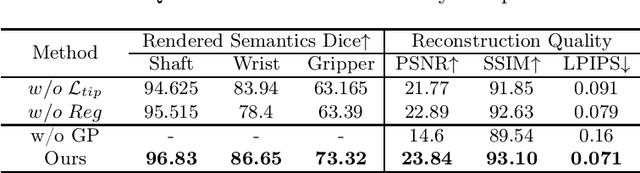
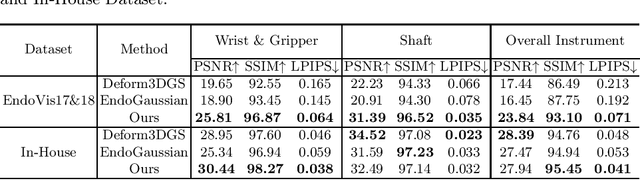
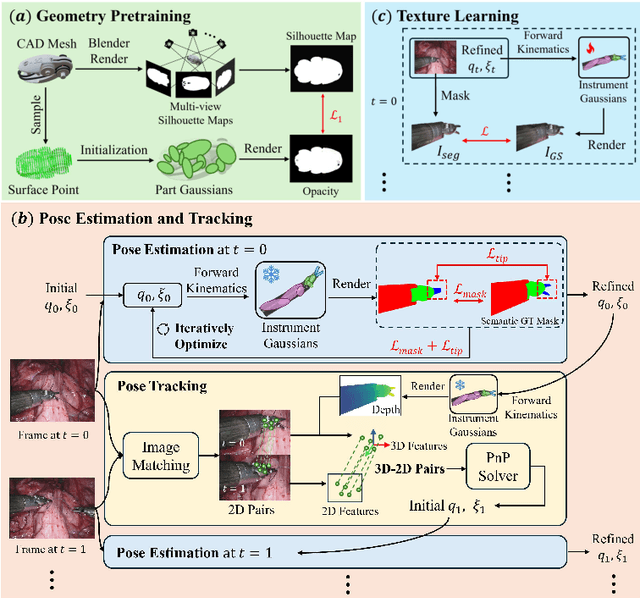
Real2Sim is becoming increasingly important with the rapid development of surgical artificial intelligence (AI) and autonomy. In this work, we propose a novel Real2Sim methodology, \textit{Instrument-Splatting}, that leverages 3D Gaussian Splatting to provide fully controllable 3D reconstruction of surgical instruments from monocular surgical videos. To maintain both high visual fidelity and manipulability, we introduce a geometry pre-training to bind Gaussian point clouds on part mesh with accurate geometric priors and define a forward kinematics to control the Gaussians as flexible as real instruments. Afterward, to handle unposed videos, we design a novel instrument pose tracking method leveraging semantics-embedded Gaussians to robustly refine per-frame instrument poses and joint states in a render-and-compare manner, which allows our instrument Gaussian to accurately learn textures and reach photorealistic rendering. We validated our method on 2 publicly released surgical videos and 4 videos collected on ex vivo tissues and green screens. Quantitative and qualitative evaluations demonstrate the effectiveness and superiority of the proposed method.
Surgical SAM 2: Real-time Segment Anything in Surgical Video by Efficient Frame Pruning
Aug 15, 2024Surgical video segmentation is a critical task in computer-assisted surgery and is vital for enhancing surgical quality and patient outcomes. Recently, the Segment Anything Model 2 (SAM2) framework has shown superior advancements in image and video segmentation. However, SAM2 struggles with efficiency due to the high computational demands of processing high-resolution images and complex and long-range temporal dynamics in surgical videos. To address these challenges, we introduce Surgical SAM 2 (SurgSAM-2), an advanced model to utilize SAM2 with an Efficient Frame Pruning (EFP) mechanism, to facilitate real-time surgical video segmentation. The EFP mechanism dynamically manages the memory bank by selectively retaining only the most informative frames, reducing memory usage and computational cost while maintaining high segmentation accuracy. Our extensive experiments demonstrate that SurgSAM-2 significantly improves both efficiency and segmentation accuracy compared to the vanilla SAM2. Remarkably, SurgSAM-2 achieves a 3$\times$ FPS compared with SAM2, while also delivering state-of-the-art performance after fine-tuning with lower-resolution data. These advancements establish SurgSAM-2 as a leading model for surgical video analysis, making real-time surgical video segmentation in resource-constrained environments a feasible reality.
Boosting 3D Object Detection by Simulating Multimodality on Point Clouds
Jun 30, 2022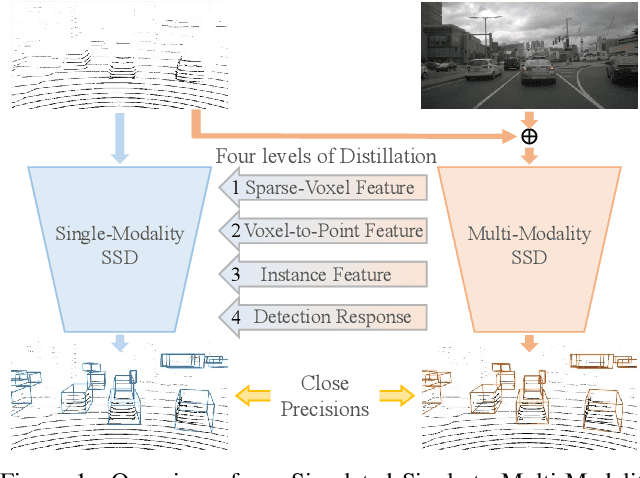
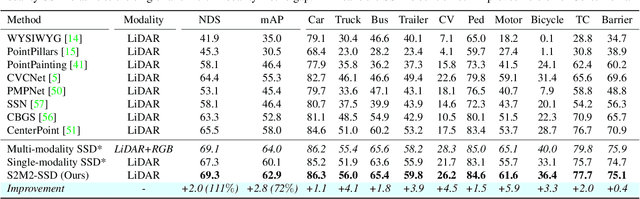

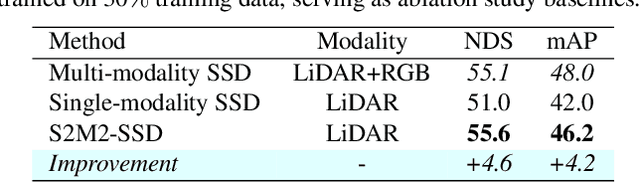
This paper presents a new approach to boost a single-modality (LiDAR) 3D object detector by teaching it to simulate features and responses that follow a multi-modality (LiDAR-image) detector. The approach needs LiDAR-image data only when training the single-modality detector, and once well-trained, it only needs LiDAR data at inference. We design a novel framework to realize the approach: response distillation to focus on the crucial response samples and avoid the background samples; sparse-voxel distillation to learn voxel semantics and relations from the estimated crucial voxels; a fine-grained voxel-to-point distillation to better attend to features of small and distant objects; and instance distillation to further enhance the deep-feature consistency. Experimental results on the nuScenes dataset show that our approach outperforms all SOTA LiDAR-only 3D detectors and even surpasses the baseline LiDAR-image detector on the key NDS metric, filling 72% mAP gap between the single- and multi-modality detectors.