 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Machine Learning for Cavitation Intensity Recognition in Complex Industrial Systems
Nov 19, 2025Cavitation intensity recognition (CIR) is a critical technology for detecting and evaluating cavitation phenomena in hydraulic machinery, with significant implications for operational safety, performance optimization, and maintenance cost reduction in complex industrial systems. Despite substantial research progress, a comprehensive review that systematically traces the development trajectory and provides explicit guidance for future research is still lacking. To bridge this gap, this paper presents a thorough review and analysis of hundreds of publications on intelligent CIR across various types of mechanical equipment from 2002 to 2025, summarizing its technological evolution and offering insights for future development. The early stages are dominated by traditional machine learning approaches that relied on manually engineered features under the guidance of domain expert knowledge. The advent of deep learning has driven the development of end-to-end models capable of automatically extracting features from multi-source signals, thereby significantly improving recognition performance and robustness. Recently, physical informed diagnostic models have been proposed to embed domain knowledge into deep learning models, which can enhance interpretability and cross-condition generalization. In the future, transfer learning, multi-modal fusion, lightweight network architectures, and the deployment of industrial agents are expected to propel CIR technology into a new stage, addressing challenges in multi-source data acquisition, standardized evaluation, and industrial implementation. The paper aims to systematically outline the evolution of CIR technology and highlight the emerging trend of integrating deep learning with physical knowledge. This provides a significant reference for researchers and practitioners in the field of intelligent cavitation diagnosis in complex industrial systems.
ReSurgSAM2: Referring Segment Anything in Surgical Video via Credible Long-term Tracking
May 13, 2025Surgical scene segmentation is critical in computer-assisted surgery and is vital for enhancing surgical quality and patient outcomes. Recently, referring surgical segmentation is emerging, given its advantage of providing surgeons with an interactive experience to segment the target object. However, existing methods are limited by low efficiency and short-term tracking, hindering their applicability in complex real-world surgical scenarios. In this paper, we introduce ReSurgSAM2, a two-stage surgical referring segmentation framework that leverages Segment Anything Model 2 to perform text-referred target detection, followed by tracking with reliable initial frame identification and diversity-driven long-term memory. For the detection stage, we propose a cross-modal spatial-temporal Mamba to generate precise detection and segmentation results. Based on these results, our credible initial frame selection strategy identifies the reliable frame for the subsequent tracking. Upon selecting the initial frame, our method transitions to the tracking stage, where it incorporates a diversity-driven memory mechanism that maintains a credible and diverse memory bank, ensuring consistent long-term tracking. Extensive experiments demonstrate that ReSurgSAM2 achieves substantial improvements in accuracy and efficiency compared to existing methods, operating in real-time at 61.2 FPS. Our code and datasets will be available at https://github.com/jinlab-imvr/ReSurgSAM2.
HC$^3$L-Diff: Hybrid conditional latent diffusion with high frequency enhancement for CBCT-to-CT synthesis
Nov 03, 2024Background: Cone-beam computed tomography (CBCT) plays a crucial role in image-guided radiotherapy, but artifacts and noise make them unsuitable for accurate dose calculation. Artificial intelligence methods have shown promise in enhancing CBCT quality to produce synthetic CT (sCT) images. However, existing methods either produce images of suboptimal quality or incur excessive time costs, failing to satisfy clinical practice standards. Methods and materials: We propose a novel hybrid conditional latent diffusion model for efficient and accurate CBCT-to-CT synthesis, named HC$^3$L-Diff. We employ the Unified Feature Encoder (UFE) to compress images into a low-dimensional latent space, thereby optimizing computational efficiency. Beyond the use of CBCT images, we propose integrating its high-frequency knowledge as a hybrid condition to guide the diffusion model in generating sCT images with preserved structural details. This high-frequency information is captured using our designed High-Frequency Extractor (HFE). During inference, we utilize denoising diffusion implicit model to facilitate rapid sampling. We construct a new in-house prostate dataset with paired CBCT and CT to validate the effectiveness of our method. Result: Extensive experimental results demonstrate that our approach outperforms state-of-the-art methods in terms of sCT quality and generation efficiency. Moreover, our medical physicist conducts the dosimetric evaluations to validate the benefit of our method in practical dose calculation, achieving a remarkable 93.8% gamma passing rate with a 2%/2mm criterion, superior to other methods. Conclusion: The proposed HC$^3$L-Diff can efficiently achieve high-quality CBCT-to-CT synthesis in only over 2 mins per patient. Its promising performance in dose calculation shows great potential for enhancing real-world adaptive radiotherapy.
Performance Analysis of Pair-wise Symbol Detection in Uplink NOMA-ISaC Systems
Aug 30, 2024



This paper investigates the bit error rate (BER) and outage probability performance of integrated sensing and communication (ISaC) in uplink non-orthogonal multiple access (NOMA) based Internet of Things (IoT) systems. Specifically, we consider an ISaC system where the radar signal is designed to be orthogonal to the communication signal over two symbol periods so that its interference on the communication signal is completely eliminated when detecting the data in pairs of consecutive symbols. This is akin to multi-symbol rate NOMA systems except in this case as the radar bears no data, its waveform is manipulated to be orthogonal to the transmitted communication signal. To eliminate potential decision ambiguity during the pair-wise data detection, a constant phase-offset between adjacent communication symbols is applied at the transmitter. The performance of such a system is analyzed through deriving analytical expressions for the exact BER of zero-forcing (ZF) based receivers. In addition, close-form expressions for the upper BER bound and the outage probability for both ZF and the joint maximum likelihood (JML) receivers are presented. The results show that the derived expressions are perfectly matched with the simulation results. The obtained expressions provide an insight into the performance of this novel ISaC system including demonstrating the impact of various parameters and showing how the ZF receiver provides a useful trade-off between performance and complexity relative to the JML receiver.
Surgical SAM 2: Real-time Segment Anything in Surgical Video by Efficient Frame Pruning
Aug 15, 2024Surgical video segmentation is a critical task in computer-assisted surgery and is vital for enhancing surgical quality and patient outcomes. Recently, the Segment Anything Model 2 (SAM2) framework has shown superior advancements in image and video segmentation. However, SAM2 struggles with efficiency due to the high computational demands of processing high-resolution images and complex and long-range temporal dynamics in surgical videos. To address these challenges, we introduce Surgical SAM 2 (SurgSAM-2), an advanced model to utilize SAM2 with an Efficient Frame Pruning (EFP) mechanism, to facilitate real-time surgical video segmentation. The EFP mechanism dynamically manages the memory bank by selectively retaining only the most informative frames, reducing memory usage and computational cost while maintaining high segmentation accuracy. Our extensive experiments demonstrate that SurgSAM-2 significantly improves both efficiency and segmentation accuracy compared to the vanilla SAM2. Remarkably, SurgSAM-2 achieves a 3$\times$ FPS compared with SAM2, while also delivering state-of-the-art performance after fine-tuning with lower-resolution data. These advancements establish SurgSAM-2 as a leading model for surgical video analysis, making real-time surgical video segmentation in resource-constrained environments a feasible reality.
Drag Your Noise: Interactive Point-based Editing via Diffusion Semantic Propagation
Apr 01, 2024
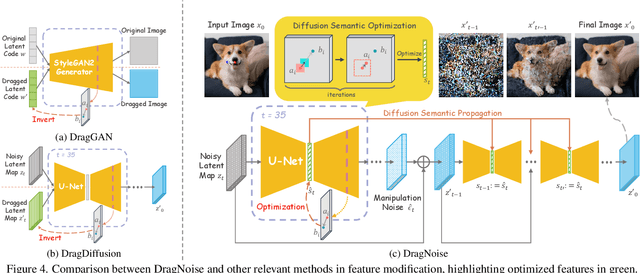

Point-based interactive editing serves as an essential tool to complement the controllability of existing generative models. A concurrent work, DragDiffusion, updates the diffusion latent map in response to user inputs, causing global latent map alterations. This results in imprecise preservation of the original content and unsuccessful editing due to gradient vanishing. In contrast, we present DragNoise, offering robust and accelerated editing without retracing the latent map. The core rationale of DragNoise lies in utilizing the predicted noise output of each U-Net as a semantic editor. This approach is grounded in two critical observations: firstly, the bottleneck features of U-Net inherently possess semantically rich features ideal for interactive editing; secondly, high-level semantics, established early in the denoising process, show minimal variation in subsequent stages. Leveraging these insights, DragNoise edits diffusion semantics in a single denoising step and efficiently propagates these changes, ensuring stability and efficiency in diffusion editing. Comparative experiments reveal that DragNoise achieves superior control and semantic retention, reducing the optimization time by over 50% compared to DragDiffusion. Our codes are available at https://github.com/haofengl/DragNoise.
A Generic Fundus Image Enhancement Network Boosted by Frequency Self-supervised Representation Learning
Sep 02, 2023



Fundus photography is prone to suffer from image quality degradation that impacts clinical examination performed by ophthalmologists or intelligent systems. Though enhancement algorithms have been developed to promote fundus observation on degraded images, high data demands and limited applicability hinder their clinical deployment. To circumvent this bottleneck, a generic fundus image enhancement network (GFE-Net) is developed in this study to robustly correct unknown fundus images without supervised or extra data. Levering image frequency information, self-supervised representation learning is conducted to learn robust structure-aware representations from degraded images. Then with a seamless architecture that couples representation learning and image enhancement, GFE-Net can accurately correct fundus images and meanwhile preserve retinal structures. Comprehensive experiments are implemented to demonstrate the effectiveness and advantages of GFE-Net. Compared with state-of-the-art algorithms, GFE-Net achieves superior performance in data dependency, enhancement performance, deployment efficiency, and scale generalizability. Follow-up fundus image analysis is also facilitated by GFE-Net, whose modules are respectively verified to be effective for image enhancement.
Degradation-invariant Enhancement of Fundus Images via Pyramid Constraint Network
Oct 18, 2022As an economical and efficient fundus imaging modality, retinal fundus images have been widely adopted in clinical fundus examination. Unfortunately, fundus images often suffer from quality degradation caused by imaging interferences, leading to misdiagnosis. Despite impressive enhancement performances that state-of-the-art methods have achieved, challenges remain in clinical scenarios. For boosting the clinical deployment of fundus image enhancement, this paper proposes the pyramid constraint to develop a degradation-invariant enhancement network (PCE-Net), which mitigates the demand for clinical data and stably enhances unknown data. Firstly, high-quality images are randomly degraded to form sequences of low-quality ones sharing the same content (SeqLCs). Then individual low-quality images are decomposed to Laplacian pyramid features (LPF) as the multi-level input for the enhancement. Subsequently, a feature pyramid constraint (FPC) for the sequence is introduced to enforce the PCE-Net to learn a degradation-invariant model. Extensive experiments have been conducted under the evaluation metrics of enhancement and segmentation. The effectiveness of the PCE-Net was demonstrated in comparison with state-of-the-art methods and the ablation study. The source code of this study is publicly available at https://github.com/HeverLaw/PCENet-Image-Enhancement.
Structure-consistent Restoration Network for Cataract Fundus Image Enhancement
Jun 09, 2022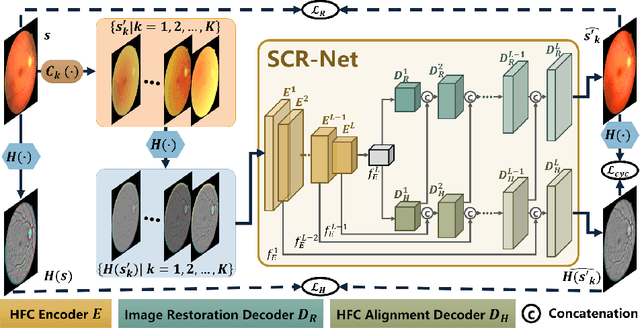

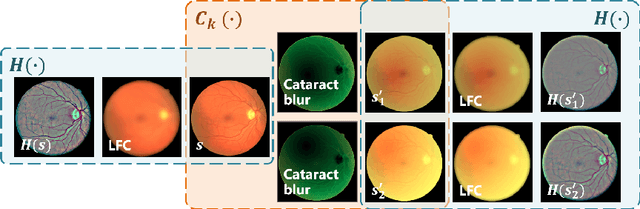

Fundus photography is a routine examination in clinics to diagnose and monitor ocular diseases. However, for cataract patients, the fundus image always suffers quality degradation caused by the clouding lens. The degradation prevents reliable diagnosis by ophthalmologists or computer-aided systems. To improve the certainty in clinical diagnosis, restoration algorithms have been proposed to enhance the quality of fundus images. Unfortunately, challenges remain in the deployment of these algorithms, such as collecting sufficient training data and preserving retinal structures. In this paper, to circumvent the strict deployment requirement, a structure-consistent restoration network (SCR-Net) for cataract fundus images is developed from synthesized data that shares an identical structure. A cataract simulation model is firstly designed to collect synthesized cataract sets (SCS) formed by cataract fundus images sharing identical structures. Then high-frequency components (HFCs) are extracted from the SCS to constrain structure consistency such that the structure preservation in SCR-Net is enforced. The experiments demonstrate the effectiveness of SCR-Net in the comparison with state-of-the-art methods and the follow-up clinical applications. The code is available at https://github.com/liamheng/ArcNet-Medical-Image-Enhancement.
An Annotation-free Restoration Network for Cataractous Fundus Images
Mar 15, 2022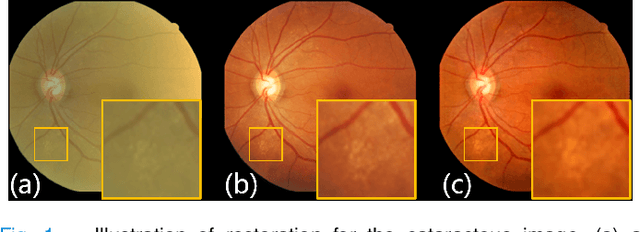

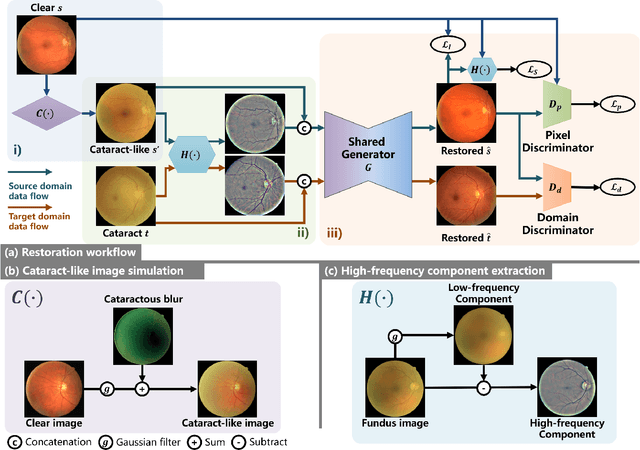

Cataracts are the leading cause of vision loss worldwide. Restoration algorithms are developed to improve the readability of cataract fundus images in order to increase the certainty in diagnosis and treatment for cataract patients. Unfortunately, the requirement of annotation limits the application of these algorithms in clinics. This paper proposes a network to annotation-freely restore cataractous fundus images (ArcNet) so as to boost the clinical practicability of restoration. Annotations are unnecessary in ArcNet, where the high-frequency component is extracted from fundus images to replace segmentation in the preservation of retinal structures. The restoration model is learned from the synthesized images and adapted to real cataract images. Extensive experiments are implemented to verify the performance and effectiveness of ArcNet. Favorable performance is achieved using ArcNet against state-of-the-art algorithms, and the diagnosis of ocular fundus diseases in cataract patients is promoted by ArcNet. The capability of properly restoring cataractous images in the absence of annotated data promises the proposed algorithm outstanding clinical practicability.