 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMBA: 4D Radar Mapping by Bundle Adjustment
May 24, 20264D radar is increasingly attractive for robotic mapping because it provides range, azimuth, elevation, and Doppler measurements while remaining robust in adverse visibility conditions. Although recent radar and radar--inertial odometry methods have achieved promising online state estimation performance, offline global map refinement for 4D radar remains underexplored. This paper presents RAMBA, a radar bundle-adjustment framework for globally consistent 4D radar mapping. Given initial poses and radar frames from a radar--inertial odometry front-end, RAMBA jointly refines radar frame states using covariance-weighted geometric residuals, IMU preintegration factors, and radar ego-velocity constraints. The geometric residuals extend pairwise GICP to a multi-frame optimization by forming voxel-based correspondences across selected frames and weighting each residual with point covariances. To improve robustness against drift and revisits, RAMBA enforces temporal consistency during correspondence formation while explicitly supporting loop-closure constraints. Experiments on the ColoRadar and SNAIL Radar datasets show that RAMBA improves map consistency and usually enhances trajectory accuracy over radar--inertial odometry and pose-graph optimization baselines.
Route Before Retrieve: Activating Latent Routing Abilities of LLMs for RAG vs. Long-Context Selection
May 11, 2026Recent advances in large language models (LLMs) have expanded the context window to beyond 128K tokens, enabling long-document understanding and multi-source reasoning. A key challenge, however, lies in choosing between retrieval-augmented generation (RAG) and long-context (LC) strategies: RAG is efficient but constrained by retrieval quality, while LC supports global reasoning at higher cost and with position sensitivity. Existing methods such as Self-Route adopt failure-driven fallback from RAG to LC, but remain passive, inefficient, and hard to interpret. We propose Pre-Route, a proactive routing framework that performs structured reasoning before answering. Using lightweight metadata (e.g., document type, length, initial snippet), Pre-Route enables task analysis, coverage estimation, and information-need prediction, producing explainable and cost-efficient routing decisions. Our study shows three key findings: (i) LLMs possess latent routing ability that can be reliably elicited with guidelines, allowing single-sample performance to approach that of multi-sample (Best-of-N) results; (ii) linear probes reveal that structured prompts sharpen the separability of the "optimal routing dimension" in representation space; and (iii) distillation transfers this reasoning structure to smaller models for lightweight deployment. Experiments on LaRA (in-domain) and LongBench-v2 (OOD) confirm that Pre-Route outperforms Always-RAG, Always-LC, and Self-Route baselines, achieving superior overall cost-effectiveness.
LASAR: Latent Adaptive Semantic Aligned Reasoning for Generative Recommendation
May 11, 2026Large Language Models (LLMs) have demonstrated powerful reasoning capabilities through Chain-of-Thought (CoT) in various tasks, yet the inefficiency of token-by-token generation hinders real-world deployment in latency-sensitive recommender systems. Latent reasoning has emerged as an effective paradigm in LLMs, performing multi-step inference in a continuous hidden-state space to achieve stronger reasoning at lower cost. However, this paradigm remains underexplored in mainstream generative recommendation. Adapting it reveals three unique challenges: (1) the gap between prior-less Semantic ID (SID) symbols and continuous latent reasoning - SIDs lack pre-trained semantics, hindering joint optimization; (2) representation drift due to a lack of reasoning chain supervision; and (3) the suboptimality of applying a globally fixed reasoning depth. To address these, we propose LASAR (Latent Adaptive Semantic Aligned Reasoning), an SFT-then-RL framework. First, we bridge this gap via two-stage training: Stage 1 grounds SID semantics before Stage 2 introduces latent reasoning, ensuring efficient convergence. Second, we mitigate representation drift through explicit CoT semantic alignment. Step-wise bidirectional KL divergence constrains the latent reasoning trajectory using hidden-state anchors extracted from CoT text, while a Policy Head predicts per-sample reasoning depth. Third, during the GRPO-based RL phase, terminal-only KL alignment accommodates variable-length reasoning, and REINFORCE optimizes the Policy Head to dynamically allocate steps. This nearly halves the average latent step count while simultaneously improving recommendation quality. Experiments on three real-world datasets demonstrate that LASAR outperforms all baselines. It adds marginal inference latency and is roughly 20 times faster than generating explicit CoT text.
Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design Choices
Apr 05, 2026Effective item identifiers (IDs) are an important component for recommender systems (RecSys) in practice, and are commonly adopted in many use cases such as retrieval and ranking. IDs can encode collaborative filtering signals within training data, such that RecSys models can extrapolate during the inference and personalize the prediction based on users' behavioral histories. Recently, Semantic IDs (SIDs) have become a trending paradigm for RecSys. In comparison to the conventional atomic ID, an SID is an ordered list of codes, derived from tokenizers such as residual quantization, applied to semantic representations commonly extracted from foundation models or collaborative signals. SIDs have drastically smaller cardinality than the atomic counterpart, and induce semantic clustering in the ID space. At Snapchat, we apply SIDs as auxiliary features for ranking models, and also explore SIDs as additional retrieval sources in different ML applications. In this paper, we discuss practical technical challenges we encountered while applying SIDs, experiments we have conducted, and design choices we have iterated to mitigate these challenges. Backed by promising offline results on both internal data and academic benchmarks as well as online A/B studies, SID variants have been launched in multiple production models with positive metrics impact.
Faithful Contouring: Near-Lossless 3D Voxel Representation Free from Iso-surface
Nov 12, 2025



Accurate and efficient voxelized representations of 3D meshes are the foundation of 3D reconstruction and generation. However, existing representations based on iso-surface heavily rely on water-tightening or rendering optimization, which inevitably compromise geometric fidelity. We propose Faithful Contouring, a sparse voxelized representation that supports 2048+ resolutions for arbitrary meshes, requiring neither converting meshes to field functions nor extracting the isosurface during remeshing. It achieves near-lossless fidelity by preserving sharpness and internal structures, even for challenging cases with complex geometry and topology. The proposed method also shows flexibility for texturing, manipulation, and editing. Beyond representation, we design a dual-mode autoencoder for Faithful Contouring, enabling scalable and detail-preserving shape reconstruction. Extensive experiments show that Faithful Contouring surpasses existing methods in accuracy and efficiency for both representation and reconstruction. For direct representation, it achieves distance errors at the $10^{-5}$ level; for mesh reconstruction, it yields a 93\% reduction in Chamfer Distance and a 35\% improvement in F-score over strong baselines, confirming superior fidelity as a representation for 3D learning tasks.
Ultra3D: Efficient and High-Fidelity 3D Generation with Part Attention
Jul 23, 2025



Recent advances in sparse voxel representations have significantly improved the quality of 3D content generation, enabling high-resolution modeling with fine-grained geometry. However, existing frameworks suffer from severe computational inefficiencies due to the quadratic complexity of attention mechanisms in their two-stage diffusion pipelines. In this work, we propose Ultra3D, an efficient 3D generation framework that significantly accelerates sparse voxel modeling without compromising quality. Our method leverages the compact VecSet representation to efficiently generate a coarse object layout in the first stage, reducing token count and accelerating voxel coordinate prediction. To refine per-voxel latent features in the second stage, we introduce Part Attention, a geometry-aware localized attention mechanism that restricts attention computation within semantically consistent part regions. This design preserves structural continuity while avoiding unnecessary global attention, achieving up to 6.7x speed-up in latent generation. To support this mechanism, we construct a scalable part annotation pipeline that converts raw meshes into part-labeled sparse voxels. Extensive experiments demonstrate that Ultra3D supports high-resolution 3D generation at 1024 resolution and achieves state-of-the-art performance in both visual fidelity and user preference.
CDC: Causal Domain Clustering for Multi-Domain Recommendation
Jul 09, 2025Multi-domain recommendation leverages domain-general knowledge to improve recommendations across several domains. However, as platforms expand to dozens or hundreds of scenarios, training all domains in a unified model leads to performance degradation due to significant inter-domain differences. Existing domain grouping methods, based on business logic or data similarities, often fail to capture the true transfer relationships required for optimal grouping. To effectively cluster domains, we propose Causal Domain Clustering (CDC). CDC models domain transfer patterns within a large number of domains using two distinct effects: the Isolated Domain Affinity Matrix for modeling non-interactive domain transfers, and the Hybrid Domain Affinity Matrix for considering dynamic domain synergy or interference under joint training. To integrate these two transfer effects, we introduce causal discovery to calculate a cohesion-based coefficient that adaptively balances their contributions. A Co-Optimized Dynamic Clustering algorithm iteratively optimizes target domain clustering and source domain selection for training. CDC significantly enhances performance across over 50 domains on public datasets and in industrial settings, achieving a 4.9% increase in online eCPM. Code is available at https://github.com/Chrissie-Law/Causal-Domain-Clustering-for-Multi-Domain-Recommendation
DeepMesh: Auto-Regressive Artist-mesh Creation with Reinforcement Learning
Mar 19, 2025



Triangle meshes play a crucial role in 3D applications for efficient manipulation and rendering. While auto-regressive methods generate structured meshes by predicting discrete vertex tokens, they are often constrained by limited face counts and mesh incompleteness. To address these challenges, we propose DeepMesh, a framework that optimizes mesh generation through two key innovations: (1) an efficient pre-training strategy incorporating a novel tokenization algorithm, along with improvements in data curation and processing, and (2) the introduction of Reinforcement Learning (RL) into 3D mesh generation to achieve human preference alignment via Direct Preference Optimization (DPO). We design a scoring standard that combines human evaluation with 3D metrics to collect preference pairs for DPO, ensuring both visual appeal and geometric accuracy. Conditioned on point clouds and images, DeepMesh generates meshes with intricate details and precise topology, outperforming state-of-the-art methods in both precision and quality. Project page: https://zhaorw02.github.io/DeepMesh/
MagicArticulate: Make Your 3D Models Articulation-Ready
Feb 18, 2025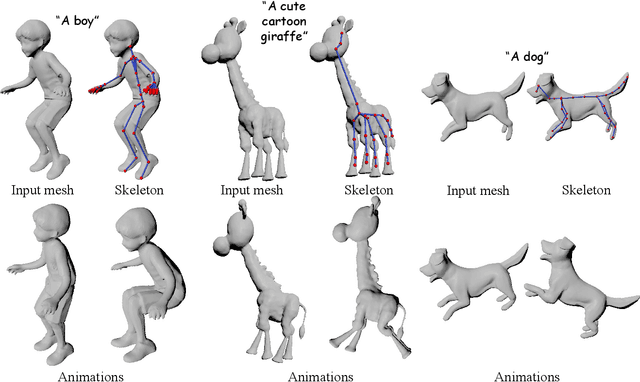
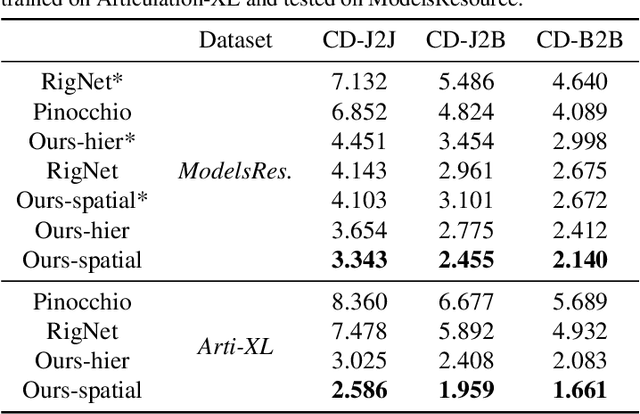
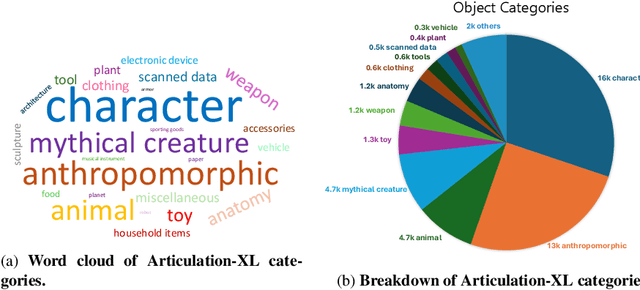
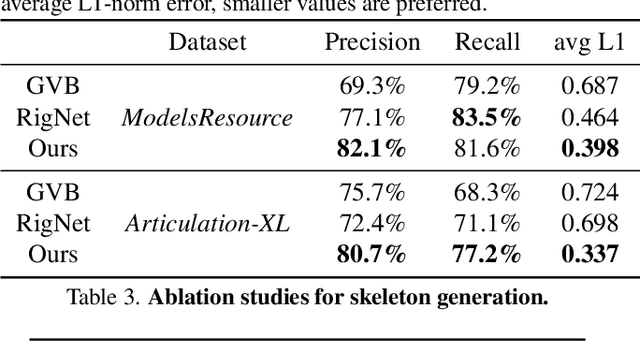
With the explosive growth of 3D content creation, there is an increasing demand for automatically converting static 3D models into articulation-ready versions that support realistic animation. Traditional approaches rely heavily on manual annotation, which is both time-consuming and labor-intensive. Moreover, the lack of large-scale benchmarks has hindered the development of learning-based solutions. In this work, we present MagicArticulate, an effective framework that automatically transforms static 3D models into articulation-ready assets. Our key contributions are threefold. First, we introduce Articulation-XL, a large-scale benchmark containing over 33k 3D models with high-quality articulation annotations, carefully curated from Objaverse-XL. Second, we propose a novel skeleton generation method that formulates the task as a sequence modeling problem, leveraging an auto-regressive transformer to naturally handle varying numbers of bones or joints within skeletons and their inherent dependencies across different 3D models. Third, we predict skinning weights using a functional diffusion process that incorporates volumetric geodesic distance priors between vertices and joints. Extensive experiments demonstrate that MagicArticulate significantly outperforms existing methods across diverse object categories, achieving high-quality articulation that enables realistic animation. Project page: https://chaoyuesong.github.io/MagicArticulate.
One for Dozens: Adaptive REcommendation for All Domains with Counterfactual Augmentation
Dec 16, 2024



Multi-domain recommendation (MDR) aims to enhance recommendation performance across various domains. However, real-world recommender systems in online platforms often need to handle dozens or even hundreds of domains, far exceeding the capabilities of traditional MDR algorithms, which typically focus on fewer than five domains. Key challenges include a substantial increase in parameter count, high maintenance costs, and intricate knowledge transfer patterns across domains. Furthermore, minor domains often suffer from data sparsity, leading to inadequate training in classical methods. To address these issues, we propose Adaptive REcommendation for All Domains with counterfactual augmentation (AREAD). AREAD employs a hierarchical structure with a limited number of expert networks at several layers, to effectively capture domain knowledge at different granularities. To adaptively capture the knowledge transfer pattern across domains, we generate and iteratively prune a hierarchical expert network selection mask for each domain during training. Additionally, counterfactual assumptions are used to augment data in minor domains, supporting their iterative mask pruning. Our experiments on two public datasets, each encompassing over twenty domains, demonstrate AREAD's effectiveness, especially in data-sparse domains. Source code is available at https://github.com/Chrissie-Law/AREAD-Multi-Domain-Recommendation.