 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHouseCrafter: Lifting Floorplans to 3D Scenes with 2D Diffusion Model
Jun 28, 2024



We introduce HouseCrafter, a novel approach that can lift a floorplan into a complete large 3D indoor scene (e.g., a house). Our key insight is to adapt a 2D diffusion model, which is trained on web-scale images, to generate consistent multi-view color (RGB) and depth (D) images across different locations of the scene. Specifically, the RGB-D images are generated autoregressively in a batch-wise manner along sampled locations based on the floorplan, where previously generated images are used as condition to the diffusion model to produce images at nearby locations. The global floorplan and attention design in the diffusion model ensures the consistency of the generated images, from which a 3D scene can be reconstructed. Through extensive evaluation on the 3D-Front dataset, we demonstrate that HouseCraft can generate high-quality house-scale 3D scenes. Ablation studies also validate the effectiveness of different design choices. We will release our code and model weights. Project page: https://neu-vi.github.io/houseCrafter/
Toward Reinforcement Learning-based Rectilinear Macro Placement Under Human Constraints
Nov 03, 2023Macro placement is a critical phase in chip design, which becomes more intricate when involving general rectilinear macros and layout areas. Furthermore, macro placement that incorporates human-like constraints, such as design hierarchy and peripheral bias, has the potential to significantly reduce the amount of additional manual labor required from designers. This study proposes a methodology that leverages an approach suggested by Google's Circuit Training (G-CT) to provide a learning-based macro placer that not only supports placing rectilinear cases, but also adheres to crucial human-like design principles. Our experimental results demonstrate the effectiveness of our framework in achieving power-performance-area (PPA) metrics and in obtaining placements of high quality, comparable to those produced with human intervention. Additionally, our methodology shows potential as a generalized model to address diverse macro shapes and layout areas.
Vision and Language Navigation in the Real World via Online Visual Language Mapping
Oct 16, 2023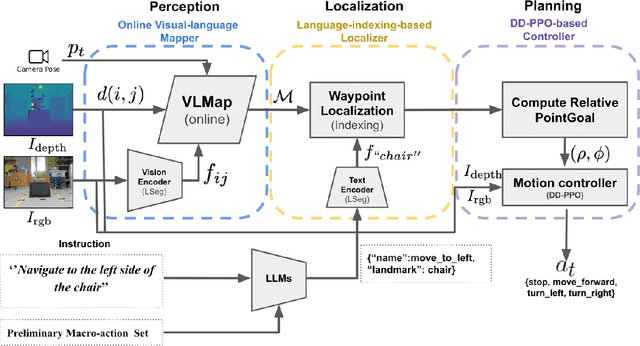


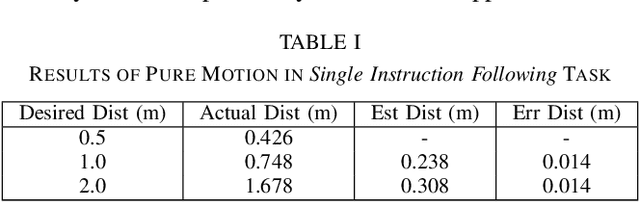
Navigating in unseen environments is crucial for mobile robots. Enhancing them with the ability to follow instructions in natural language will further improve navigation efficiency in unseen cases. However, state-of-the-art (SOTA) vision-and-language navigation (VLN) methods are mainly evaluated in simulation, neglecting the complex and noisy real world. Directly transferring SOTA navigation policies trained in simulation to the real world is challenging due to the visual domain gap and the absence of prior knowledge about unseen environments. In this work, we propose a novel navigation framework to address the VLN task in the real world. Utilizing the powerful foundation models, the proposed framework includes four key components: (1) an LLMs-based instruction parser that converts the language instruction into a sequence of pre-defined macro-action descriptions, (2) an online visual-language mapper that builds a real-time visual-language map to maintain a spatial and semantic understanding of the unseen environment, (3) a language indexing-based localizer that grounds each macro-action description into a waypoint location on the map, and (4) a DD-PPO-based local controller that predicts the action. We evaluate the proposed pipeline on an Interbotix LoCoBot WX250 in an unseen lab environment. Without any fine-tuning, our pipeline significantly outperforms the SOTA VLN baseline in the real world.
Evaluating the impact of an explainable machine learning system on the interobserver agreement in chest radiograph interpretation
Apr 01, 2023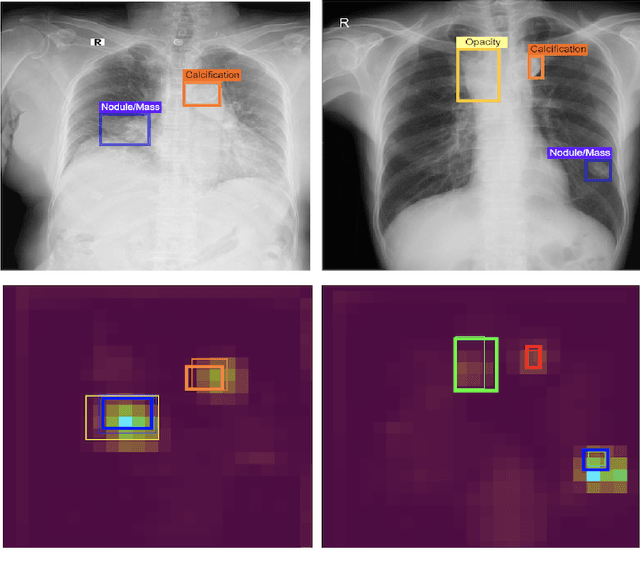
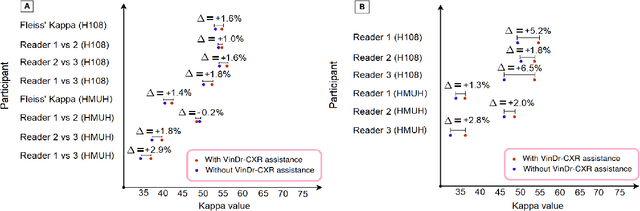
We conducted a prospective study to measure the clinical impact of an explainable machine learning system on interobserver agreement in chest radiograph interpretation. The AI system, which we call as it VinDr-CXR when used as a diagnosis-supporting tool, significantly improved the agreement between six radiologists with an increase of 1.5% in mean Fleiss' Kappa. In addition, we also observed that, after the radiologists consulted AI's suggestions, the agreement between each radiologist and the system was remarkably increased by 3.3% in mean Cohen's Kappa. This work has been accepted for publication in IEEE Access and this paper is our short version submitted to the Midwest Machine Learning Symposium (MMLS 2023), Chicago, IL, USA.
A Quantum Neural Network Regression for Modeling Lithium-ion Battery Capacity Degradation
Feb 06, 2023



Given the high power density low discharge rate and decreasing cost rechargeable lithium-ion batteries LiBs have found a wide range of applications such as power grid level storage systems electric vehicles and mobile devices. Developing a framework to accurately model the nonlinear degradation process of LiBs which is indeed a supervised learning problem becomes an important research topic. This paper presents a classical-quantum hybrid machine learning approach to capture the LiB degradation model that assesses battery cell life loss from operating profiles. Our work is motivated by recent advances in quantum computers as well as the similarity between neural networks and quantum circuits. Similar to adjusting weight parameters in conventional neural networks the parameters of the quantum circuit namely the qubits degree of freedom can be tuned to learn a nonlinear function in a supervised learning fashion. As a proof of concept paper our obtained numerical results with the battery dataset provided by NASA demonstrate the ability of the quantum neural networks in modeling the nonlinear relationship between the degraded capacity and the operating cycles. We also discuss the potential advantage of the quantum approach compared to conventional neural networks in classical computers in dealing with massive data especially in the context of future penetration of EVs and energy storage.
An Accurate and Explainable Deep Learning System Improves Interobserver Agreement in the Interpretation of Chest Radiograph
Aug 06, 2022Recent artificial intelligence (AI) algorithms have achieved radiologist-level performance on various medical classification tasks. However, only a few studies addressed the localization of abnormal findings from CXR scans, which is essential in explaining the image-level classification to radiologists. We introduce in this paper an explainable deep learning system called VinDr-CXR that can classify a CXR scan into multiple thoracic diseases and, at the same time, localize most types of critical findings on the image. VinDr-CXR was trained on 51,485 CXR scans with radiologist-provided bounding box annotations. It demonstrated a comparable performance to experienced radiologists in classifying 6 common thoracic diseases on a retrospective validation set of 3,000 CXR scans, with a mean area under the receiver operating characteristic curve (AUROC) of 0.967 (95% confidence interval [CI]: 0.958-0.975). The VinDr-CXR was also externally validated in independent patient cohorts and showed its robustness. For the localization task with 14 types of lesions, our free-response receiver operating characteristic (FROC) analysis showed that the VinDr-CXR achieved a sensitivity of 80.2% at the rate of 1.0 false-positive lesion identified per scan. A prospective study was also conducted to measure the clinical impact of the VinDr-CXR in assisting six experienced radiologists. The results indicated that the proposed system, when used as a diagnosis supporting tool, significantly improved the agreement between radiologists themselves with an increase of 1.5% in mean Fleiss' Kappa. We also observed that, after the radiologists consulted VinDr-CXR's suggestions, the agreement between each of them and the system was remarkably increased by 3.3% in mean Cohen's Kappa.
Slice-level Detection of Intracranial Hemorrhage on CT Using Deep Descriptors of Adjacent Slices
Aug 05, 2022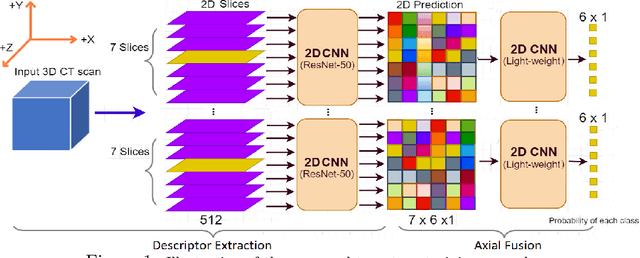
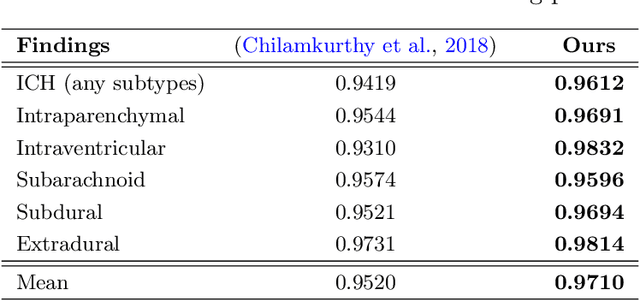
The rapid development in representation learning techniques and the availability of large-scale medical imaging data have to a rapid increase in the use of machine learning in the 3D medical image analysis. In particular, deep convolutional neural networks (D-CNNs) have been key players and were adopted by the medical imaging community to assist clinicians and medical experts in disease diagnosis. However, training deep neural networks such as D-CNN on high-resolution 3D volumes of Computed Tomography (CT) scans for diagnostic tasks poses formidable computational challenges. This raises the need of developing deep learning-based approaches that are robust in learning representations in 2D images, instead 3D scans. In this paper, we propose a new strategy to train \emph{slice-level} classifiers on CT scans based on the descriptors of the adjacent slices along the axis. In particular, each of which is extracted through a convolutional neural network (CNN). This method is applicable to CT datasets with per-slice labels such as the RSNA Intracranial Hemorrhage (ICH) dataset, which aims to predict the presence of ICH and classify it into 5 different sub-types. We obtain a single model in the top 4\% best-performing solutions of the RSNA ICH challenge, where model ensembles are allowed. Experiments also show that the proposed method significantly outperforms the baseline model on CQ500. The proposed method is general and can be applied for other 3D medical diagnosis tasks such as MRI imaging. To encourage new advances in the field, we will make our codes and pre-trained model available upon acceptance of the paper.
VinDr-Mammo: A large-scale benchmark dataset for computer-aided diagnosis in full-field digital mammography
Mar 20, 2022Mammography, or breast X-ray, is the most widely used imaging modality to detect cancer and other breast diseases. Recent studies have shown that deep learning-based computer-assisted detection and diagnosis (CADe or CADx) tools have been developed to support physicians and improve the accuracy of interpreting mammography. However, most published datasets of mammography are either limited on sample size or digitalized from screen-film mammography (SFM), hindering the development of CADe and CADx tools which are developed based on full-field digital mammography (FFDM). To overcome this challenge, we introduce VinDr-Mammo - a new benchmark dataset of FFDM for detecting and diagnosing breast cancer and other diseases in mammography. The dataset consists of 5,000 mammography exams, each of which has four standard views and is double read with disagreement (if any) being resolved by arbitration. It is created for the assessment of Breast Imaging Reporting and Data System (BI-RADS) and density at the breast level. In addition, the dataset also provides the category, location, and BI-RADS assessment of non-benign findings. We make VinDr-Mammo publicly available on PhysioNet as a new imaging resource to promote advances in developing CADe and CADx tools for breast cancer screening.
Learning from Multiple Expert Annotators for Enhancing Anomaly Detection in Medical Image Analysis
Mar 20, 2022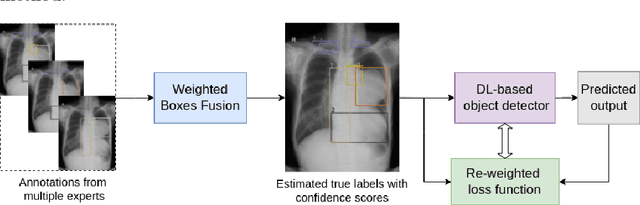
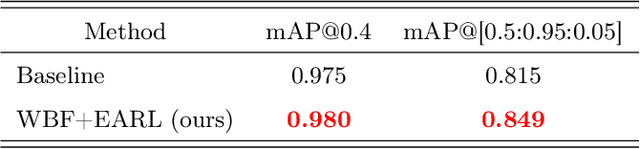
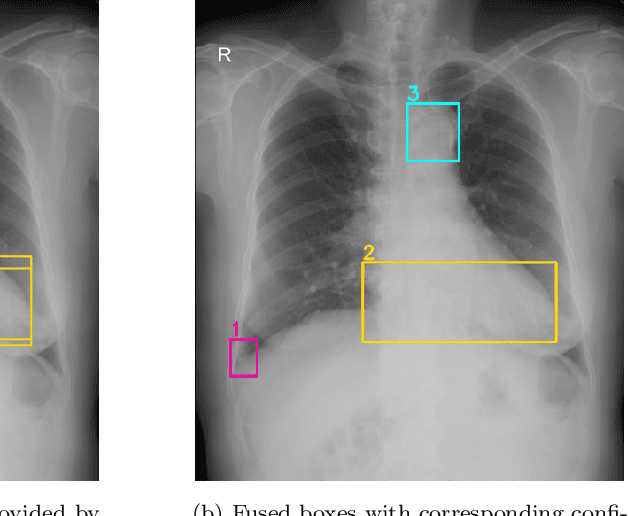
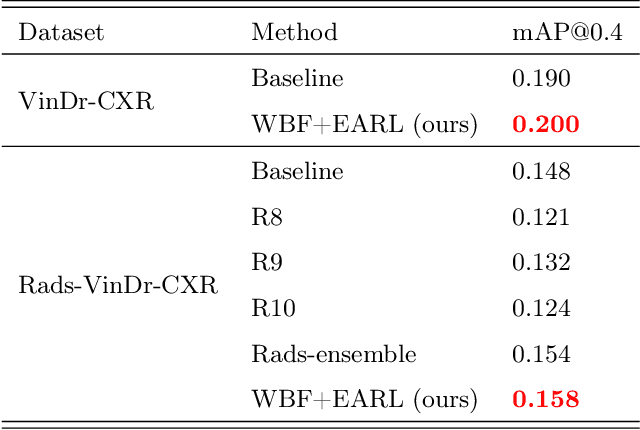
Building an accurate computer-aided diagnosis system based on data-driven approaches requires a large amount of high-quality labeled data. In medical imaging analysis, multiple expert annotators often produce subjective estimates about "ground truth labels" during the annotation process, depending on their expertise and experience. As a result, the labeled data may contain a variety of human biases with a high rate of disagreement among annotators, which significantly affect the performance of supervised machine learning algorithms. To tackle this challenge, we propose a simple yet effective approach to combine annotations from multiple radiology experts for training a deep learning-based detector that aims to detect abnormalities on medical scans. The proposed method first estimates the ground truth annotations and confidence scores of training examples. The estimated annotations and their scores are then used to train a deep learning detector with a re-weighted loss function to localize abnormal findings. We conduct an extensive experimental evaluation of the proposed approach on both simulated and real-world medical imaging datasets. The experimental results show that our approach significantly outperforms baseline approaches that do not consider the disagreements among annotators, including methods in which all of the noisy annotations are treated equally as ground truth and the ensemble of different models trained on different label sets provided separately by annotators.
Learning to Automatically Diagnose Multiple Diseases in Pediatric Chest Radiographs Using Deep Convolutional Neural Networks
Aug 14, 2021Chest radiograph (CXR) interpretation in pediatric patients is error-prone and requires a high level of understanding of radiologic expertise. Recently, deep convolutional neural networks (D-CNNs) have shown remarkable performance in interpreting CXR in adults. However, there is a lack of evidence indicating that D-CNNs can recognize accurately multiple lung pathologies from pediatric CXR scans. In particular, the development of diagnostic models for the detection of pediatric chest diseases faces significant challenges such as (i) lack of physician-annotated datasets and (ii) class imbalance problems. In this paper, we retrospectively collect a large dataset of 5,017 pediatric CXR scans, for which each is manually labeled by an experienced radiologist for the presence of 10 common pathologies. A D-CNN model is then trained on 3,550 annotated scans to classify multiple pediatric lung pathologies automatically. To address the high-class imbalance issue, we propose to modify and apply "Distribution-Balanced loss" for training D-CNNs which reshapes the standard Binary-Cross Entropy loss (BCE) to efficiently learn harder samples by down-weighting the loss assigned to the majority classes. On an independent test set of 777 studies, the proposed approach yields an area under the receiver operating characteristic (AUC) of 0.709 (95% CI, 0.690-0.729). The sensitivity, specificity, and F1-score at the cutoff value are 0.722 (0.694-0.750), 0.579 (0.563-0.595), and 0.389 (0.373-0.405), respectively. These results significantly outperform previous state-of-the-art methods on most of the target diseases. Moreover, our ablation studies validate the effectiveness of the proposed loss function compared to other standard losses, e.g., BCE and Focal Loss, for this learning task. Overall, we demonstrate the potential of D-CNNs in interpreting pediatric CXRs.