 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVinDr-Mammo: A large-scale benchmark dataset for computer-aided diagnosis in full-field digital mammography
Mar 20, 2022Mammography, or breast X-ray, is the most widely used imaging modality to detect cancer and other breast diseases. Recent studies have shown that deep learning-based computer-assisted detection and diagnosis (CADe or CADx) tools have been developed to support physicians and improve the accuracy of interpreting mammography. However, most published datasets of mammography are either limited on sample size or digitalized from screen-film mammography (SFM), hindering the development of CADe and CADx tools which are developed based on full-field digital mammography (FFDM). To overcome this challenge, we introduce VinDr-Mammo - a new benchmark dataset of FFDM for detecting and diagnosing breast cancer and other diseases in mammography. The dataset consists of 5,000 mammography exams, each of which has four standard views and is double read with disagreement (if any) being resolved by arbitration. It is created for the assessment of Breast Imaging Reporting and Data System (BI-RADS) and density at the breast level. In addition, the dataset also provides the category, location, and BI-RADS assessment of non-benign findings. We make VinDr-Mammo publicly available on PhysioNet as a new imaging resource to promote advances in developing CADe and CADx tools for breast cancer screening.
VinDr-SpineXR: A deep learning framework for spinal lesions detection and classification from radiographs
Jun 24, 2021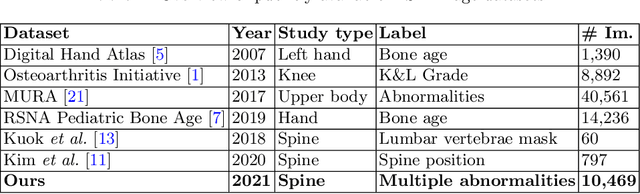
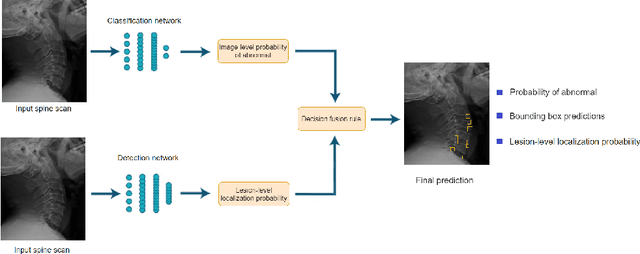
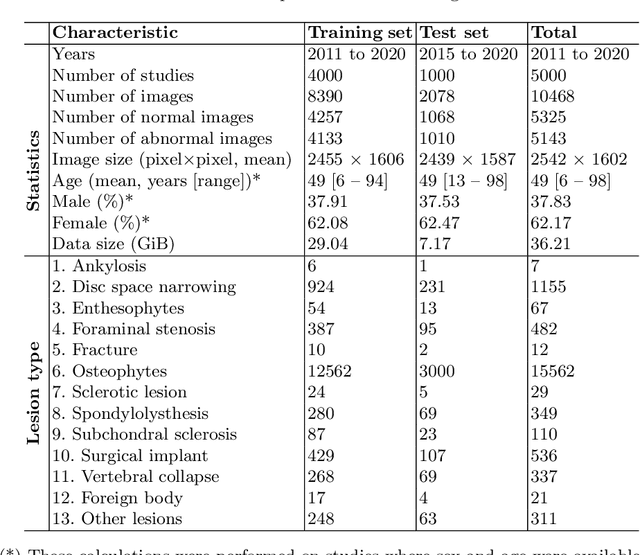

Radiographs are used as the most important imaging tool for identifying spine anomalies in clinical practice. The evaluation of spinal bone lesions, however, is a challenging task for radiologists. This work aims at developing and evaluating a deep learning-based framework, named VinDr-SpineXR, for the classification and localization of abnormalities from spine X-rays. First, we build a large dataset, comprising 10,468 spine X-ray images from 5,000 studies, each of which is manually annotated by an experienced radiologist with bounding boxes around abnormal findings in 13 categories. Using this dataset, we then train a deep learning classifier to determine whether a spine scan is abnormal and a detector to localize 7 crucial findings amongst the total 13. The VinDr-SpineXR is evaluated on a test set of 2,078 images from 1,000 studies, which is kept separate from the training set. It demonstrates an area under the receiver operating characteristic curve (AUROC) of 88.61% (95% CI 87.19%, 90.02%) for the image-level classification task and a mean average precision (mAP@0.5) of 33.56% for the lesion-level localization task. These results serve as a proof of concept and set a baseline for future research in this direction. To encourage advances, the dataset, codes, and trained deep learning models are made publicly available.
VinDr-CXR: An open dataset of chest X-rays with radiologist's annotations
Jan 03, 2021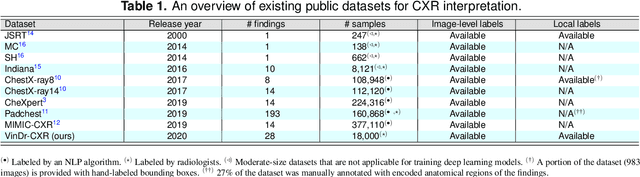
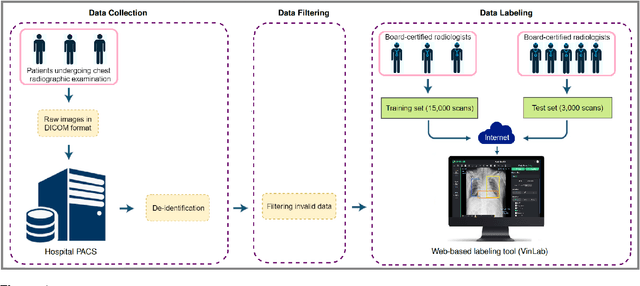
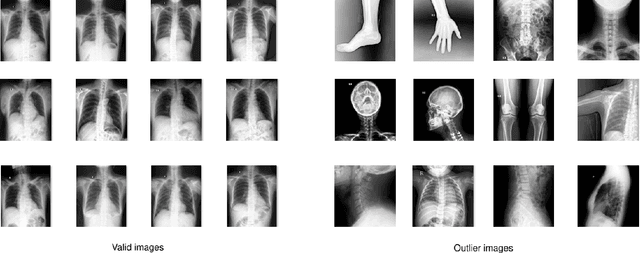
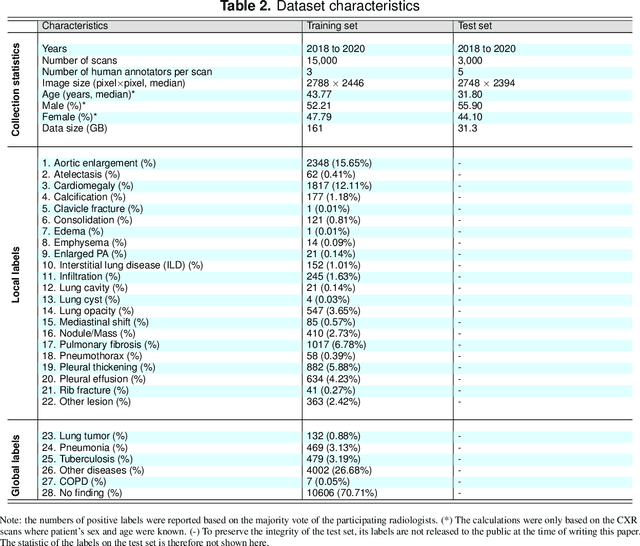
Most of the existing chest X-ray datasets include labels from a list of findings without specifying their locations on the radiographs. This limits the development of machine learning algorithms for the detection and localization of chest abnormalities. In this work, we describe a dataset of more than 100,000 chest X-ray scans that were retrospectively collected from two major hospitals in Vietnam. Out of this raw data, we release 18,000 images that were manually annotated by a total of 17 experienced radiologists with 22 local labels of rectangles surrounding abnormalities and 6 global labels of suspected diseases. The released dataset is divided into a training set of 15,000 and a test set of 3,000. Each scan in the training set was independently labeled by 3 radiologists, while each scan in the test set was labeled by the consensus of 5 radiologists. We designed and built a labeling platform for DICOM images to facilitate these annotation procedures. All images are made publicly available in DICOM format in company with the labels of the training set. The labels of the test set are hidden at the time of writing this paper as they will be used for benchmarking machine learning algorithms on an open platform.
Collaborative Multi-sensor Classification via Sparsity-based Representation
Jun 16, 2016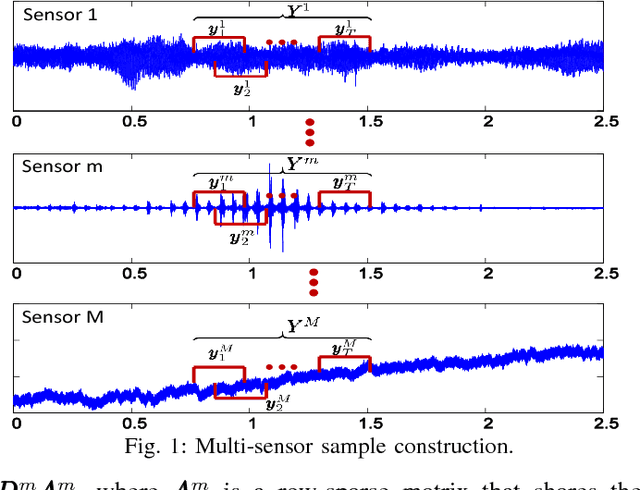
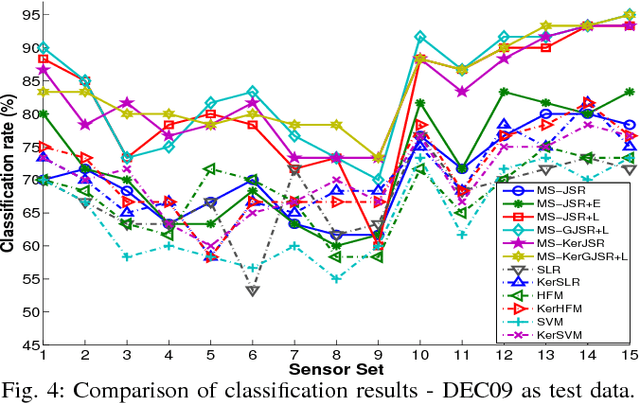
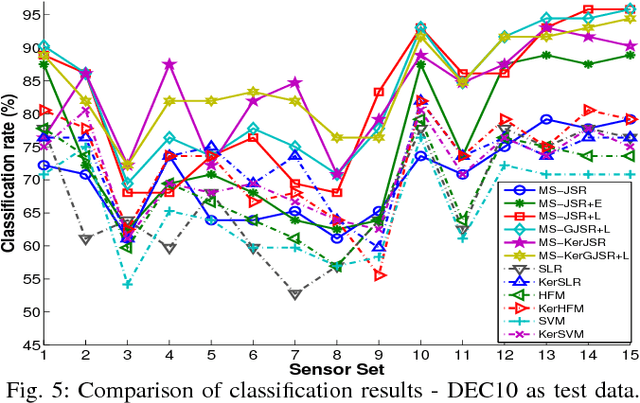

In this paper, we propose a general collaborative sparse representation framework for multi-sensor classification, which takes into account the correlations as well as complementary information between heterogeneous sensors simultaneously while considering joint sparsity within each sensor's observations. We also robustify our models to deal with the presence of sparse noise and low-rank interference signals. Specifically, we demonstrate that incorporating the noise or interference signal as a low-rank component in our models is essential in a multi-sensor classification problem when multiple co-located sources/sensors simultaneously record the same physical event. We further extend our frameworks to kernelized models which rely on sparsely representing a test sample in terms of all the training samples in a feature space induced by a kernel function. A fast and efficient algorithm based on alternative direction method is proposed where its convergence to an optimal solution is guaranteed. Extensive experiments are conducted on several real multi-sensor data sets and results are compared with the conventional classifiers to verify the effectiveness of the proposed methods.
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference
May 17, 2016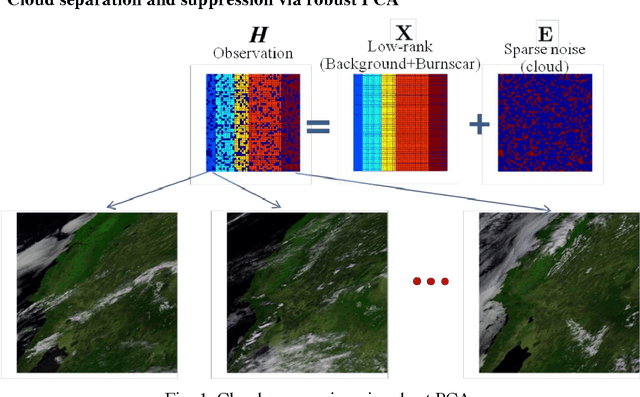
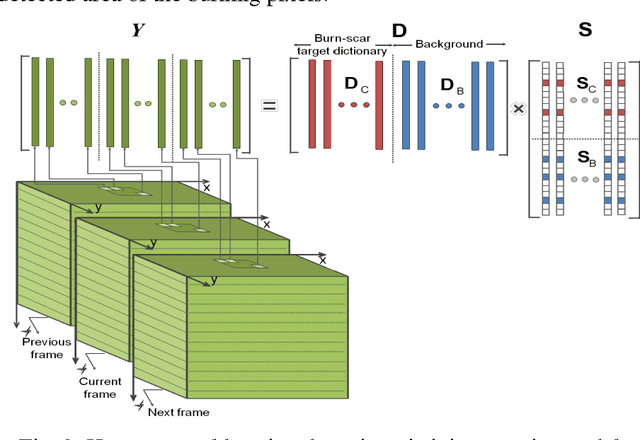
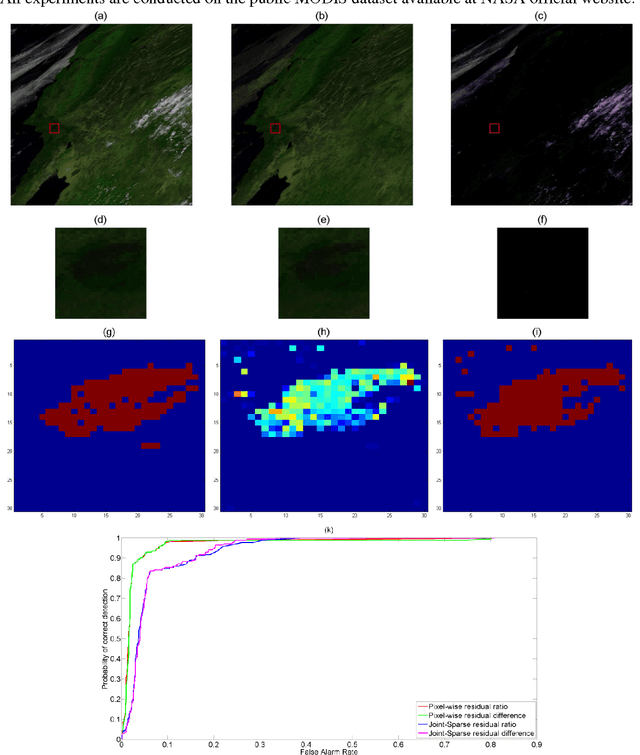
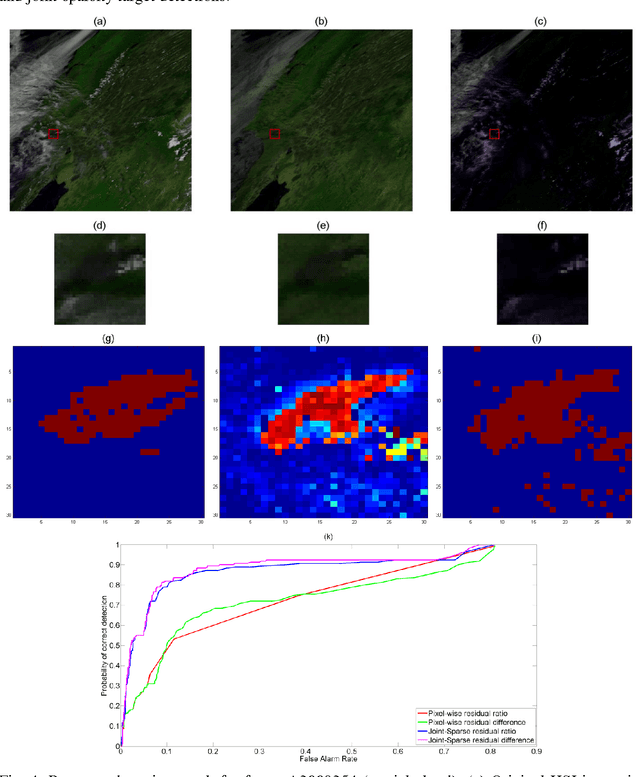
In this paper, we propose a burnscar detection model for hyperspectral imaging (HSI) data. The proposed model contains two-processing steps in which the first step separate and then suppress the cloud information presenting in the data set using an RPCA algorithm and the second step detect the burnscar area in the low-rank component output of the first step. Experiments are conducted on the public MODIS dataset available at NASA official website.
Hierarchical Sparse and Collaborative Low-Rank Representation for Emotion Recognition
Apr 01, 2015
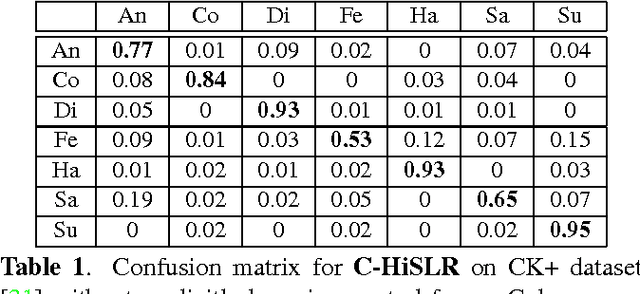

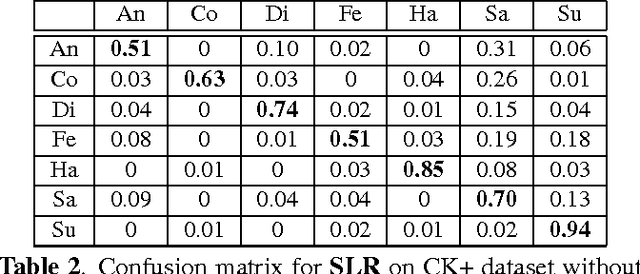
In this paper, we design a Collaborative-Hierarchical Sparse and Low-Rank (C-HiSLR) model that is natural for recognizing human emotion in visual data. Previous attempts require explicit expression components, which are often unavailable and difficult to recover. Instead, our model exploits the lowrank property over expressive facial frames and rescue inexact sparse representations by incorporating group sparsity. For the CK+ dataset, C-HiSLR on raw expressive faces performs as competitive as the Sparse Representation based Classification (SRC) applied on manually prepared emotions. C-HiSLR performs even better than SRC in terms of true positive rate.
Multi-task Image Classification via Collaborative, Hierarchical Spike-and-Slab Priors
Jan 30, 2015

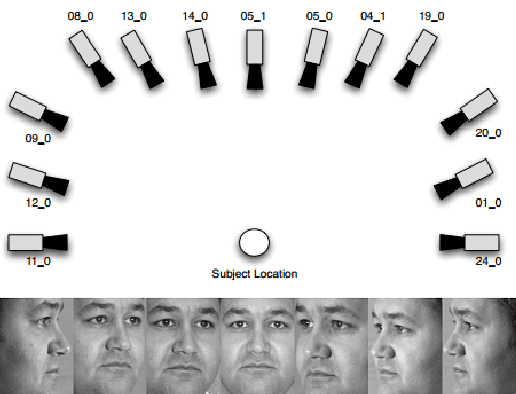
Promising results have been achieved in image classification problems by exploiting the discriminative power of sparse representations for classification (SRC). Recently, it has been shown that the use of \emph{class-specific} spike-and-slab priors in conjunction with the class-specific dictionaries from SRC is particularly effective in low training scenarios. As a logical extension, we build on this framework for multitask scenarios, wherein multiple representations of the same physical phenomena are available. We experimentally demonstrate the benefits of mining joint information from different camera views for multi-view face recognition.
Structured Dictionary Learning for Classification
Jun 08, 2014

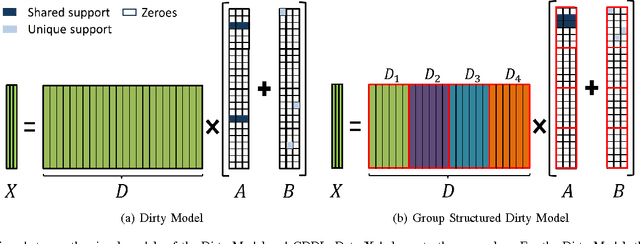
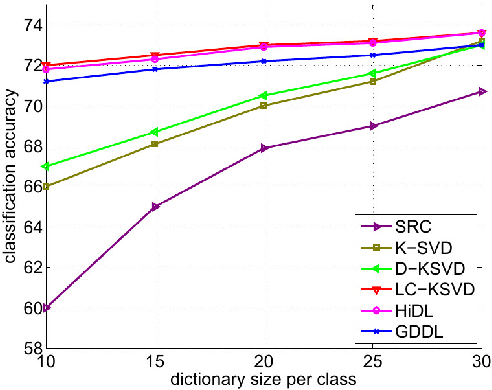
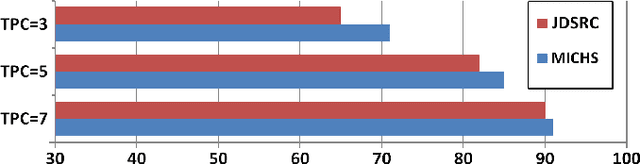
Sparsity driven signal processing has gained tremendous popularity in the last decade. At its core, the assumption is that the signal of interest is sparse with respect to either a fixed transformation or a signal dependent dictionary. To better capture the data characteristics, various dictionary learning methods have been proposed for both reconstruction and classification tasks. For classification particularly, most approaches proposed so far have focused on designing explicit constraints on the sparse code to improve classification accuracy while simply adopting $l_0$-norm or $l_1$-norm for sparsity regularization. Motivated by the success of structured sparsity in the area of Compressed Sensing, we propose a structured dictionary learning framework (StructDL) that incorporates the structure information on both group and task levels in the learning process. Its benefits are two-fold: (i) the label consistency between dictionary atoms and training data are implicitly enforced; and (ii) the classification performance is more robust in the cases of a small dictionary size or limited training data than other techniques. Using the subspace model, we derive the conditions for StructDL to guarantee the performance and show theoretically that StructDL is superior to $l_0$-norm or $l_1$-norm regularized dictionary learning for classification. Extensive experiments have been performed on both synthetic simulations and real world applications, such as face recognition and object classification, to demonstrate the validity of the proposed DL framework.