 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA high performance approach to detecting small targets in long range low quality infrared videos
Dec 04, 2020
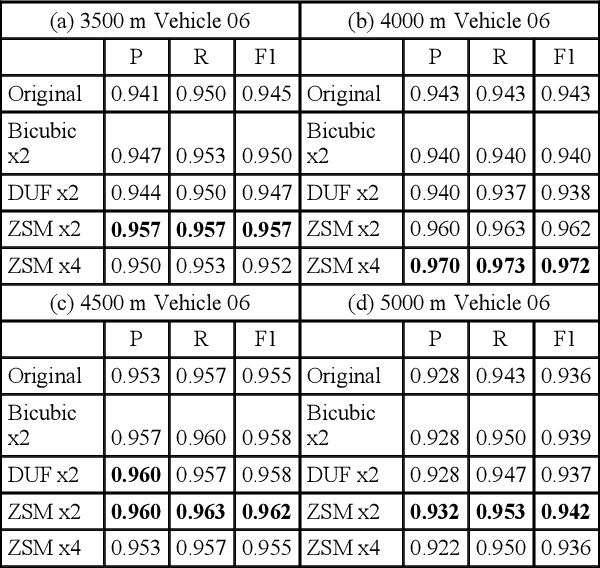

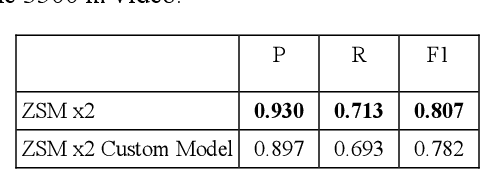
Since targets are small in long range infrared (IR) videos, it is challenging to accurately detect targets in those videos. In this paper, we propose a high performance approach to detecting small targets in long range and low quality infrared videos. Our approach consists of a video resolution enhancement module, a proven small target detector based on local intensity and gradient (LIG), a connected component (CC) analysis module, and a track association module to connect detections from multiple frames. Extensive experiments using actual mid-wave infrared (MWIR) videos in ranges between 3500 m and 5000 m from a benchmark dataset clearly demonstrated the efficacy of the proposed approach.
Unsupervised Pansharpening Based on Self-Attention Mechanism
Jun 16, 2020

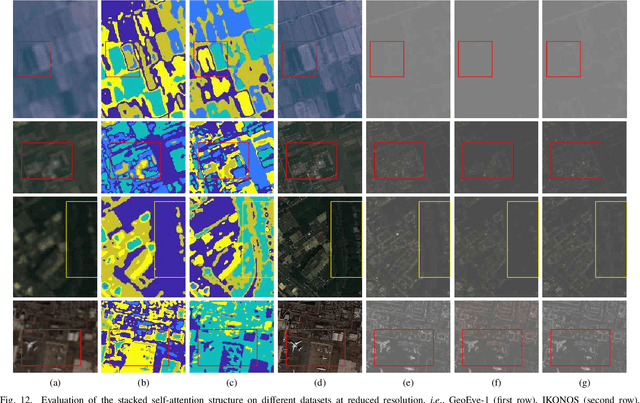

Pansharpening is to fuse a multispectral image (MSI) of low-spatial-resolution (LR) but rich spectral characteristics with a panchromatic image (PAN) of high-spatial-resolution (HR) but poor spectral characteristics. Traditional methods usually inject the extracted high-frequency details from PAN into the up-sampled MSI. Recent deep learning endeavors are mostly supervised assuming the HR MSI is available, which is unrealistic especially for satellite images. Nonetheless, these methods could not fully exploit the rich spectral characteristics in the MSI. Due to the wide existence of mixed pixels in satellite images where each pixel tends to cover more than one constituent material, pansharpening at the subpixel level becomes essential. In this paper, we propose an unsupervised pansharpening (UP) method in a deep-learning framework to address the above challenges based on the self-attention mechanism (SAM), referred to as UP-SAM. The contribution of this paper is three-fold. First, the self-attention mechanism is proposed where the spatial varying detail extraction and injection functions are estimated according to the attention representations indicating spectral characteristics of the MSI with sub-pixel accuracy. Second, such attention representations are derived from mixed pixels with the proposed stacked attention network powered with a stick-breaking structure to meet the physical constraints of mixed pixel formulations. Third, the detail extraction and injection functions are spatial varying based on the attention representations, which largely improves the reconstruction accuracy. Extensive experimental results demonstrate that the proposed approach is able to reconstruct sharper MSI of different types, with more details and less spectral distortion as compared to the state-of-the-art.
Unsupervised and Unregistered Hyperspectral Image Super-Resolution with Mutual Dirichlet-Net
May 10, 2019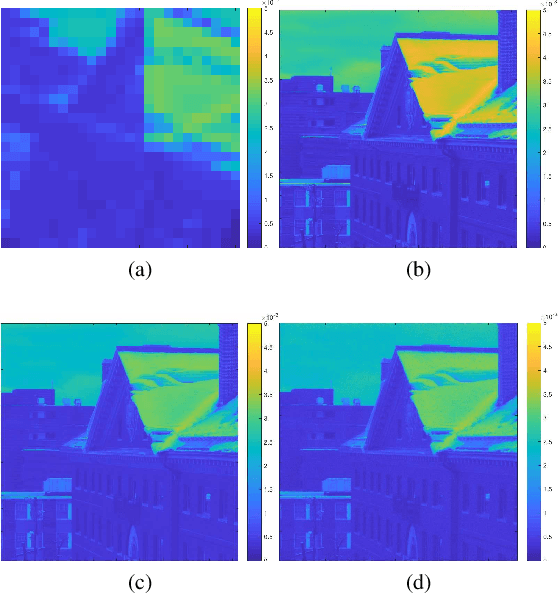


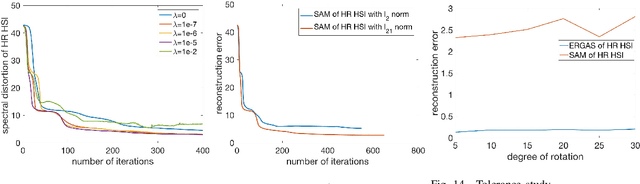
Hyperspectral images (HSI) provide rich spectral information that contributed to the successful performance improvement of numerous computer vision tasks. However, it can only be achieved at the expense of images' spatial resolution. Hyperspectral image super-resolution (HSI-SR) addresses this problem by fusing low resolution (LR) HSI with multispectral image (MSI) carrying much higher spatial resolution (HR). All existing HSI-SR approaches require the LR HSI and HR MSI to be well registered and the reconstruction accuracy of the HR HSI relies heavily on the registration accuracy of different modalities. This paper exploits the uncharted problem domain of HSI-SR without the requirement of multi-modality registration. Given the unregistered LR HSI and HR MSI with overlapped regions, we design a unique unsupervised learning structure linking the two unregistered modalities by projecting them into the same statistical space through the same encoder. The mutual information (MI) is further adopted to capture the non-linear statistical dependencies between the representations from two modalities (carrying spatial information) and their raw inputs. By maximizing the MI, spatial correlations between different modalities can be well characterized to further reduce the spectral distortion. A collaborative $l_{2,1}$ norm is employed as the reconstruction error instead of the more common $l_2$ norm, so that individual pixels can be recovered as accurately as possible. With this design, the network allows to extract correlated spectral and spatial information from unregistered images that better preserves the spectral information. The proposed method is referred to as unregistered and unsupervised mutual Dirichlet Net ($u^2$-MDN). Extensive experimental results using benchmark HSI datasets demonstrate the superior performance of $u^2$-MDN as compared to the state-of-the-art.
Unsupervised Sparse Dirichlet-Net for Hyperspectral Image Super-Resolution
Jul 15, 2018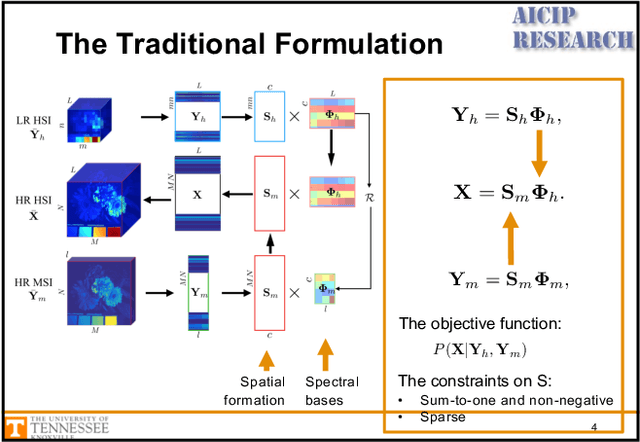
In many computer vision applications, obtaining images of high resolution in both the spatial and spectral domains are equally important. However, due to hardware limitations, one can only expect to acquire images of high resolution in either the spatial or spectral domains. This paper focuses on hyperspectral image super-resolution (HSI-SR), where a hyperspectral image (HSI) with low spatial resolution (LR) but high spectral resolution is fused with a multispectral image (MSI) with high spatial resolution (HR) but low spectral resolution to obtain HR HSI. Existing deep learning-based solutions are all supervised that would need a large training set and the availability of HR HSI, which is unrealistic. Here, we make the first attempt to solving the HSI-SR problem using an unsupervised encoder-decoder architecture that carries the following uniquenesses. First, it is composed of two encoder-decoder networks, coupled through a shared decoder, in order to preserve the rich spectral information from the HSI network. Second, the network encourages the representations from both modalities to follow a sparse Dirichlet distribution which naturally incorporates the two physical constraints of HSI and MSI. Third, the angular difference between representations are minimized in order to reduce the spectral distortion. We refer to the proposed architecture as unsupervised Sparse Dirichlet-Net, or uSDN. Extensive experimental results demonstrate the superior performance of uSDN as compared to the state-of-the-art.
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference
May 17, 2016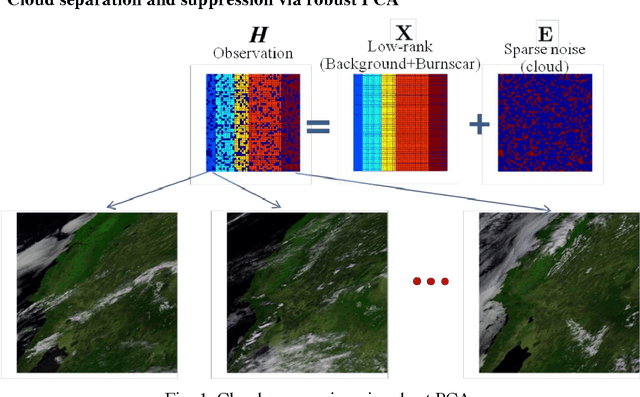
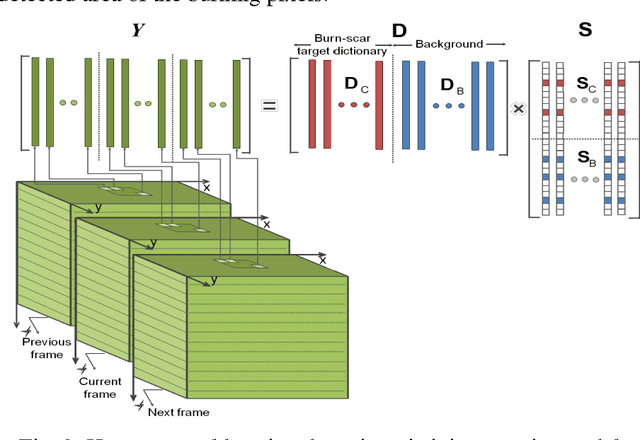
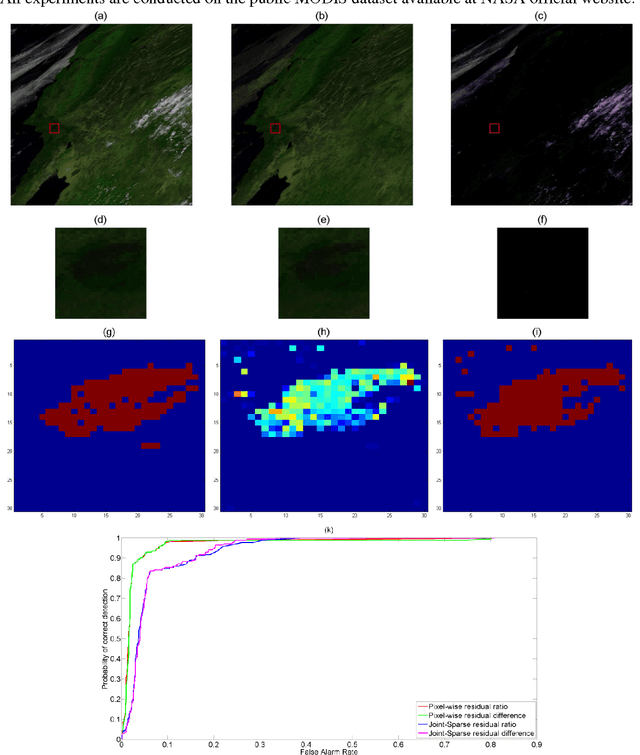
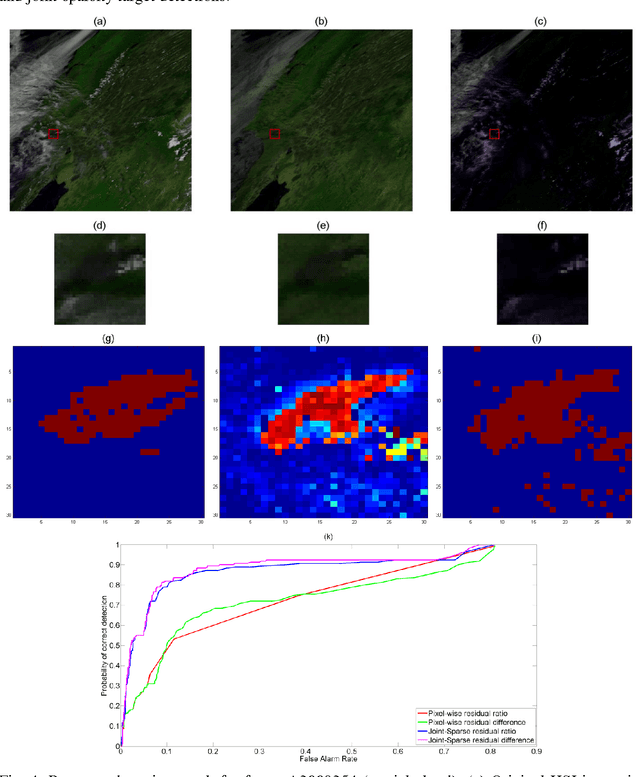
In this paper, we propose a burnscar detection model for hyperspectral imaging (HSI) data. The proposed model contains two-processing steps in which the first step separate and then suppress the cloud information presenting in the data set using an RPCA algorithm and the second step detect the burnscar area in the low-rank component output of the first step. Experiments are conducted on the public MODIS dataset available at NASA official website.