 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKIPPO: Koopman-Inspired Proximal Policy Optimization
May 20, 2025Reinforcement Learning (RL) has made significant strides in various domains, and policy gradient methods like Proximal Policy Optimization (PPO) have gained popularity due to their balance in performance, training stability, and computational efficiency. These methods directly optimize policies through gradient-based updates. However, developing effective control policies for environments with complex and non-linear dynamics remains a challenge. High variance in gradient estimates and non-convex optimization landscapes often lead to unstable learning trajectories. Koopman Operator Theory has emerged as a powerful framework for studying non-linear systems through an infinite-dimensional linear operator that acts on a higher-dimensional space of measurement functions. In contrast with their non-linear counterparts, linear systems are simpler, more predictable, and easier to analyze. In this paper, we present Koopman-Inspired Proximal Policy Optimization (KIPPO), which learns an approximately linear latent-space representation of the underlying system's dynamics while retaining essential features for effective policy learning. This is achieved through a Koopman-approximation auxiliary network that can be added to the baseline policy optimization algorithms without altering the architecture of the core policy or value function. Extensive experimental results demonstrate consistent improvements over the PPO baseline with 6-60% increased performance while reducing variability by up to 91% when evaluated on various continuous control tasks.
Integrating Reinforcement Learning and AI Agents for Adaptive Robotic Interaction and Assistance in Dementia Care
Jan 28, 2025This study explores a novel approach to advancing dementia care by integrating socially assistive robotics, reinforcement learning (RL), large language models (LLMs), and clinical domain expertise within a simulated environment. This integration addresses the critical challenge of limited experimental data in socially assistive robotics for dementia care, providing a dynamic simulation environment that realistically models interactions between persons living with dementia (PLWDs) and robotic caregivers. The proposed framework introduces a probabilistic model to represent the cognitive and emotional states of PLWDs, combined with an LLM-based behavior simulation to emulate their responses. We further develop and train an adaptive RL system enabling humanoid robots, such as Pepper, to deliver context-aware and personalized interactions and assistance based on PLWDs' cognitive and emotional states. The framework also generalizes to computer-based agents, highlighting its versatility. Results demonstrate that the RL system, enhanced by LLMs, effectively interprets and responds to the complex needs of PLWDs, providing tailored caregiving strategies. This research contributes to human-computer and human-robot interaction by offering a customizable AI-driven caregiving platform, advancing understanding of dementia-related challenges, and fostering collaborative innovation in assistive technologies. The proposed approach has the potential to enhance the independence and quality of life for PLWDs while alleviating caregiver burden, underscoring the transformative role of interaction-focused AI systems in dementia care.
Defect Detection in Tire X-Ray Images: Conventional Methods Meet Deep Structures
Feb 28, 2024This paper introduces a robust approach for automated defect detection in tire X-ray images by harnessing traditional feature extraction methods such as Local Binary Pattern (LBP) and Gray Level Co-Occurrence Matrix (GLCM) features, as well as Fourier and Wavelet-based features, complemented by advanced machine learning techniques. Recognizing the challenges inherent in the complex patterns and textures of tire X-ray images, the study emphasizes the significance of feature engineering to enhance the performance of defect detection systems. By meticulously integrating combinations of these features with a Random Forest (RF) classifier and comparing them against advanced models like YOLOv8, the research not only benchmarks the performance of traditional features in defect detection but also explores the synergy between classical and modern approaches. The experimental results demonstrate that these traditional features, when fine-tuned and combined with machine learning models, can significantly improve the accuracy and reliability of tire defect detection, aiming to set a new standard in automated quality assurance in tire manufacturing.
Cross-Scale MAE: A Tale of Multi-Scale Exploitation in Remote Sensing
Jan 29, 2024Remote sensing images present unique challenges to image analysis due to the extensive geographic coverage, hardware limitations, and misaligned multi-scale images. This paper revisits the classical multi-scale representation learning problem but under the general framework of self-supervised learning for remote sensing image understanding. We present Cross-Scale MAE, a self-supervised model built upon the Masked Auto-Encoder (MAE).During pre-training, Cross-Scale MAE employs scale augmentation techniques and enforces cross-scale consistency constraints through both contrastive and generative losses to ensure consistent and meaningful representations well-suited for a wide range of downstream tasks. Further, our implementation leverages the xFormers library to accelerate network pre-training on a single GPU while maintaining the quality of learned representations. Experimental evaluations demonstrate that Cross-Scale MAE exhibits superior performance compared to standard MAE and other state-of-the-art remote sensing MAE methods.
Neural Symbolic Regression using Control Variables
Jun 07, 2023Symbolic regression (SR) is a powerful technique for discovering the analytical mathematical expression from data, finding various applications in natural sciences due to its good interpretability of results. However, existing methods face scalability issues when dealing with complex equations involving multiple variables. To address this challenge, we propose SRCV, a novel neural symbolic regression method that leverages control variables to enhance both accuracy and scalability. The core idea is to decompose multi-variable symbolic regression into a set of single-variable SR problems, which are then combined in a bottom-up manner. The proposed method involves a four-step process. First, we learn a data generator from observed data using deep neural networks (DNNs). Second, the data generator is used to generate samples for a certain variable by controlling the input variables. Thirdly, single-variable symbolic regression is applied to estimate the corresponding mathematical expression. Lastly, we repeat steps 2 and 3 by gradually adding variables one by one until completion. We evaluate the performance of our method on multiple benchmark datasets. Experimental results demonstrate that the proposed SRCV significantly outperforms state-of-the-art baselines in discovering mathematical expressions with multiple variables. Moreover, it can substantially reduce the search space for symbolic regression. The source code will be made publicly available upon publication.
CFTrack: Center-based Radar and Camera Fusion for 3D Multi-Object Tracking
Jul 11, 2021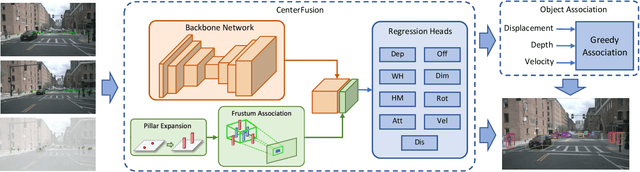
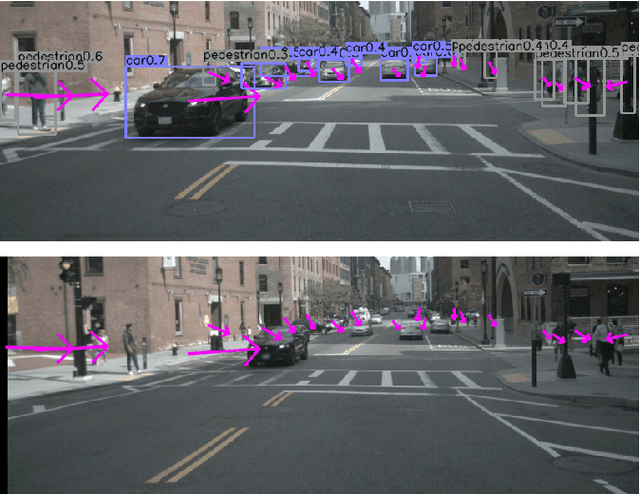
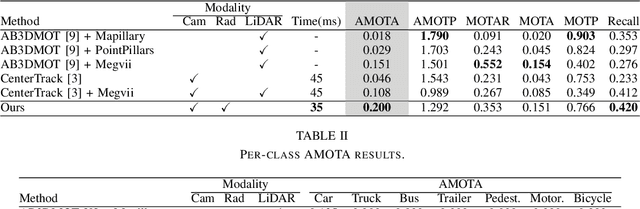
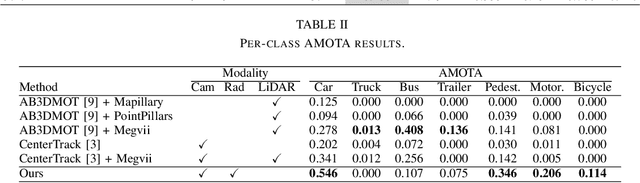
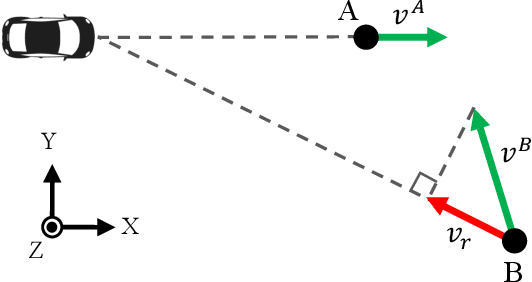
3D multi-object tracking is a crucial component in the perception system of autonomous driving vehicles. Tracking all dynamic objects around the vehicle is essential for tasks such as obstacle avoidance and path planning. Autonomous vehicles are usually equipped with different sensor modalities to improve accuracy and reliability. While sensor fusion has been widely used in object detection networks in recent years, most existing multi-object tracking algorithms either rely on a single input modality, or do not fully exploit the information provided by multiple sensing modalities. In this work, we propose an end-to-end network for joint object detection and tracking based on radar and camera sensor fusion. Our proposed method uses a center-based radar-camera fusion algorithm for object detection and utilizes a greedy algorithm for object association. The proposed greedy algorithm uses the depth, velocity and 2D displacement of the detected objects to associate them through time. This makes our tracking algorithm very robust to occluded and overlapping objects, as the depth and velocity information can help the network in distinguishing them. We evaluate our method on the challenging nuScenes dataset, where it achieves 20.0 AMOTA and outperforms all vision-based 3D tracking methods in the benchmark, as well as the baseline LiDAR-based method. Our method is online with a runtime of 35ms per image, making it very suitable for autonomous driving applications.
Towards Adversarial-Resilient Deep Neural Networks for False Data Injection Attack Detection in Power Grids
Feb 17, 2021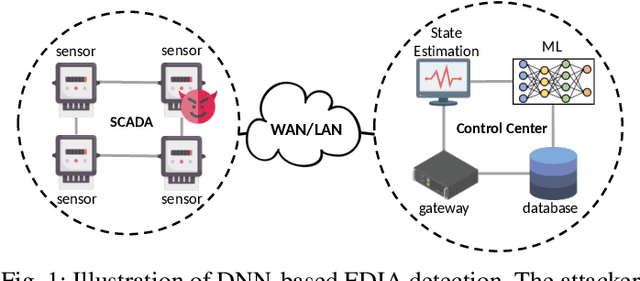
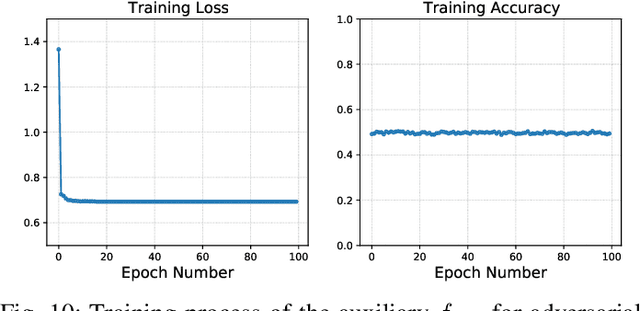
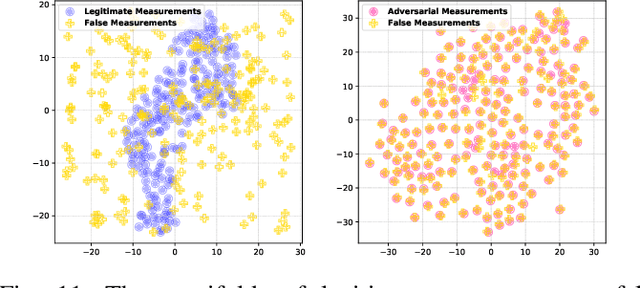
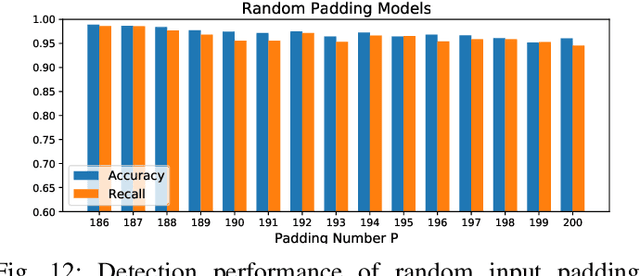
False data injection attack (FDIA) is a critical security issue in power system state estimation. In recent years, machine learning (ML) techniques, especially deep neural networks (DNNs), have been proposed in the literature for FDIA detection. However, they have not considered the risk of adversarial attacks, which were shown to be threatening to DNN's reliability in different ML applications. In this paper, we evaluate the vulnerability of DNNs used for FDIA detection through adversarial attacks and study the defensive approaches. We analyze several representative adversarial defense mechanisms and demonstrate that they have intrinsic limitations in FDIA detection. We then design an adversarial-resilient DNN detection framework for FDIA by introducing random input padding in both the training and inference phases. Extensive simulations based on an IEEE standard power system show that our framework greatly reduces the effectiveness of adversarial attacks while having little impact on the detection performance of the DNNs.
CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection
Nov 10, 2020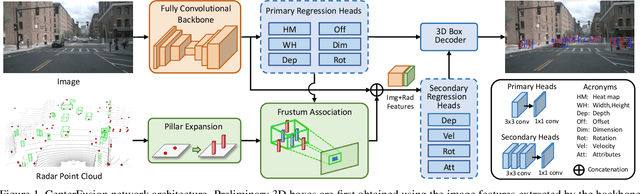
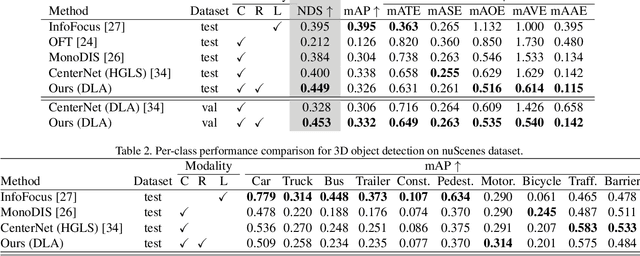

The perception system in autonomous vehicles is responsible for detecting and tracking the surrounding objects. This is usually done by taking advantage of several sensing modalities to increase robustness and accuracy, which makes sensor fusion a crucial part of the perception system. In this paper, we focus on the problem of radar and camera sensor fusion and propose a middle-fusion approach to exploit both radar and camera data for 3D object detection. Our approach, called CenterFusion, first uses a center point detection network to detect objects by identifying their center points on the image. It then solves the key data association problem using a novel frustum-based method to associate the radar detections to their corresponding object's center point. The associated radar detections are used to generate radar-based feature maps to complement the image features, and regress to object properties such as depth, rotation and velocity. We evaluate CenterFusion on the challenging nuScenes dataset, where it improves the overall nuScenes Detection Score (NDS) of the state-of-the-art camera-based algorithm by more than 12%. We further show that CenterFusion significantly improves the velocity estimation accuracy without using any additional temporal information. The code is available at https://github.com/mrnabati/CenterFusion .
Radar-Camera Sensor Fusion for Joint Object Detection and Distance Estimation in Autonomous Vehicles
Sep 17, 2020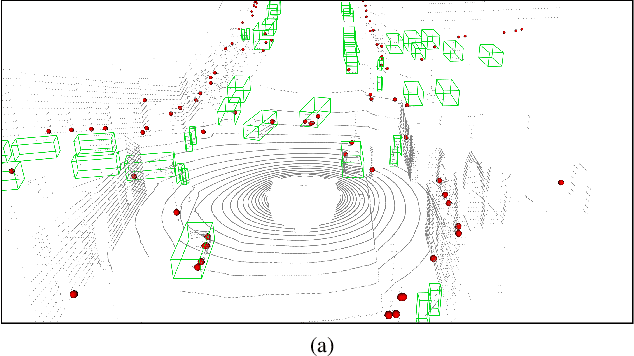
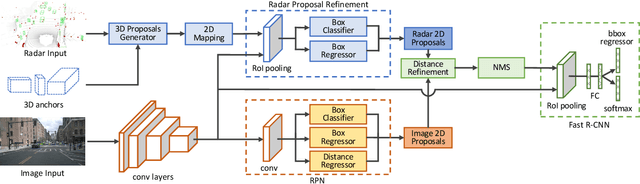


In this paper we present a novel radar-camera sensor fusion framework for accurate object detection and distance estimation in autonomous driving scenarios. The proposed architecture uses a middle-fusion approach to fuse the radar point clouds and RGB images. Our radar object proposal network uses radar point clouds to generate 3D proposals from a set of 3D prior boxes. These proposals are mapped to the image and fed into a Radar Proposal Refinement (RPR) network for objectness score prediction and box refinement. The RPR network utilizes both radar information and image feature maps to generate accurate object proposals and distance estimations. The radar-based proposals are combined with image-based proposals generated by a modified Region Proposal Network (RPN). The RPN has a distance regression layer for estimating distance for every generated proposal. The radar-based and image-based proposals are merged and used in the next stage for object classification. Experiments on the challenging nuScenes dataset show our method outperforms other existing radar-camera fusion methods in the 2D object detection task while at the same time accurately estimates objects' distances.
Physically-Constrained Transfer Learning through Shared Abundance Space for Hyperspectral Image Classification
Aug 30, 2020

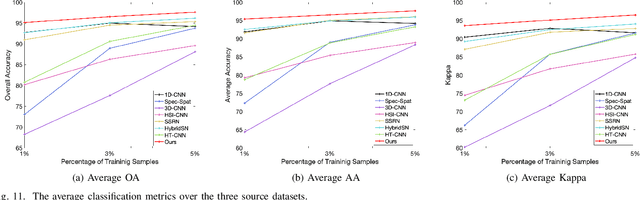
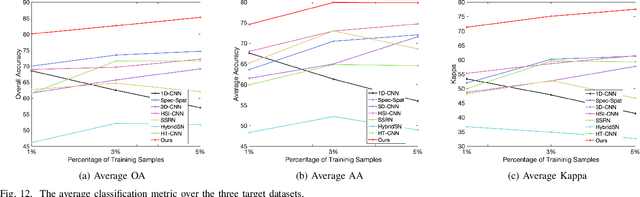
Hyperspectral image (HSI) classification is one of the most active research topics and has achieved promising results boosted by the recent development of deep learning. However, most state-of-the-art approaches tend to perform poorly when the training and testing images are on different domains, e.g., source domain and target domain, respectively, due to the spectral variability caused by different acquisition conditions. Transfer learning-based methods address this problem by pre-training in the source domain and fine-tuning on the target domain. Nonetheless, a considerable amount of data on the target domain has to be labeled and non-negligible computational resources are required to retrain the whole network. In this paper, we propose a new transfer learning scheme to bridge the gap between the source and target domains by projecting the HSI data from the source and target domains into a shared abundance space based on their own physical characteristics. In this way, the domain discrepancy would be largely reduced such that the model trained on the source domain could be applied on the target domain without extra efforts for data labeling or network retraining. The proposed method is referred to as physically-constrained transfer learning through shared abundance space (PCTL-SAS). Extensive experimental results demonstrate the superiority of the proposed method as compared to the state-of-the-art. The success of this endeavor would largely facilitate the deployment of HSI classification for real-world sensing scenarios.