 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
Modular Neural Image Signal Processing
Dec 09, 2025
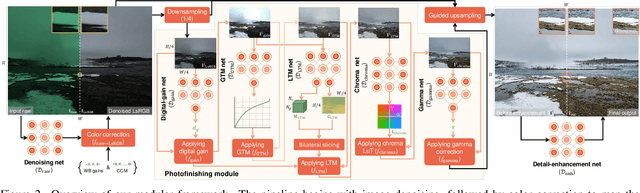
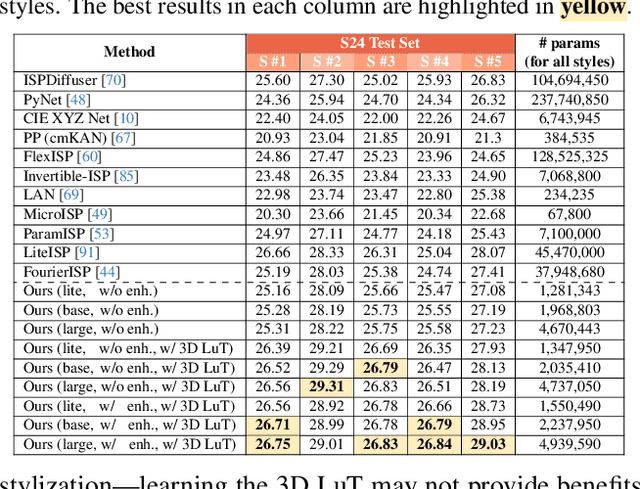
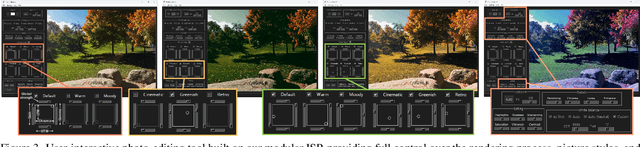
This paper presents a modular neural image signal processing (ISP) framework that processes raw inputs and renders high-quality display-referred images. Unlike prior neural ISP designs, our method introduces a high degree of modularity, providing full control over multiple intermediate stages of the rendering process.~This modular design not only achieves high rendering accuracy but also improves scalability, debuggability, generalization to unseen cameras, and flexibility to match different user-preference styles. To demonstrate the advantages of this design, we built a user-interactive photo-editing tool that leverages our neural ISP to support diverse editing operations and picture styles. The tool is carefully engineered to take advantage of the high-quality rendering of our neural ISP and to enable unlimited post-editable re-rendering. Our method is a fully learning-based framework with variants of different capacities, all of moderate size (ranging from ~0.5 M to ~3.9 M parameters for the entire pipeline), and consistently delivers competitive qualitative and quantitative results across multiple test sets. Watch the supplemental video at: https://youtu.be/ByhQjQSjxVM
Data-to-Dashboard: Multi-Agent LLM Framework for Insightful Visualization in Enterprise Analytics
May 29, 2025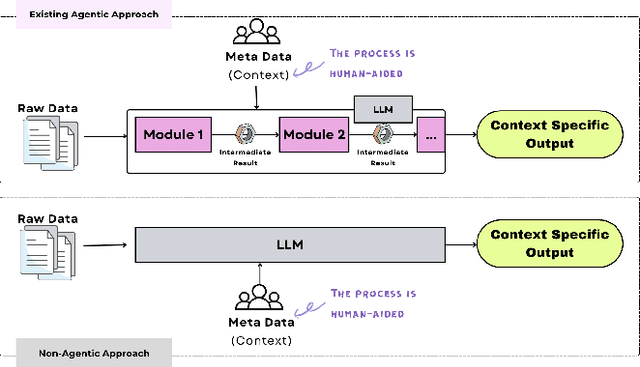
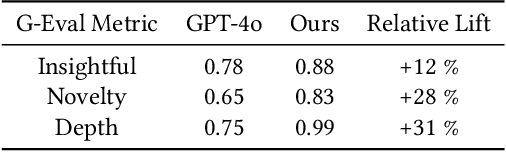
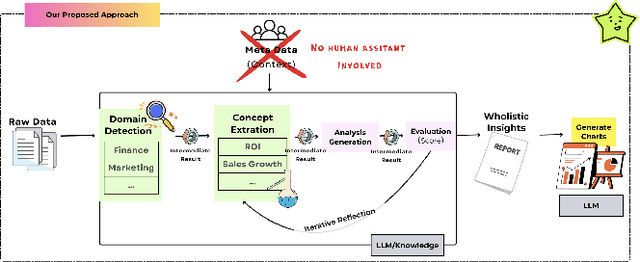

The rapid advancement of LLMs has led to the creation of diverse agentic systems in data analysis, utilizing LLMs' capabilities to improve insight generation and visualization. In this paper, we present an agentic system that automates the data-to-dashboard pipeline through modular LLM agents capable of domain detection, concept extraction, multi-perspective analysis generation, and iterative self-reflection. Unlike existing chart QA systems, our framework simulates the analytical reasoning process of business analysts by retrieving domain-relevant knowledge and adapting to diverse datasets without relying on closed ontologies or question templates. We evaluate our system on three datasets across different domains. Benchmarked against GPT-4o with a single-prompt baseline, our approach shows improved insightfulness, domain relevance, and analytical depth, as measured by tailored evaluation metrics and qualitative human assessment. This work contributes a novel modular pipeline to bridge the path from raw data to visualization, and opens new opportunities for human-in-the-loop validation by domain experts in business analytics. All code can be found here: https://github.com/77luvC/D2D_Data2Dashboard
LiTransProQA: an LLM-based Literary Translation evaluation metric with Professional Question Answering
May 09, 2025


The impact of Large Language Models (LLMs) has extended into literary domains. However, existing evaluation metrics prioritize mechanical accuracy over artistic expression and tend to overrate machine translation (MT) as being superior to experienced professional human translation. In the long run, this bias could result in a permanent decline in translation quality and cultural authenticity. In response to the urgent need for a specialized literary evaluation metric, we introduce LiTransProQA, a novel, reference-free, LLM-based question-answering framework designed specifically for literary translation evaluation. LiTransProQA uniquely integrates insights from professional literary translators and researchers, focusing on critical elements in literary quality assessment such as literary devices, cultural understanding, and authorial voice. Our extensive evaluation shows that while literary-finetuned XCOMET-XL yields marginal gains, LiTransProQA substantially outperforms current metrics, achieving up to 0.07 gain in correlation (ACC-EQ and Kendall's tau) and surpassing the best state-of-the-art metrics by over 15 points in adequacy assessments. Incorporating professional translator insights as weights further improves performance, highlighting the value of translator inputs. Notably, LiTransProQA approaches human-level evaluation performance comparable to trained linguistic annotators. It demonstrates broad applicability to open-source models such as LLaMA3.3-70b and Qwen2.5-32b, indicating its potential as an accessible and training-free literary evaluation metric and a valuable tool for evaluating texts that require local processing due to copyright or ethical considerations.
TransProQA: an LLM-based literary Translation evaluation metric with Professional Question Answering
May 08, 2025The impact of Large Language Models (LLMs) has extended into literary domains. However, existing evaluation metrics prioritize mechanical accuracy over artistic expression and tend to overrate machine translation (MT) as being superior to experienced professional human translation. In the long run, this bias could result in a permanent decline in translation quality and cultural authenticity. In response to the urgent need for a specialized literary evaluation metric, we introduce TransProQA, a novel, reference-free, LLM-based question-answering (QA) framework designed specifically for literary translation evaluation. TransProQA uniquely integrates insights from professional literary translators and researchers, focusing on critical elements in literary quality assessment such as literary devices, cultural understanding, and authorial voice. Our extensive evaluation shows that while literary-finetuned XCOMET-XL yields marginal gains, TransProQA substantially outperforms current metrics, achieving up to 0.07 gain in correlation (ACC-EQ and Kendall's tau) and surpassing the best state-of-the-art (SOTA) metrics by over 15 points in adequacy assessments. Incorporating professional translator insights as weights further improves performance, highlighting the value of translator inputs. Notably, TransProQA approaches human-level evaluation performance comparable to trained linguistic annotators. It demonstrates broad applicability to open-source models such as LLaMA3.3-70b and Qwen2.5-32b, indicating its potential as an accessible and training-free literary evaluation metric and a valuable tool for evaluating texts that require local processing due to copyright or ethical considerations.
Bayesian Reasoning Enabled by Spin-Orbit Torque Magnetic Tunnel Junctions
Apr 11, 2025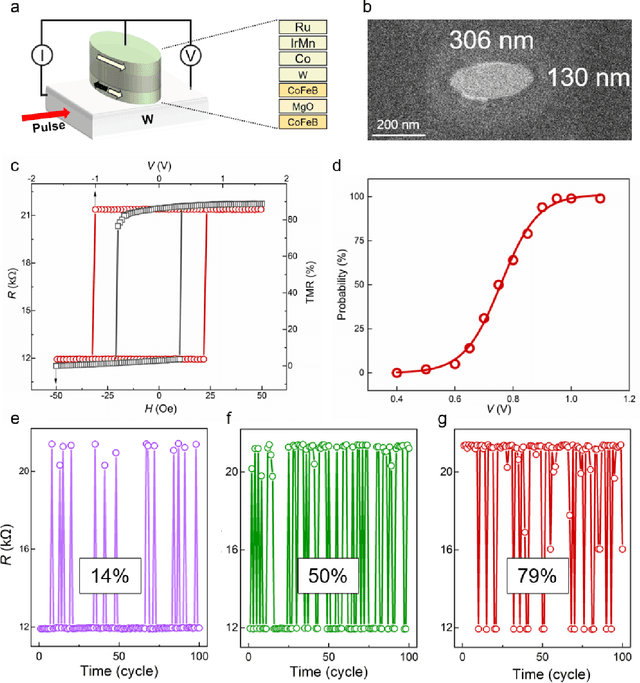
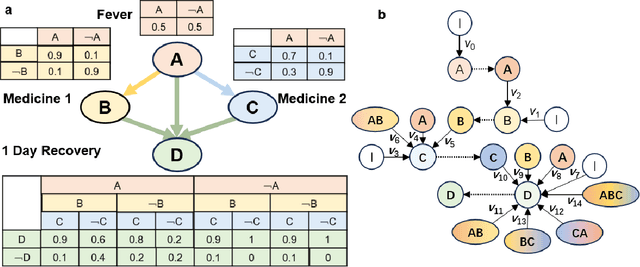
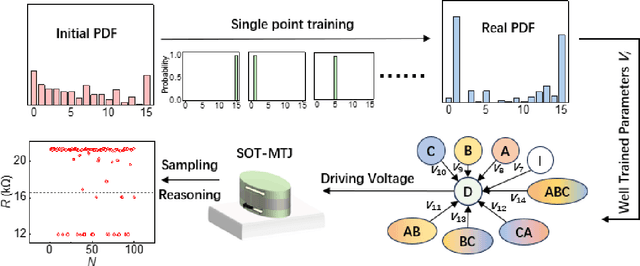
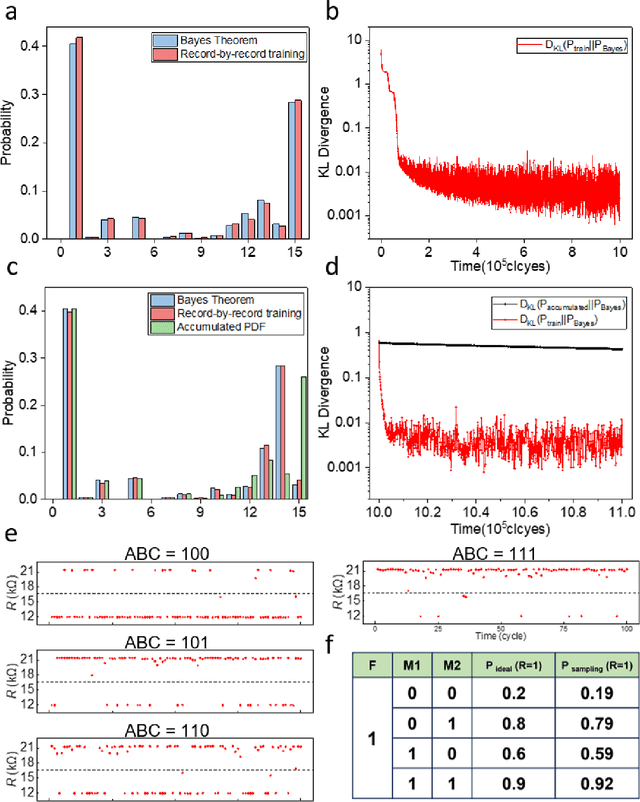
Bayesian networks play an increasingly important role in data mining, inference, and reasoning with the rapid development of artificial intelligence. In this paper, we present proof-of-concept experiments demonstrating the use of spin-orbit torque magnetic tunnel junctions (SOT-MTJs) in Bayesian network reasoning. Not only can the target probability distribution function (PDF) of a Bayesian network be precisely formulated by a conditional probability table as usual but also quantitatively parameterized by a probabilistic forward propagating neuron network. Moreover, the parameters of the network can also approach the optimum through a simple point-by point training algorithm, by leveraging which we do not need to memorize all historical data nor statistically summarize conditional probabilities behind them, significantly improving storage efficiency and economizing data pretreatment. Furthermore, we developed a simple medical diagnostic system using the SOT-MTJ as a random number generator and sampler, showcasing the application of SOT-MTJ-based Bayesian reasoning. This SOT-MTJ-based Bayesian reasoning shows great promise in the field of artificial probabilistic neural network, broadening the scope of spintronic device applications and providing an efficient and low-storage solution for complex reasoning tasks.
DeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Apr 10, 2025Reasoning-enabled large language models (LLMs) have recently demonstrated impressive performance in complex logical and mathematical tasks, yet their effectiveness in evaluating natural language generation remains unexplored. This study systematically compares reasoning-based LLMs (DeepSeek-R1 and OpenAI o3) with their non-reasoning counterparts across machine translation (MT) and text summarization (TS) evaluation tasks. We evaluate eight models across three architectural categories, including state-of-the-art reasoning models, their distilled variants (ranging from 8B to 70B parameters), and equivalent conventional, non-reasoning LLMs. Our experiments on WMT23 and SummEval benchmarks reveal that the benefits of reasoning capabilities are highly model and task-dependent: while OpenAI o3-mini models show consistent performance improvements with increased reasoning intensity, DeepSeek-R1 underperforms compared to its non-reasoning variant, with exception to certain aspects of TS evaluation. Correlation analysis demonstrates that increased reasoning token usage positively correlates with evaluation quality in o3-mini models. Furthermore, our results show that distillation of reasoning capabilities maintains reasonable performance in medium-sized models (32B) but degrades substantially in smaller variants (8B). This work provides the first comprehensive assessment of reasoning LLMs for NLG evaluation and offers insights into their practical use.
Distilling Textual Priors from LLM to Efficient Image Fusion
Apr 09, 2025



Multi-modality image fusion aims to synthesize a single, comprehensive image from multiple source inputs. Traditional approaches, such as CNNs and GANs, offer efficiency but struggle to handle low-quality or complex inputs. Recent advances in text-guided methods leverage large model priors to overcome these limitations, but at the cost of significant computational overhead, both in memory and inference time. To address this challenge, we propose a novel framework for distilling large model priors, eliminating the need for text guidance during inference while dramatically reducing model size. Our framework utilizes a teacher-student architecture, where the teacher network incorporates large model priors and transfers this knowledge to a smaller student network via a tailored distillation process. Additionally, we introduce spatial-channel cross-fusion module to enhance the model's ability to leverage textual priors across both spatial and channel dimensions. Our method achieves a favorable trade-off between computational efficiency and fusion quality. The distilled network, requiring only 10\% of the parameters and inference time of the teacher network, retains 90\% of its performance and outperforms existing SOTA methods. Extensive experiments demonstrate the effectiveness of our approach. The implementation will be made publicly available as an open-source resource.
Time-Aware Auto White Balance in Mobile Photography
Apr 08, 2025
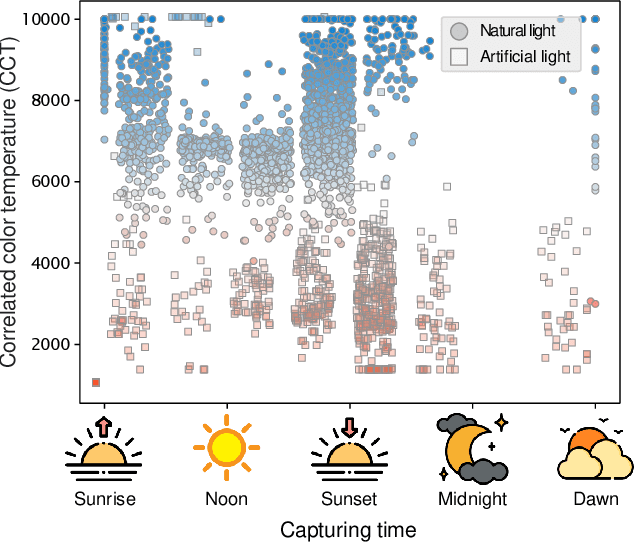
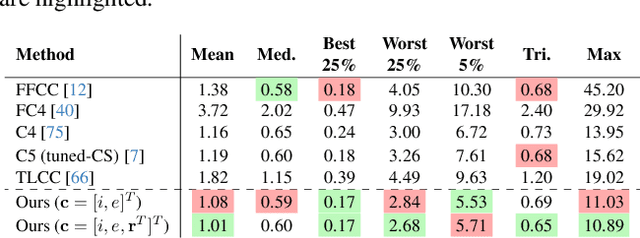
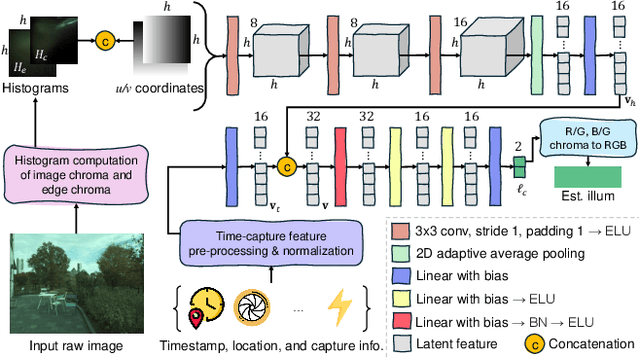
Cameras rely on auto white balance (AWB) to correct undesirable color casts caused by scene illumination and the camera's spectral sensitivity. This is typically achieved using an illuminant estimator that determines the global color cast solely from the color information in the camera's raw sensor image. Mobile devices provide valuable additional metadata-such as capture timestamp and geolocation-that offers strong contextual clues to help narrow down the possible illumination solutions. This paper proposes a lightweight illuminant estimation method that incorporates such contextual metadata, along with additional capture information and image colors, into a compact model (~5K parameters), achieving promising results, matching or surpassing larger models. To validate our method, we introduce a dataset of 3,224 smartphone images with contextual metadata collected at various times of day and under diverse lighting conditions. The dataset includes ground-truth illuminant colors, determined using a color chart, and user-preferred illuminants validated through a user study, providing a comprehensive benchmark for AWB evaluation.
Deep Cut-informed Graph Embedding and Clustering
Mar 09, 2025Graph clustering aims to divide the graph into different clusters. The recently emerging deep graph clustering approaches are largely built on graph neural networks (GNN). However, GNN is designed for general graph encoding and there is a common issue of representation collapse in existing GNN-based deep graph clustering algorithms. We attribute two main reasons for such issue: (i) the inductive bias of GNN models: GNNs tend to generate similar representations for proximal nodes. Since graphs often contain a non-negligible amount of inter-cluster links, the bias results in error message passing and leads to biased clustering; (ii) the clustering guided loss function: most traditional approaches strive to make all samples closer to pre-learned cluster centers, which cause a degenerate solution assigning all data points to a single label thus make all samples and less discriminative. To address these challenges, we investigate graph clustering from a graph cut perspective and propose an innovative and non-GNN-based Deep Cut-informed Graph embedding and Clustering framework, namely DCGC. This framework includes two modules: (i) cut-informed graph encoding; (ii) self-supervised graph clustering via optimal transport. For the encoding module, we derive a cut-informed graph embedding objective to fuse graph structure and attributes by minimizing their joint normalized cut. For the clustering module, we utilize the optimal transport theory to obtain the clustering assignments, which can balance the guidance of proximity to the pre-learned cluster center. With the above two tailored designs, DCGC is more suitable for the graph clustering task, which can effectively alleviate the problem of representation collapse and achieve better performance. We conduct extensive experiments to demonstrate that our method is simple but effective compared with benchmarks.