 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValueGround: Evaluating Culture-Conditioned Visual Value Grounding in MLLMs
Apr 07, 2026Cultural values are expressed not only through language but also through visual scenes and everyday social practices. Yet existing evaluations of cultural values in language models are almost entirely text-only, making it unclear whether models can ground culture-conditioned judgments when response options are visualized. We introduce ValueGround, a benchmark for evaluating culture-conditioned visual value grounding in multimodal large language models (MLLMs). Built from World Values Survey (WVS) questions, ValueGround uses minimally contrastive image pairs to represent opposing response options while controlling irrelevant variation. Given a country, a question, and an image pair, a model must choose the image that best matches the country's value tendency without access to the original response-option texts. Across six MLLMs and 13 countries, average accuracy drops from 72.8% in the text-only setting to 65.8% when options are visualized, despite 92.8% accuracy on option-image alignment. Stronger models are more robust, but all remain prone to prediction reversals. Our benchmark provides a controlled testbed for studying cross-modal transfer of culture-conditioned value judgments.
GerAV: Towards New Heights in German Authorship Verification using Fine-Tuned LLMs on a New Benchmark
Jan 20, 2026Authorship verification (AV) is the task of determining whether two texts were written by the same author and has been studied extensively, predominantly for English data. In contrast, large-scale benchmarks and systematic evaluations for other languages remain scarce. We address this gap by introducing GerAV, a comprehensive benchmark for German AV comprising over 600k labeled text pairs. GerAV is built from Twitter and Reddit data, with the Reddit part further divided into in-domain and cross-domain message-based subsets, as well as a profile-based subset. This design enables controlled analysis of the effects of data source, topical domain, and text length. Using the provided training splits, we conduct a systematic evaluation of strong baselines and state-of-the-art models and find that our best approach, a fine-tuned large language model, outperforms recent baselines by up to 0.09 absolute F1 score and surpasses GPT-5 in a zero-shot setting by 0.08. We further observe a trade-off between specialization and generalization: models trained on specific data types perform best under matching conditions but generalize less well across data regimes, a limitation that can be mitigated by combining training sources. Overall, GerAV provides a challenging and versatile benchmark for advancing research on German and cross-domain AV.
CROC: Evaluating and Training T2I Metrics with Pseudo- and Human-Labeled Contrastive Robustness Checks
May 16, 2025The assessment of evaluation metrics (meta-evaluation) is crucial for determining the suitability of existing metrics in text-to-image (T2I) generation tasks. Human-based meta-evaluation is costly and time-intensive, and automated alternatives are scarce. We address this gap and propose CROC: a scalable framework for automated Contrastive Robustness Checks that systematically probes and quantifies metric robustness by synthesizing contrastive test cases across a comprehensive taxonomy of image properties. With CROC, we generate a pseudo-labeled dataset (CROC$^{syn}$) of over one million contrastive prompt-image pairs to enable a fine-grained comparison of evaluation metrics. We also use the dataset to train CROCScore, a new metric that achieves state-of-the-art performance among open-source methods, demonstrating an additional key application of our framework. To complement this dataset, we introduce a human-supervised benchmark (CROC$^{hum}$) targeting especially challenging categories. Our results highlight robustness issues in existing metrics: for example, many fail on prompts involving negation, and all tested open-source metrics fail on at least 25% of cases involving correct identification of body parts.
DeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Apr 10, 2025Reasoning-enabled large language models (LLMs) have recently demonstrated impressive performance in complex logical and mathematical tasks, yet their effectiveness in evaluating natural language generation remains unexplored. This study systematically compares reasoning-based LLMs (DeepSeek-R1 and OpenAI o3) with their non-reasoning counterparts across machine translation (MT) and text summarization (TS) evaluation tasks. We evaluate eight models across three architectural categories, including state-of-the-art reasoning models, their distilled variants (ranging from 8B to 70B parameters), and equivalent conventional, non-reasoning LLMs. Our experiments on WMT23 and SummEval benchmarks reveal that the benefits of reasoning capabilities are highly model and task-dependent: while OpenAI o3-mini models show consistent performance improvements with increased reasoning intensity, DeepSeek-R1 underperforms compared to its non-reasoning variant, with exception to certain aspects of TS evaluation. Correlation analysis demonstrates that increased reasoning token usage positively correlates with evaluation quality in o3-mini models. Furthermore, our results show that distillation of reasoning capabilities maintains reasonable performance in medium-sized models (32B) but degrades substantially in smaller variants (8B). This work provides the first comprehensive assessment of reasoning LLMs for NLG evaluation and offers insights into their practical use.
ScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation?
Dec 03, 2024



Multimodal large language models (LLMs) have demonstrated impressive capabilities in generating high-quality images from textual instructions. However, their performance in generating scientific images--a critical application for accelerating scientific progress--remains underexplored. In this work, we address this gap by introducing ScImage, a benchmark designed to evaluate the multimodal capabilities of LLMs in generating scientific images from textual descriptions. ScImage assesses three key dimensions of understanding: spatial, numeric, and attribute comprehension, as well as their combinations, focusing on the relationships between scientific objects (e.g., squares, circles). We evaluate five models, GPT-4o, Llama, AutomaTikZ, Dall-E, and StableDiffusion, using two modes of output generation: code-based outputs (Python, TikZ) and direct raster image generation. Additionally, we examine four different input languages: English, German, Farsi, and Chinese. Our evaluation, conducted with 11 scientists across three criteria (correctness, relevance, and scientific accuracy), reveals that while GPT-4o produces outputs of decent quality for simpler prompts involving individual dimensions such as spatial, numeric, or attribute understanding in isolation, all models face challenges in this task, especially for more complex prompts.
PrExMe! Large Scale Prompt Exploration of Open Source LLMs for Machine Translation and Summarization Evaluation
Jun 26, 2024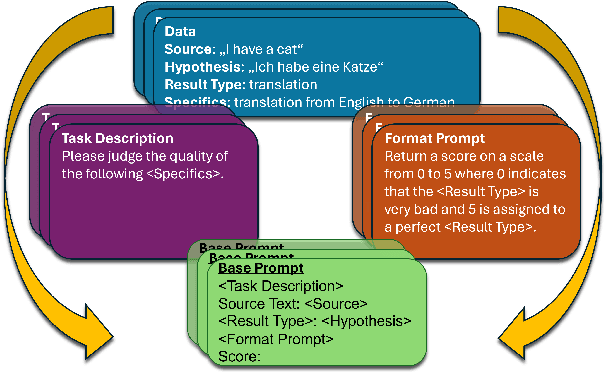

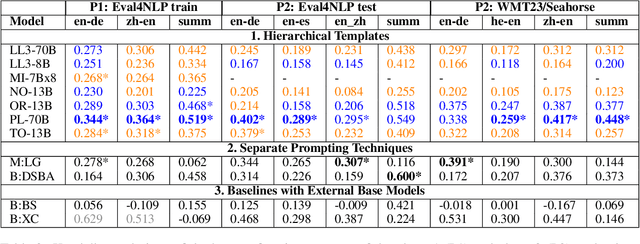
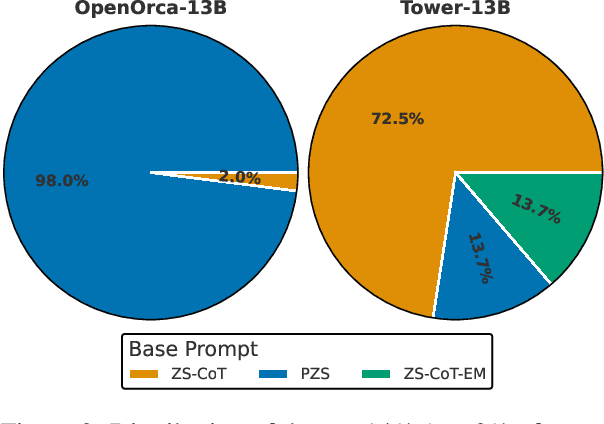
Large language models (LLMs) have revolutionized the field of NLP. Notably, their in-context learning capabilities also enable their use as evaluation metrics for natural language generation, making them particularly advantageous in low-resource scenarios and time-restricted applications. In this work, we introduce PrExMe, a large-scale prompt exploration for metrics, where we evaluate more than 720 prompt templates for open-source LLM-based metrics on machine translation (MT) and summarization datasets, totalling over 6.6M evaluations. This extensive comparison (1) serves as a benchmark of the performance of recent open-source LLMs as metrics and (2) explores the stability and variability of different prompting strategies. We discover that, on the one hand, there are scenarios for which prompts are stable. For instance, some LLMs show idiosyncratic preferences and favor to grade generated texts with textual labels while others prefer to return numeric scores. On the other hand, the stability of prompts and model rankings can be susceptible to seemingly innocuous changes. For example, changing the requested output format from "0 to 100" to "-1 to +1" can strongly affect the rankings in our evaluation. Our study contributes to understanding the impact of different prompting approaches on LLM-based metrics for MT and summarization evaluation, highlighting the most stable prompting patterns and potential limitations.
NLLG Quarterly arXiv Report 09/23: What are the most influential current AI Papers?
Dec 09, 2023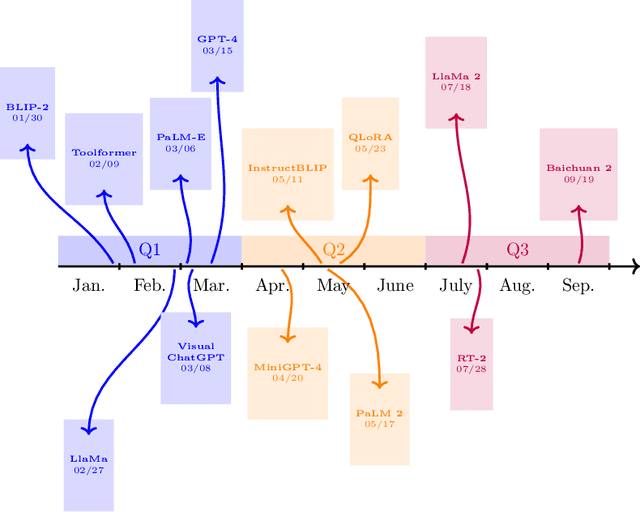

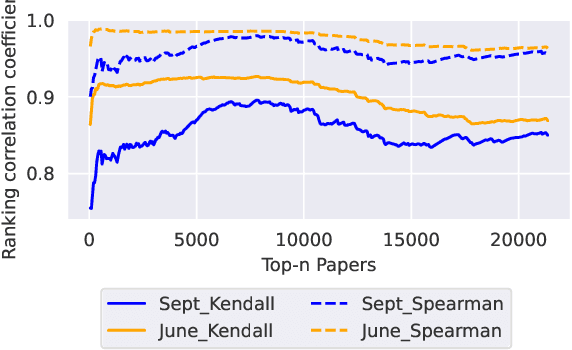
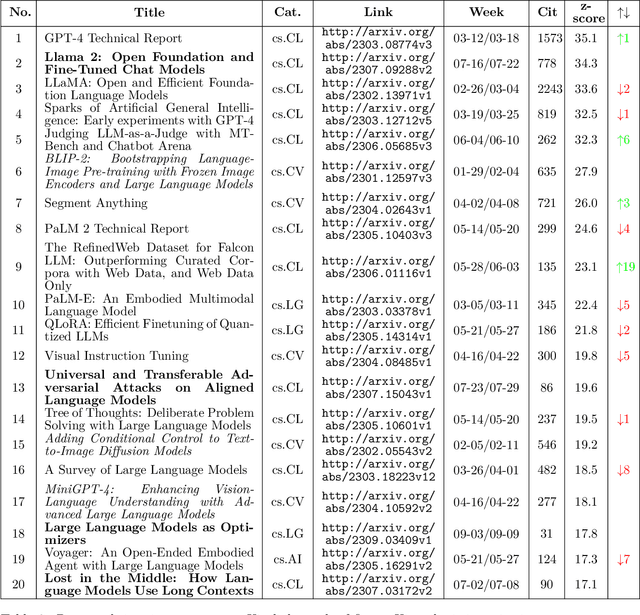
Artificial Intelligence (AI) has witnessed rapid growth, especially in the subfields Natural Language Processing (NLP), Machine Learning (ML) and Computer Vision (CV). Keeping pace with this rapid progress poses a considerable challenge for researchers and professionals in the field. In this arXiv report, the second of its kind, which covers the period from January to September 2023, we aim to provide insights and analysis that help navigate these dynamic areas of AI. We accomplish this by 1) identifying the top-40 most cited papers from arXiv in the given period, comparing the current top-40 papers to the previous report, which covered the period January to June; 2) analyzing dataset characteristics and keyword popularity; 3) examining the global sectoral distribution of institutions to reveal differences in engagement across geographical areas. Our findings highlight the continued dominance of NLP: while only 16% of all submitted papers have NLP as primary category (more than 25% have CV and ML as primary category), 50% of the most cited papers have NLP as primary category, 90% of which target LLMs. Additionally, we show that i) the US dominates among both top-40 and top-9k papers, followed by China; ii) Europe clearly lags behind and is hardly represented in the top-40 most cited papers; iii) US industry is largely overrepresented in the top-40 most influential papers.
The Eval4NLP 2023 Shared Task on Prompting Large Language Models as Explainable Metrics
Oct 30, 2023



With an increasing number of parameters and pre-training data, generative large language models (LLMs) have shown remarkable capabilities to solve tasks with minimal or no task-related examples. Notably, LLMs have been successfully employed as evaluation metrics in text generation tasks. Within this context, we introduce the Eval4NLP 2023 shared task that asks participants to explore prompting and score extraction for machine translation (MT) and summarization evaluation. Specifically, we propose a novel competition setting in which we select a list of allowed LLMs and disallow fine-tuning to ensure a focus on prompting. We present an overview of participants' approaches and evaluate them on a new reference-free test set spanning three language pairs for MT and a summarization dataset. Notably, despite the task's restrictions, the best-performing systems achieve results on par with or even surpassing recent reference-free metrics developed using larger models, including GEMBA and Comet-Kiwi-XXL. Finally, as a separate track, we perform a small-scale human evaluation of the plausibility of explanations given by the LLMs.
NLLG Quarterly arXiv Report 06/23: What are the most influential current AI Papers?
Jul 31, 2023
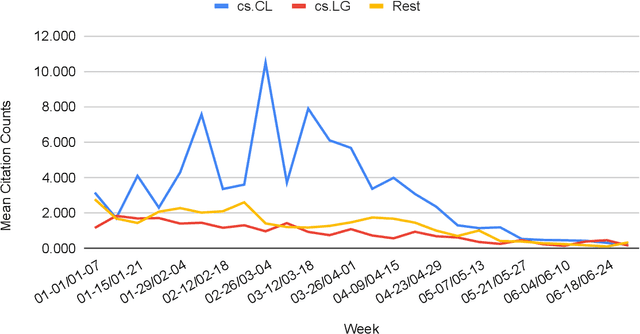
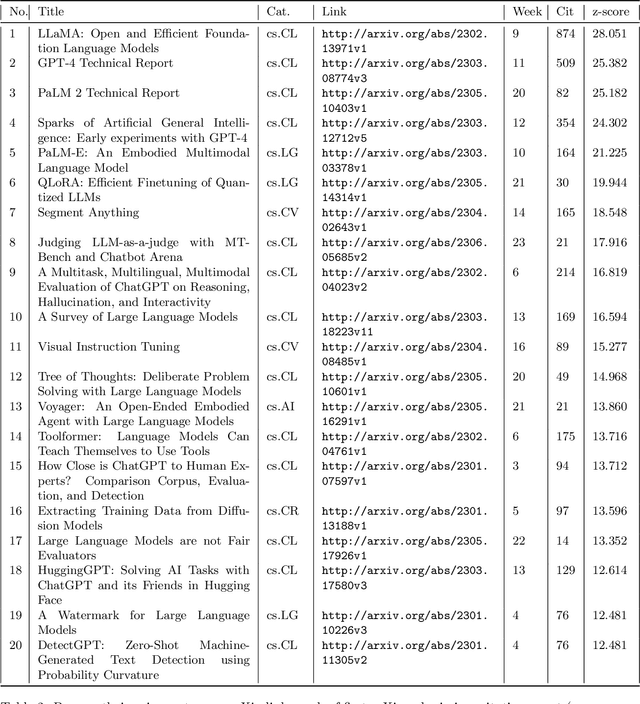
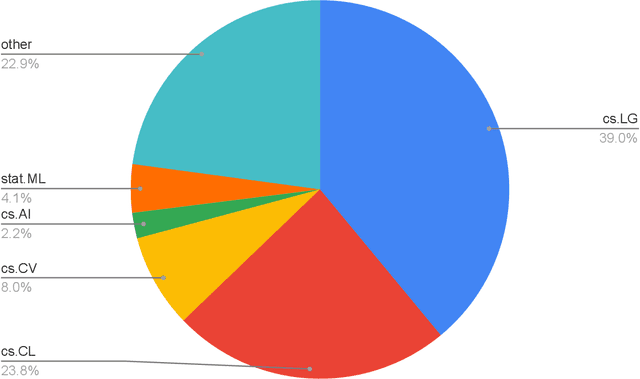
The rapid growth of information in the field of Generative Artificial Intelligence (AI), particularly in the subfields of Natural Language Processing (NLP) and Machine Learning (ML), presents a significant challenge for researchers and practitioners to keep pace with the latest developments. To address the problem of information overload, this report by the Natural Language Learning Group at Bielefeld University focuses on identifying the most popular papers on arXiv, with a specific emphasis on NLP and ML. The objective is to offer a quick guide to the most relevant and widely discussed research, aiding both newcomers and established researchers in staying abreast of current trends. In particular, we compile a list of the 40 most popular papers based on normalized citation counts from the first half of 2023. We observe the dominance of papers related to Large Language Models (LLMs) and specifically ChatGPT during the first half of 2023, with the latter showing signs of declining popularity more recently, however. Further, NLP related papers are the most influential (around 60\% of top papers) even though there are twice as many ML related papers in our data. Core issues investigated in the most heavily cited papers are: LLM efficiency, evaluation techniques, ethical considerations, embodied agents, and problem-solving with LLMs. Additionally, we examine the characteristics of top papers in comparison to others outside the top-40 list (noticing the top paper's focus on LLM related issues and higher number of co-authors) and analyze the citation distributions in our dataset, among others.
Towards Explainable Evaluation Metrics for Machine Translation
Jun 22, 2023



Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics for machine translation (for example, COMET or BERTScore) are based on black-box large language models. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are more transparent. To foster more widespread acceptance of novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties as well as key goals of explainable machine translation metrics and provide a comprehensive synthesis of recent techniques, relating them to our established goals and properties. In this context, we also discuss the latest state-of-the-art approaches to explainable metrics based on generative models such as ChatGPT and GPT4. Finally, we contribute a vision of next-generation approaches, including natural language explanations. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent machine translation systems.