 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Reproduction: A Paired-Task Framework for Assessing LLM Comprehension and Creativity in Literary Translation
Apr 20, 2026Large language models (LLMs) are increasingly used for creative tasks such as literary translation. Yet translational creativity remains underexplored and is rarely evaluated at scale, while source-text comprehension is typically studied in isolation, despite the fact that, in professional translation, comprehension and creativity are tightly intertwined. We address these gaps with a paired-task framework applied to literary excerpts from 11 books. Task 1 assesses source-text comprehension, and Task 2 evaluates translational creativity through Units of Creative Potential (UCPs), such as metaphors and wordplay. Using a scalable evaluation setup that combines expert human annotations with UCP-based automatic scoring, we benchmark 23 models and four creativity-oriented prompts. Our findings show that strong comprehension does not translate into human-level creativity: models often produce literal or contextually inappropriate renderings, with particularly large gaps for the more distant English-Chinese language pair. Creativity-oriented prompts yield only modest gains, and only one model, Mistral-Large, comes close to human-level creativity (0.167 vs. 0.246). Across all model-prompt combinations, only three exceed a creativity score of 0.1, while the rest remain at or near zero.
Randomly Removing 50% of Dimensions in Text Embeddings has Minimal Impact on Retrieval and Classification Tasks
Aug 25, 2025In this paper, we study the surprising impact that truncating text embeddings has on downstream performance. We consistently observe across 6 state-of-the-art text encoders and 26 downstream tasks, that randomly removing up to 50% of embedding dimensions results in only a minor drop in performance, less than 10%, in retrieval and classification tasks. Given the benefits of using smaller-sized embeddings, as well as the potential insights about text encoding, we study this phenomenon and find that, contrary to what is suggested in prior work, this is not the result of an ineffective use of representation space. Instead, we find that a large number of uniformly distributed dimensions actually cause an increase in performance when removed. This would explain why, on average, removing a large number of embedding dimensions results in a marginal drop in performance. We make similar observations when truncating the embeddings used by large language models to make next-token predictions on generative tasks, suggesting that this phenomenon is not isolated to classification or retrieval tasks.
TikZero: Zero-Shot Text-Guided Graphics Program Synthesis
Mar 14, 2025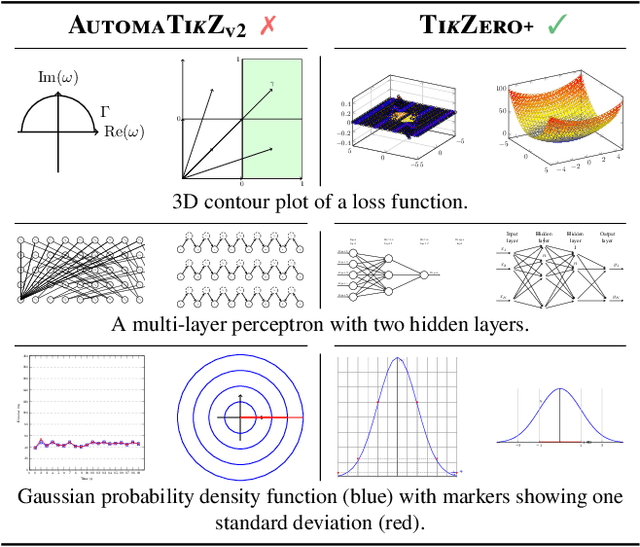
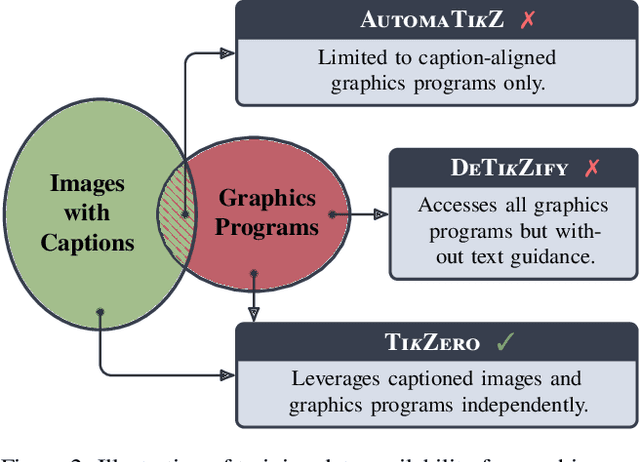

With the rise of generative AI, synthesizing figures from text captions becomes a compelling application. However, achieving high geometric precision and editability requires representing figures as graphics programs in languages like TikZ, and aligned training data (i.e., graphics programs with captions) remains scarce. Meanwhile, large amounts of unaligned graphics programs and captioned raster images are more readily available. We reconcile these disparate data sources by presenting TikZero, which decouples graphics program generation from text understanding by using image representations as an intermediary bridge. It enables independent training on graphics programs and captioned images and allows for zero-shot text-guided graphics program synthesis during inference. We show that our method substantially outperforms baselines that can only operate with caption-aligned graphics programs. Furthermore, when leveraging caption-aligned graphics programs as a complementary training signal, TikZero matches or exceeds the performance of much larger models, including commercial systems like GPT-4o. Our code, datasets, and select models are publicly available.
Enriching Social Science Research via Survey Item Linking
Dec 20, 2024Questions within surveys, called survey items, are used in the social sciences to study latent concepts, such as the factors influencing life satisfaction. Instead of using explicit citations, researchers paraphrase the content of the survey items they use in-text. However, this makes it challenging to find survey items of interest when comparing related work. Automatically parsing and linking these implicit mentions to survey items in a knowledge base can provide more fine-grained references. We model this task, called Survey Item Linking (SIL), in two stages: mention detection and entity disambiguation. Due to an imprecise definition of the task, existing datasets used for evaluating the performance for SIL are too small and of low-quality. We argue that latent concepts and survey item mentions should be differentiated. To this end, we create a high-quality and richly annotated dataset consisting of 20,454 English and German sentences. By benchmarking deep learning systems for each of the two stages independently and sequentially, we demonstrate that the task is feasible, but observe that errors propagate from the first stage, leading to a lower overall task performance. Moreover, mentions that require the context of multiple sentences are more challenging to identify for models in the first stage. Modeling the entire context of a document and combining the two stages into an end-to-end system could mitigate these problems in future work, and errors could additionally be reduced by collecting more diverse data and by improving the quality of the knowledge base. The data and code are available at https://github.com/e-tornike/SIL .
ScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation?
Dec 03, 2024



Multimodal large language models (LLMs) have demonstrated impressive capabilities in generating high-quality images from textual instructions. However, their performance in generating scientific images--a critical application for accelerating scientific progress--remains underexplored. In this work, we address this gap by introducing ScImage, a benchmark designed to evaluate the multimodal capabilities of LLMs in generating scientific images from textual descriptions. ScImage assesses three key dimensions of understanding: spatial, numeric, and attribute comprehension, as well as their combinations, focusing on the relationships between scientific objects (e.g., squares, circles). We evaluate five models, GPT-4o, Llama, AutomaTikZ, Dall-E, and StableDiffusion, using two modes of output generation: code-based outputs (Python, TikZ) and direct raster image generation. Additionally, we examine four different input languages: English, German, Farsi, and Chinese. Our evaluation, conducted with 11 scientists across three criteria (correctness, relevance, and scientific accuracy), reveals that while GPT-4o produces outputs of decent quality for simpler prompts involving individual dimensions such as spatial, numeric, or attribute understanding in isolation, all models face challenges in this task, especially for more complex prompts.
DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ
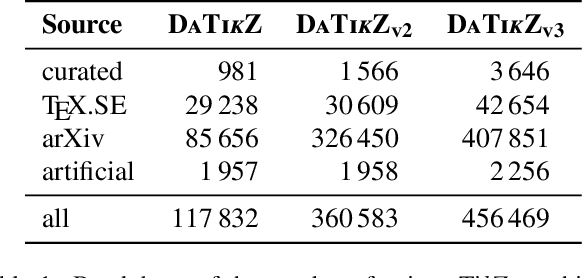
May 28, 2024Creating high-quality scientific figures can be time-consuming and challenging, even though sketching ideas on paper is relatively easy. Furthermore, recreating existing figures that are not stored in formats preserving semantic information is equally complex. To tackle this problem, we introduce DeTikZify, a novel multimodal language model that automatically synthesizes scientific figures as semantics-preserving TikZ graphics programs based on sketches and existing figures. To achieve this, we create three new datasets: DaTikZv2, the largest TikZ dataset to date, containing over 360k human-created TikZ graphics; SketchFig, a dataset that pairs hand-drawn sketches with their corresponding scientific figures; and SciCap++, a collection of diverse scientific figures and associated metadata. We train DeTikZify on SciCap++ and DaTikZv2, along with synthetically generated sketches learned from SketchFig. We also introduce an MCTS-based inference algorithm that enables DeTikZify to iteratively refine its outputs without the need for additional training. Through both automatic and human evaluation, we demonstrate that DeTikZify outperforms commercial Claude 3 and GPT-4V in synthesizing TikZ programs, with the MCTS algorithm effectively boosting its performance. We make our code, models, and datasets publicly available.
ROUGE-K: Do Your Summaries Have Keywords?
Mar 08, 2024



Keywords, that is, content-relevant words in summaries play an important role in efficient information conveyance, making it critical to assess if system-generated summaries contain such informative words during evaluation. However, existing evaluation metrics for extreme summarization models do not pay explicit attention to keywords in summaries, leaving developers ignorant of their presence. To address this issue, we present a keyword-oriented evaluation metric, dubbed ROUGE-K, which provides a quantitative answer to the question of -- \textit{How well do summaries include keywords?} Through the lens of this keyword-aware metric, we surprisingly find that a current strong baseline model often misses essential information in their summaries. Our analysis reveals that human annotators indeed find the summaries with more keywords to be more relevant to the source documents. This is an important yet previously overlooked aspect in evaluating summarization systems. Finally, to enhance keyword inclusion, we propose four approaches for incorporating word importance into a transformer-based model and experimentally show that it enables guiding models to include more keywords while keeping the overall quality. Our code is released at https://github.com/sobamchan/rougek.
ACLSum: A New Dataset for Aspect-based Summarization of Scientific Publications
Mar 08, 2024



Extensive efforts in the past have been directed toward the development of summarization datasets. However, a predominant number of these resources have been (semi)-automatically generated, typically through web data crawling, resulting in subpar resources for training and evaluating summarization systems, a quality compromise that is arguably due to the substantial costs associated with generating ground-truth summaries, particularly for diverse languages and specialized domains. To address this issue, we present ACLSum, a novel summarization dataset carefully crafted and evaluated by domain experts. In contrast to previous datasets, ACLSum facilitates multi-aspect summarization of scientific papers, covering challenges, approaches, and outcomes in depth. Through extensive experiments, we evaluate the quality of our resource and the performance of models based on pretrained language models and state-of-the-art large language models (LLMs). Additionally, we explore the effectiveness of extractive versus abstractive summarization within the scholarly domain on the basis of automatically discovered aspects. Our results corroborate previous findings in the general domain and indicate the general superiority of end-to-end aspect-based summarization. Our data is released at https://github.com/sobamchan/aclsum.
Do LLMs Dream of Ontologies?
Jan 26, 2024
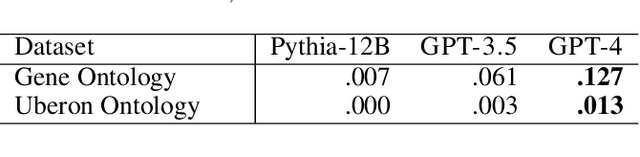
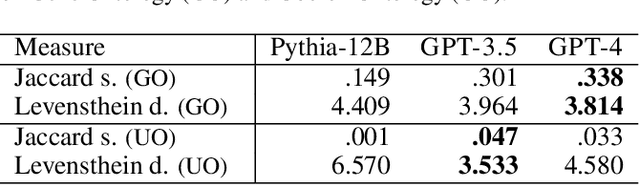

Large language models (LLMs) have recently revolutionized automated text understanding and generation. The performance of these models relies on the high number of parameters of the underlying neural architectures, which allows LLMs to memorize part of the vast quantity of data seen during the training. This paper investigates whether and to what extent general-purpose pre-trained LLMs have memorized information from known ontologies. Our results show that LLMs partially know ontologies: they can, and do indeed, memorize concepts from ontologies mentioned in the text, but the level of memorization of their concepts seems to vary proportionally to their popularity on the Web, the primary source of their training material. We additionally propose new metrics to estimate the degree of memorization of ontological information in LLMs by measuring the consistency of the output produced across different prompt repetitions, query languages, and degrees of determinism.
Vicinal Risk Minimization for Few-Shot Cross-lingual Transfer in Abusive Language Detection
Nov 03, 2023Cross-lingual transfer learning from high-resource to medium and low-resource languages has shown encouraging results. However, the scarcity of resources in target languages remains a challenge. In this work, we resort to data augmentation and continual pre-training for domain adaptation to improve cross-lingual abusive language detection. For data augmentation, we analyze two existing techniques based on vicinal risk minimization and propose MIXAG, a novel data augmentation method which interpolates pairs of instances based on the angle of their representations. Our experiments involve seven languages typologically distinct from English and three different domains. The results reveal that the data augmentation strategies can enhance few-shot cross-lingual abusive language detection. Specifically, we observe that consistently in all target languages, MIXAG improves significantly in multidomain and multilingual environments. Finally, we show through an error analysis how the domain adaptation can favour the class of abusive texts (reducing false negatives), but at the same time, declines the precision of the abusive language detection model.