 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicinal Risk Minimization for Few-Shot Cross-lingual Transfer in Abusive Language Detection
Nov 03, 2023Cross-lingual transfer learning from high-resource to medium and low-resource languages has shown encouraging results. However, the scarcity of resources in target languages remains a challenge. In this work, we resort to data augmentation and continual pre-training for domain adaptation to improve cross-lingual abusive language detection. For data augmentation, we analyze two existing techniques based on vicinal risk minimization and propose MIXAG, a novel data augmentation method which interpolates pairs of instances based on the angle of their representations. Our experiments involve seven languages typologically distinct from English and three different domains. The results reveal that the data augmentation strategies can enhance few-shot cross-lingual abusive language detection. Specifically, we observe that consistently in all target languages, MIXAG improves significantly in multidomain and multilingual environments. Finally, we show through an error analysis how the domain adaptation can favour the class of abusive texts (reducing false negatives), but at the same time, declines the precision of the abusive language detection model.
Zero and Few-shot Learning for Author Profiling
Apr 22, 2022
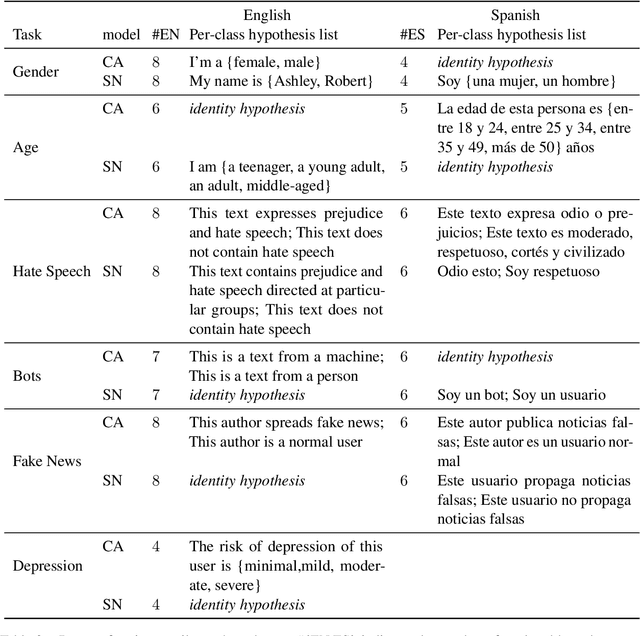
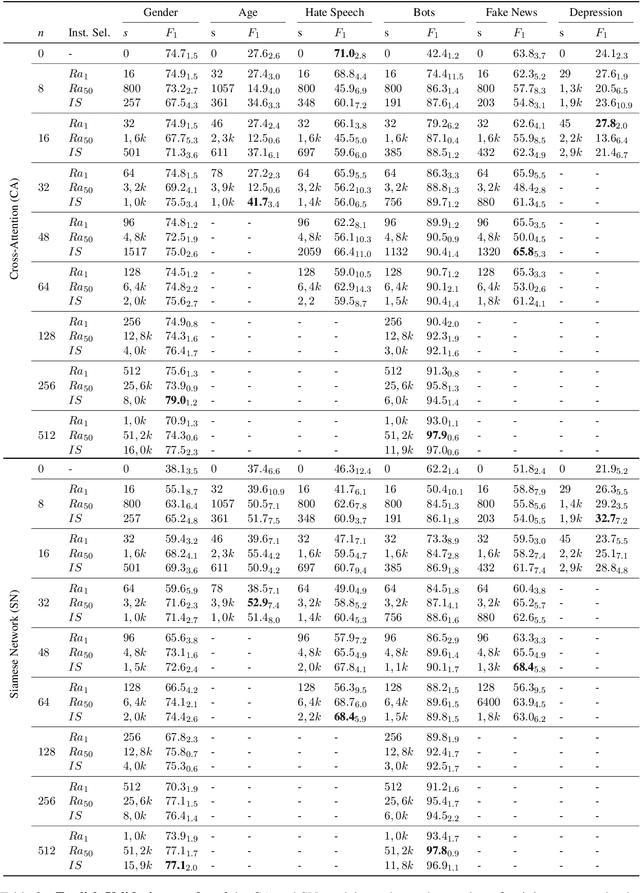
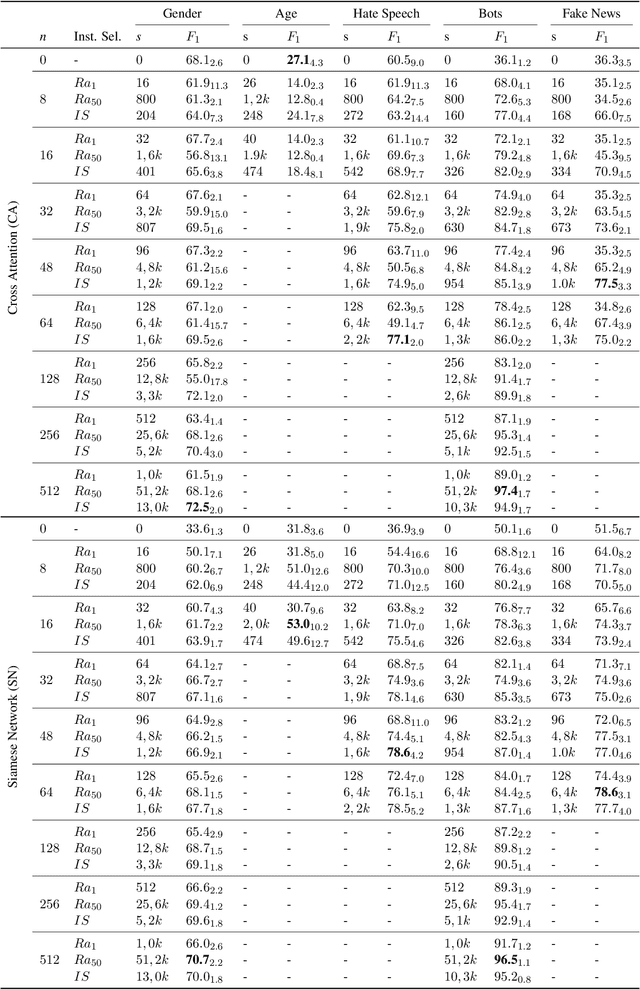
Author profiling classifies author characteristics by analyzing how language is shared among people. In this work, we study that task from a low-resource viewpoint: using little or no training data. We explore different zero and few-shot models based on entailment and evaluate our systems on several profiling tasks in Spanish and English. In addition, we study the effect of both the entailment hypothesis and the size of the few-shot training sample. We find that entailment-based models out-perform supervised text classifiers based on roberta-XLM and that we can reach 80% of the accuracy of previous approaches using less than 50\% of the training data on average.