 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of AuTexTification at IberLEF 2023: Detection and Attribution of Machine-Generated Text in Multiple Domains
Sep 20, 2023This paper presents the overview of the AuTexTification shared task as part of the IberLEF 2023 Workshop in Iberian Languages Evaluation Forum, within the framework of the SEPLN 2023 conference. AuTexTification consists of two subtasks: for Subtask 1, participants had to determine whether a text is human-authored or has been generated by a large language model. For Subtask 2, participants had to attribute a machine-generated text to one of six different text generation models. Our AuTexTification 2023 dataset contains more than 160.000 texts across two languages (English and Spanish) and five domains (tweets, reviews, news, legal, and how-to articles). A total of 114 teams signed up to participate, of which 36 sent 175 runs, and 20 of them sent their working notes. In this overview, we present the AuTexTification dataset and task, the submitted participating systems, and the results.
Zero and Few-shot Learning for Author Profiling
Apr 22, 2022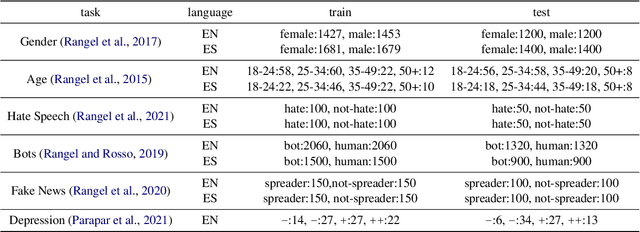
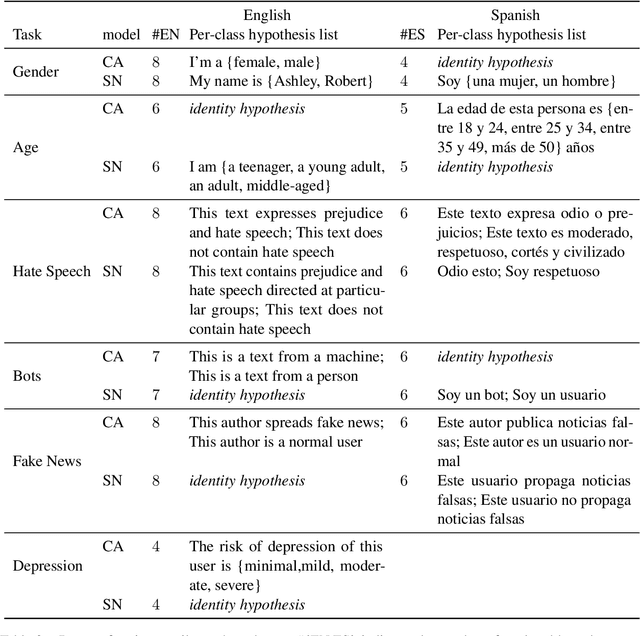
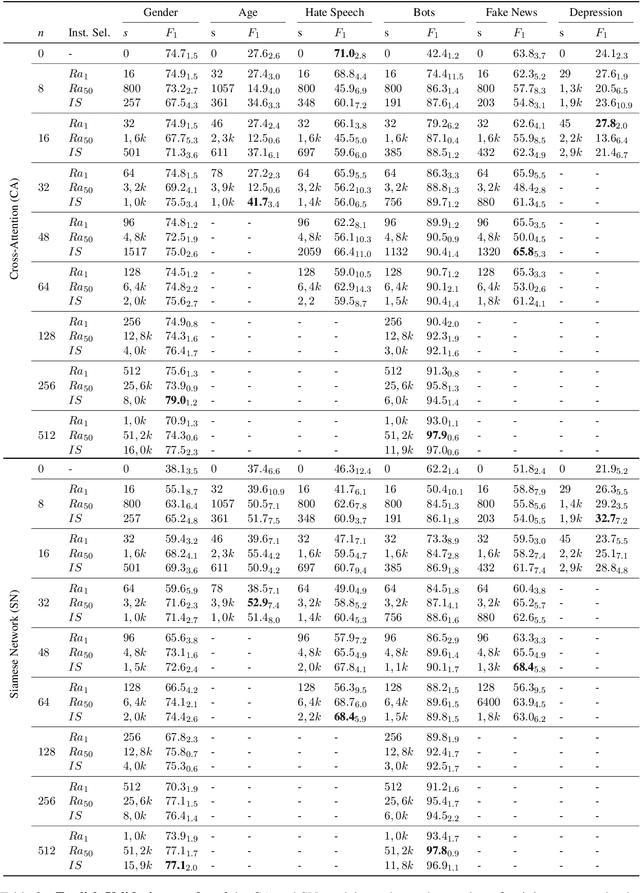
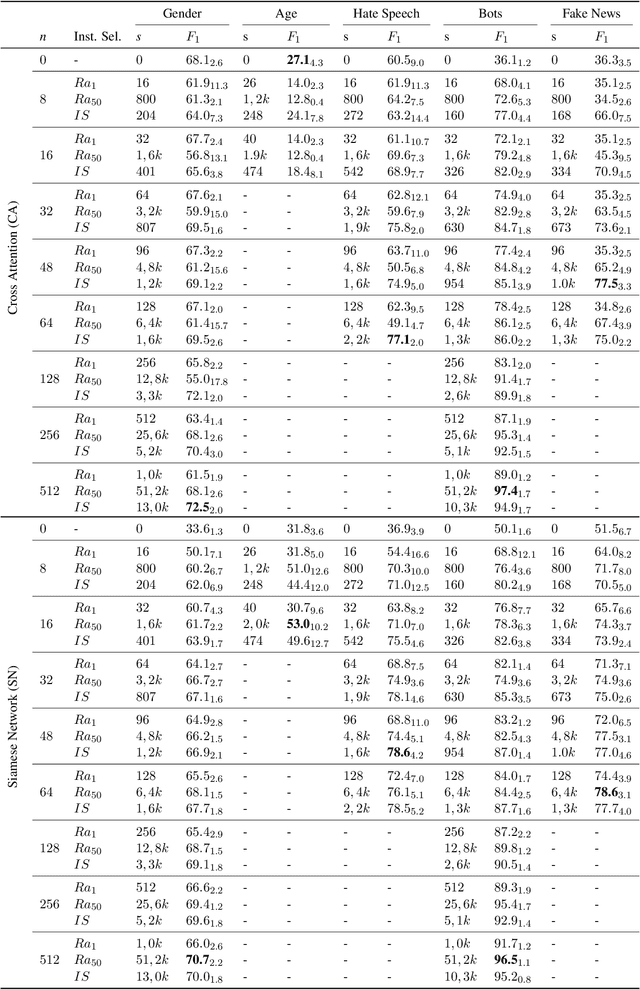
Author profiling classifies author characteristics by analyzing how language is shared among people. In this work, we study that task from a low-resource viewpoint: using little or no training data. We explore different zero and few-shot models based on entailment and evaluate our systems on several profiling tasks in Spanish and English. In addition, we study the effect of both the entailment hypothesis and the size of the few-shot training sample. We find that entailment-based models out-perform supervised text classifiers based on roberta-XLM and that we can reach 80% of the accuracy of previous approaches using less than 50\% of the training data on average.
FakeFlow: Fake News Detection by Modeling the Flow of Affective Information
Jan 24, 2021
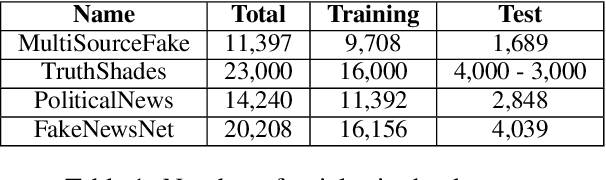


Fake news articles often stir the readers' attention by means of emotional appeals that arouse their feelings. Unlike in short news texts, authors of longer articles can exploit such affective factors to manipulate readers by adding exaggerations or fabricating events, in order to affect the readers' emotions. To capture this, we propose in this paper to model the flow of affective information in fake news articles using a neural architecture. The proposed model, FakeFlow, learns this flow by combining topic and affective information extracted from text. We evaluate the model's performance with several experiments on four real-world datasets. The results show that FakeFlow achieves superior results when compared against state-of-the-art methods, thus confirming the importance of capturing the flow of the affective information in news articles.
An Emotional Analysis of False Information in Social Media and News Articles
Aug 26, 2019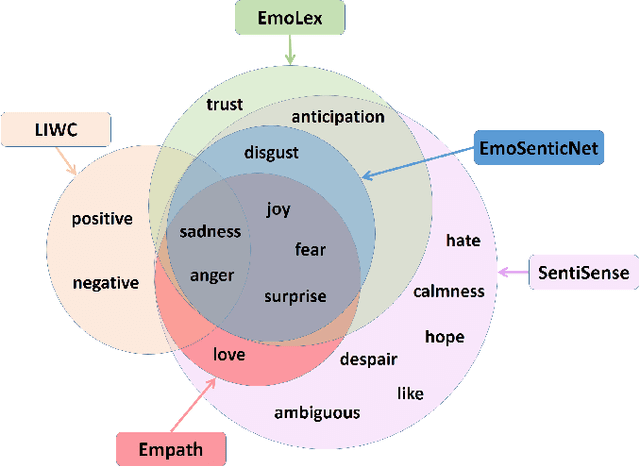
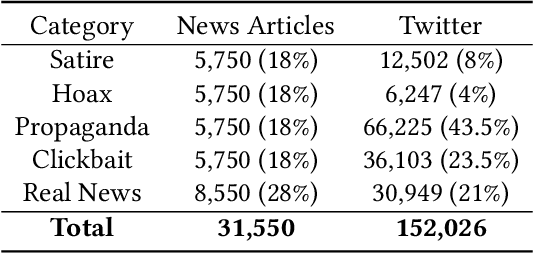
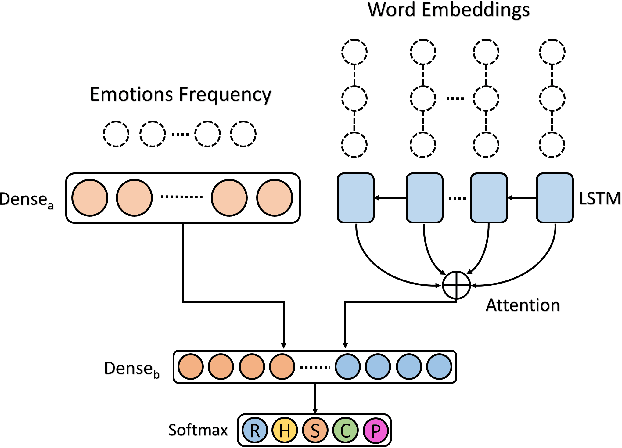
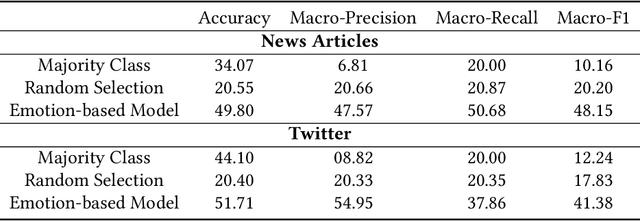
Fake news is risky since it has been created to manipulate the readers' opinions and beliefs. In this work, we compared the language of false news to the real one of real news from an emotional perspective, considering a set of false information types (propaganda, hoax, clickbait, and satire) from social media and online news articles sources. Our experiments showed that false information has different emotional patterns in each of its types, and emotions play a key role in deceiving the reader. Based on that, we proposed a LSTM neural network model that is emotionally-infused to detect false news.
A Low Dimensionality Representation for Language Variety Identification
May 30, 2017



Language variety identification aims at labelling texts in a native language (e.g. Spanish, Portuguese, English) with its specific variation (e.g. Argentina, Chile, Mexico, Peru, Spain; Brazil, Portugal; UK, US). In this work we propose a low dimensionality representation (LDR) to address this task with five different varieties of Spanish: Argentina, Chile, Mexico, Peru and Spain. We compare our LDR method with common state-of-the-art representations and show an increase in accuracy of ~35%. Furthermore, we compare LDR with two reference distributed representation models. Experimental results show competitive performance while dramatically reducing the dimensionality --and increasing the big data suitability-- to only 6 features per variety. Additionally, we analyse the behaviour of the employed machine learning algorithms and the most discriminating features. Finally, we employ an alternative dataset to test the robustness of our low dimensionality representation with another set of similar languages.