 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Handling Coreference Resolution in Aspect Level Sentiment Classification by Fine-Tuning Language Models
Jul 11, 2023Customer feedback is invaluable to companies as they refine their products. Monitoring customer feedback can be automated with Aspect Level Sentiment Classification (ALSC) which allows us to analyse specific aspects of the products in reviews. Large Language Models (LLMs) are the heart of many state-of-the-art ALSC solutions, but they perform poorly in some scenarios requiring Coreference Resolution (CR). In this work, we propose a framework to improve an LLM's performance on CR-containing reviews by fine tuning on highly inferential tasks. We show that the performance improvement is likely attributed to the improved model CR ability. We also release a new dataset that focuses on CR in ALSC.
DISTO: Evaluating Textual Distractors for Multi-Choice Questions using Negative Sampling based Approach
Apr 10, 2023


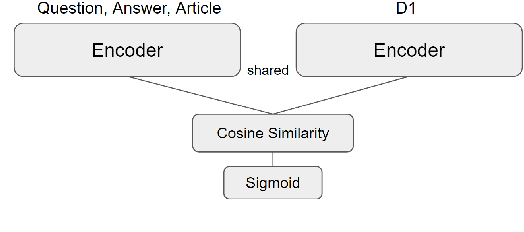
Multiple choice questions (MCQs) are an efficient and common way to assess reading comprehension (RC). Every MCQ needs a set of distractor answers that are incorrect, but plausible enough to test student knowledge. Distractor generation (DG) models have been proposed, and their performance is typically evaluated using machine translation (MT) metrics. However, MT metrics often misjudge the suitability of generated distractors. We propose DISTO: the first learned evaluation metric for generated distractors. We validate DISTO by showing its scores correlate highly with human ratings of distractor quality. At the same time, DISTO ranks the performance of state-of-the-art DG models very differently from MT-based metrics, showing that MT metrics should not be used for distractor evaluation.
Discriminative Models Can Still Outperform Generative Models in Aspect Based Sentiment Analysis
Jun 06, 2022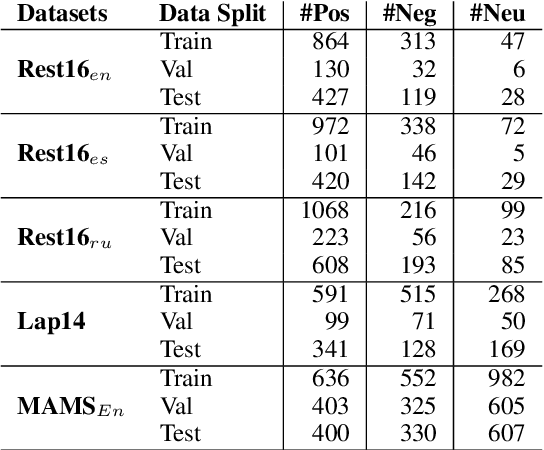
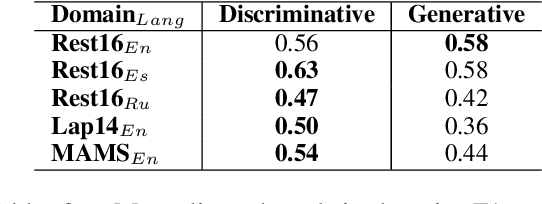
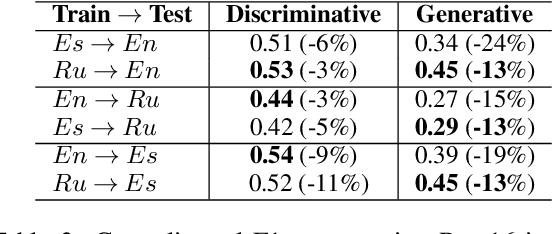
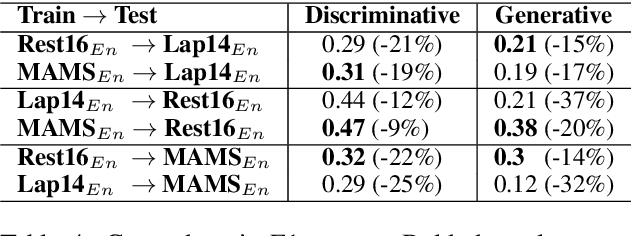
Aspect-based Sentiment Analysis (ABSA) helps to explain customers' opinions towards products and services. In the past, ABSA models were discriminative, but more recently generative models have been used to generate aspects and polarities directly from text. In contrast, discriminative models commonly first select aspects from the text, and then classify the aspect's polarity. Previous results showed that generative models outperform discriminative models on several English ABSA datasets. Here, we evaluate and contrast two state-of-the-art discriminative and generative models in several settings: cross-lingual, cross-domain, and cross-lingual and domain, to understand generalizability in settings other than English mono-lingual in-domain. Our more thorough evaluation shows that, contrary to previous studies, discriminative models can still outperform generative models in almost all settings.
Question Generation for Reading Comprehension Assessment by Modeling How and What to Ask
Apr 06, 2022



Reading is integral to everyday life, and yet learning to read is a struggle for many young learners. During lessons, teachers can use comprehension questions to increase engagement, test reading skills, and improve retention. Historically such questions were written by skilled teachers, but recently language models have been used to generate comprehension questions. However, many existing Question Generation (QG) systems focus on generating literal questions from the text, and have no way to control the type of the generated question. In this paper, we study QG for reading comprehension where inferential questions are critical and extractive techniques cannot be used. We propose a two-step model (HTA-WTA) that takes advantage of previous datasets, and can generate questions for a specific targeted comprehension skill. We propose a new reading comprehension dataset that contains questions annotated with story-based reading comprehension skills (SBRCS), allowing for a more complete reader assessment. Across several experiments, our results show that HTA-WTA outperforms multiple strong baselines on this new dataset. We show that the HTA-WTA model tests for strong SCRS by asking deep inferential questions.
Let-Mi: An Arabic Levantine Twitter Dataset for Misogynistic Language
Mar 18, 2021
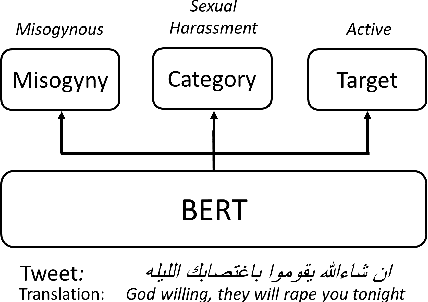
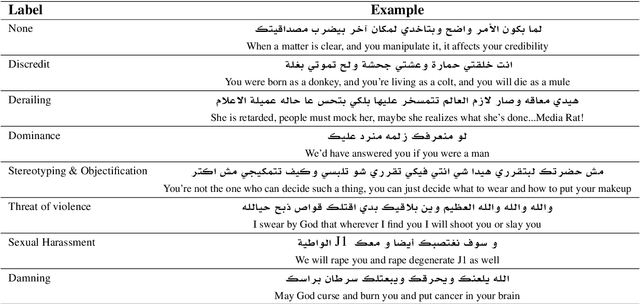
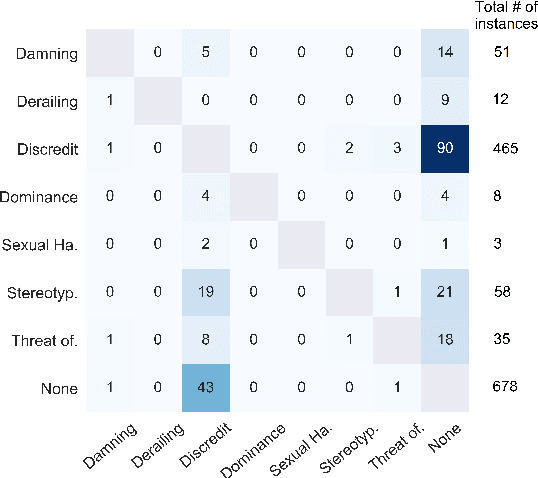
Online misogyny has become an increasing worry for Arab women who experience gender-based online abuse on a daily basis. Misogyny automatic detection systems can assist in the prohibition of anti-women Arabic toxic content. Developing such systems is hindered by the lack of the Arabic misogyny benchmark datasets. In this paper, we introduce an Arabic Levantine Twitter dataset for Misogynistic language (LeT-Mi) to be the first benchmark dataset for Arabic misogyny. We further provide a detailed review of the dataset creation and annotation phases. The consistency of the annotations for the proposed dataset was emphasized through inter-rater agreement evaluation measures. Moreover, Let-Mi was used as an evaluation dataset through binary/multi-/target classification tasks conducted by several state-of-the-art machine learning systems along with Multi-Task Learning (MTL) configuration. The obtained results indicated that the performances achieved by the used systems are consistent with state-of-the-art results for languages other than Arabic, while employing MTL improved the performance of the misogyny/target classification tasks.
FakeFlow: Fake News Detection by Modeling the Flow of Affective Information
Jan 24, 2021
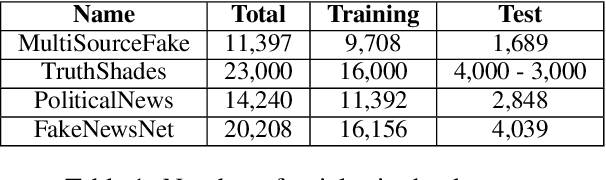


Fake news articles often stir the readers' attention by means of emotional appeals that arouse their feelings. Unlike in short news texts, authors of longer articles can exploit such affective factors to manipulate readers by adding exaggerations or fabricating events, in order to affect the readers' emotions. To capture this, we propose in this paper to model the flow of affective information in fake news articles using a neural architecture. The proposed model, FakeFlow, learns this flow by combining topic and affective information extracted from text. We evaluate the model's performance with several experiments on four real-world datasets. The results show that FakeFlow achieves superior results when compared against state-of-the-art methods, thus confirming the importance of capturing the flow of the affective information in news articles.
Irony Detection in a Multilingual Context
Feb 06, 2020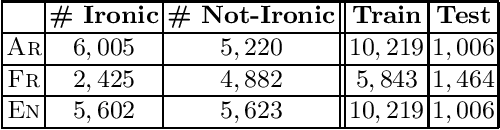

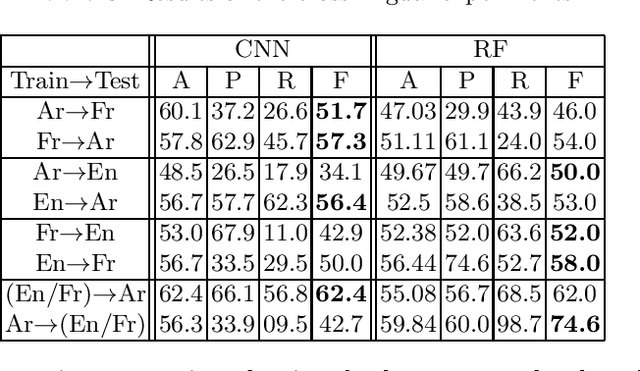
This paper proposes the first multilingual (French, English and Arabic) and multicultural (Indo-European languages vs. less culturally close languages) irony detection system. We employ both feature-based models and neural architectures using monolingual word representation. We compare the performance of these systems with state-of-the-art systems to identify their capabilities. We show that these monolingual models trained separately on different languages using multilingual word representation or text-based features can open the door to irony detection in languages that lack of annotated data for irony.
FacTweet: Profiling Fake News Twitter Accounts
Oct 15, 2019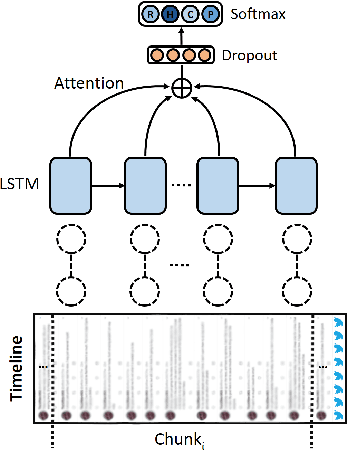
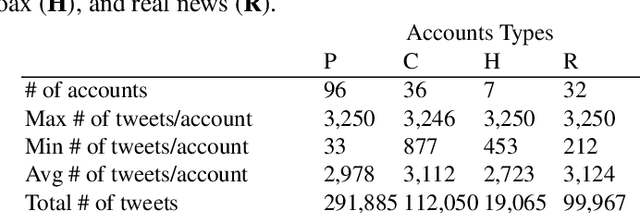
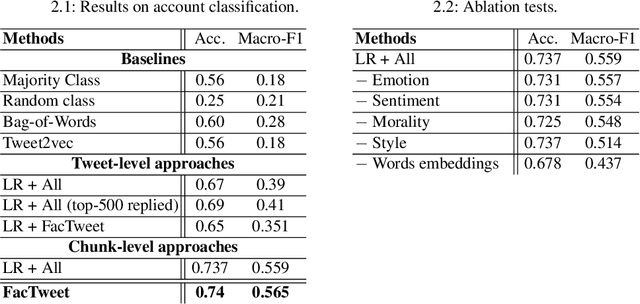
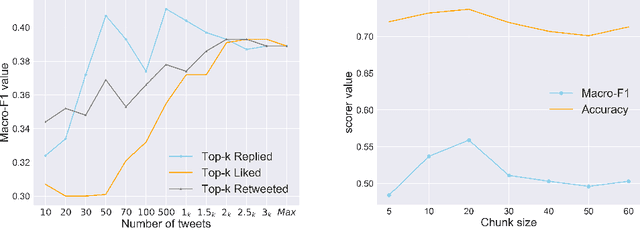
We present an approach to detect fake news in Twitter at the account level using a neural recurrent model and a variety of different semantic and stylistic features. Our method extracts a set of features from the timelines of news Twitter accounts by reading their posts as chunks, rather than dealing with each tweet independently. We show the experimental benefits of modeling latent stylistic signatures of mixed fake and real news with a sequential model over a wide range of strong baselines.
TexTrolls: Identifying Russian Trolls on Twitter from a Textual Perspective
Oct 03, 2019

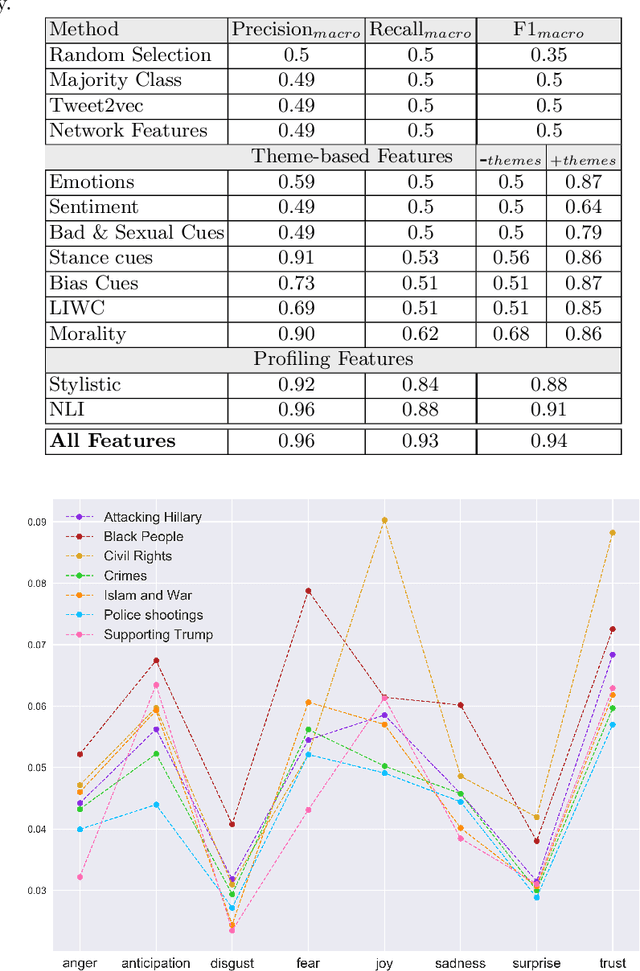
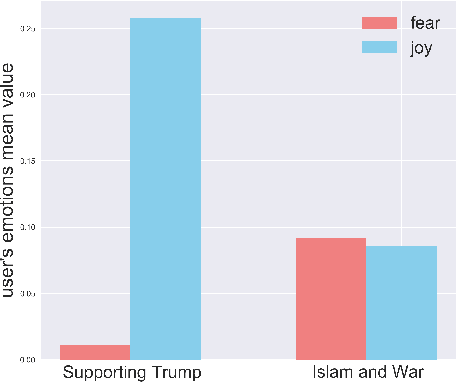
The online new emerging suspicious users, that usually are called trolls, are one of the main sources of hate, fake, and deceptive online messages. Some agendas are utilizing these harmful users to spread incitement tweets, and as a consequence, the audience get deceived. The challenge in detecting such accounts is that they conceal their identities which make them disguised in social media, adding more difficulty to identify them using just their social network information. Therefore, in this paper, we propose a text-based approach to detect the online trolls such as those that were discovered during the US 2016 presidential elections. Our approach is mainly based on textual features which utilize thematic information, and profiling features to identify the accounts from their way of writing tweets. We deduced the thematic information in a unsupervised way and we show that coupling them with the textual features enhanced the performance of the proposed model. In addition, we find that the proposed profiling features perform the best comparing to the textual features.
An Emotional Analysis of False Information in Social Media and News Articles
Aug 26, 2019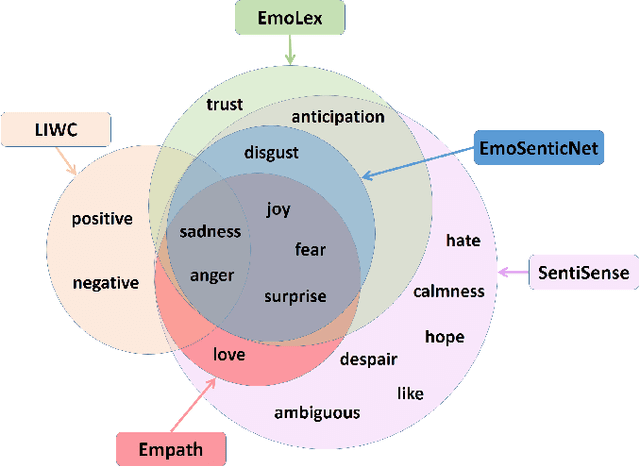
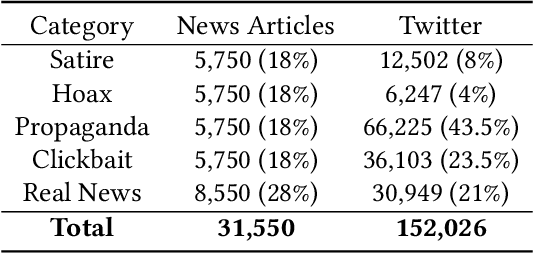
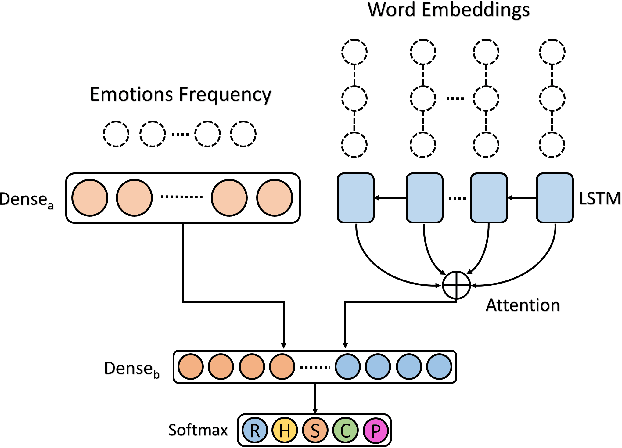
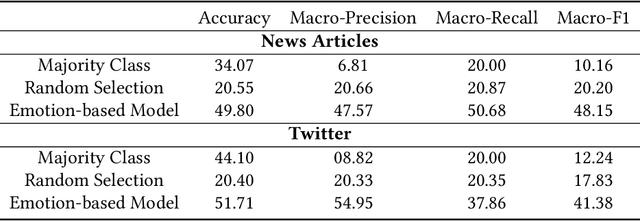
Fake news is risky since it has been created to manipulate the readers' opinions and beliefs. In this work, we compared the language of false news to the real one of real news from an emotional perspective, considering a set of false information types (propaganda, hoax, clickbait, and satire) from social media and online news articles sources. Our experiments showed that false information has different emotional patterns in each of its types, and emotions play a key role in deceiving the reader. Based on that, we proposed a LSTM neural network model that is emotionally-infused to detect false news.