 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Contrastive Learning for a Similarity-Guided Tampered Document Data Generation Pipeline
Feb 19, 2026Detecting tampered text in document images is a challenging task due to data scarcity. To address this, previous work has attempted to generate tampered documents using rule-based methods. However, the resulting documents often suffer from limited variety and poor visual quality, typically leaving highly visible artifacts that are rarely observed in real-world manipulations. This undermines the model's ability to learn robust, generalizable features and results in poor performance on real-world data. Motivated by this discrepancy, we propose a novel method for generating high-quality tampered document images. We first train an auxiliary network to compare text crops, leveraging contrastive learning with a novel strategy for defining positive pairs and their corresponding negatives. We also train a second auxiliary network to evaluate whether a crop tightly encloses the intended characters, without cutting off parts of characters or including parts of adjacent ones. Using a carefully designed generation pipeline that leverages both networks, we introduce a framework capable of producing diverse, high-quality tampered document images. We assess the effectiveness of our data generation pipeline by training multiple models on datasets derived from the same source images, generated using our method and existing approaches, under identical training protocols. Evaluating these models on various open-source datasets shows that our pipeline yields consistent performance improvements across architectures and datasets.
PACT: Pruning and Clustering-Based Token Reduction for Faster Visual Language Models
Apr 11, 2025Visual Language Models require substantial computational resources for inference due to the additional input tokens needed to represent visual information. However, these visual tokens often contain redundant and unimportant information, resulting in an unnecessarily high number of tokens. To address this, we introduce PACT, a method that reduces inference time and memory usage by pruning irrelevant tokens and merging visually redundant ones at an early layer of the language model. Our approach uses a novel importance metric to identify unimportant tokens without relying on attention scores, making it compatible with FlashAttention. We also propose a novel clustering algorithm, called Distance Bounded Density Peak Clustering, which efficiently clusters visual tokens while constraining the distances between elements within a cluster by a predefined threshold. We demonstrate the effectiveness of PACT through extensive experiments.
Rewiring Techniques to Mitigate Oversquashing and Oversmoothing in GNNs: A Survey
Nov 26, 2024


Graph Neural Networks (GNNs) are powerful tools for learning from graph-structured data, but their effectiveness is often constrained by two critical challenges: oversquashing, where the excessive compression of information from distant nodes results in significant information loss, and oversmoothing, where repeated message-passing iterations homogenize node representations, obscuring meaningful distinctions. These issues, intrinsically linked to the underlying graph structure, hinder information flow and constrain the expressiveness of GNNs. In this survey, we examine graph rewiring techniques, a class of methods designed to address these structural bottlenecks by modifying graph topology to enhance information diffusion. We provide a comprehensive review of state-of-the-art rewiring approaches, delving into their theoretical underpinnings, practical implementations, and performance trade-offs.
Triplètoile: Extraction of Knowledge from Microblogging Text
Aug 27, 2024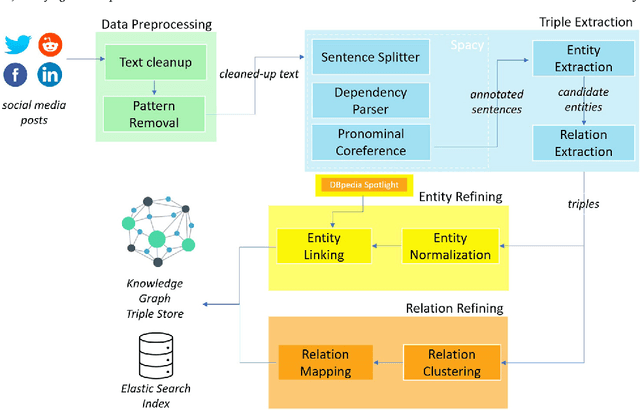



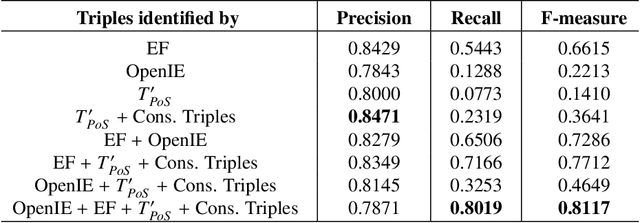
Numerous methods and pipelines have recently emerged for the automatic extraction of knowledge graphs from documents such as scientific publications and patents. However, adapting these methods to incorporate alternative text sources like micro-blogging posts and news has proven challenging as they struggle to model open-domain entities and relations, typically found in these sources. In this paper, we propose an enhanced information extraction pipeline tailored to the extraction of a knowledge graph comprising open-domain entities from micro-blogging posts on social media platforms. Our pipeline leverages dependency parsing and classifies entity relations in an unsupervised manner through hierarchical clustering over word embeddings. We provide a use case on extracting semantic triples from a corpus of 100 thousand tweets about digital transformation and publicly release the generated knowledge graph. On the same dataset, we conduct two experimental evaluations, showing that the system produces triples with precision over 95% and outperforms similar pipelines of around 5% in terms of precision, while generating a comparatively higher number of triples.
* 42 pages, 6 figures
An Ensemble Method Based on the Combination of Transformers with Convolutional Neural Networks to Detect Artificially Generated Text
Oct 26, 2023Thanks to the state-of-the-art Large Language Models (LLMs), language generation has reached outstanding levels. These models are capable of generating high quality content, thus making it a challenging task to detect generated text from human-written content. Despite the advantages provided by Natural Language Generation, the inability to distinguish automatically generated text can raise ethical concerns in terms of authenticity. Consequently, it is important to design and develop methodologies to detect artificial content. In our work, we present some classification models constructed by ensembling transformer models such as Sci-BERT, DeBERTa and XLNet, with Convolutional Neural Networks (CNNs). Our experiments demonstrate that the considered ensemble architectures surpass the performance of the individual transformer models for classification. Furthermore, the proposed SciBERT-CNN ensemble model produced an F1-score of 98.36% on the ALTA shared task 2023 data.
Word Sense Induction with Hierarchical Clustering and Mutual Information Maximization
Oct 11, 2022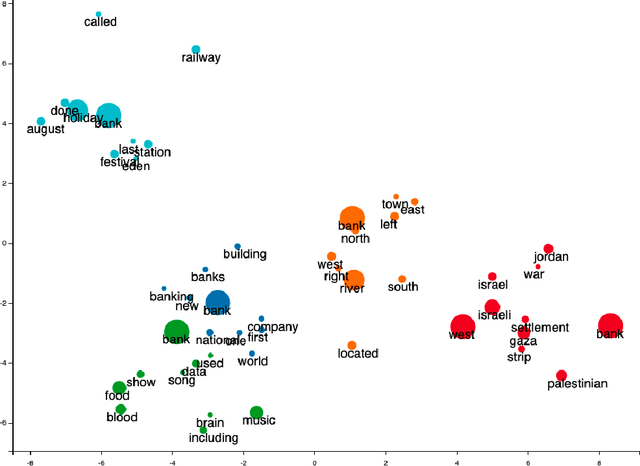
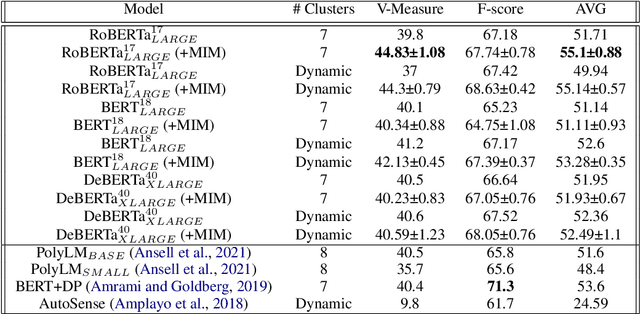
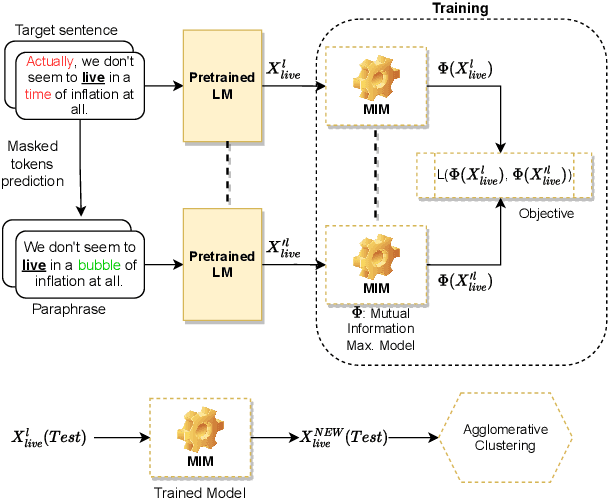
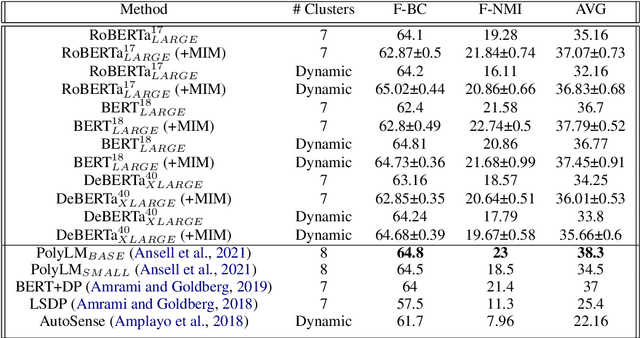
Word sense induction (WSI) is a difficult problem in natural language processing that involves the unsupervised automatic detection of a word's senses (i.e. meanings). Recent work achieves significant results on the WSI task by pre-training a language model that can exclusively disambiguate word senses, whereas others employ previously pre-trained language models in conjunction with additional strategies to induce senses. In this paper, we propose a novel unsupervised method based on hierarchical clustering and invariant information clustering (IIC). The IIC is used to train a small model to optimize the mutual information between two vector representations of a target word occurring in a pair of synthetic paraphrases. This model is later used in inference mode to extract a higher quality vector representation to be used in the hierarchical clustering. We evaluate our method on two WSI tasks and in two distinct clustering configurations (fixed and dynamic number of clusters). We empirically demonstrate that, in certain cases, our approach outperforms prior WSI state-of-the-art methods, while in others, it achieves a competitive performance.
A Benchmark Corpus for the Detection of Automatically Generated Text in Academic Publications
Feb 04, 2022



Automatic text generation based on neural language models has achieved performance levels that make the generated text almost indistinguishable from those written by humans. Despite the value that text generation can have in various applications, it can also be employed for malicious tasks. The diffusion of such practices represent a threat to the quality of academic publishing. To address these problems, we propose in this paper two datasets comprised of artificially generated research content: a completely synthetic dataset and a partial text substitution dataset. In the first case, the content is completely generated by the GPT-2 model after a short prompt extracted from original papers. The partial or hybrid dataset is created by replacing several sentences of abstracts with sentences that are generated by the Arxiv-NLP model. We evaluate the quality of the datasets comparing the generated texts to aligned original texts using fluency metrics such as BLEU and ROUGE. The more natural the artificial texts seem, the more difficult they are to detect and the better is the benchmark. We also evaluate the difficulty of the task of distinguishing original from generated text by using state-of-the-art classification models.
Generating Knowledge Graphs by Employing Natural Language Processing and Machine Learning Techniques within the Scholarly Domain
Oct 28, 2020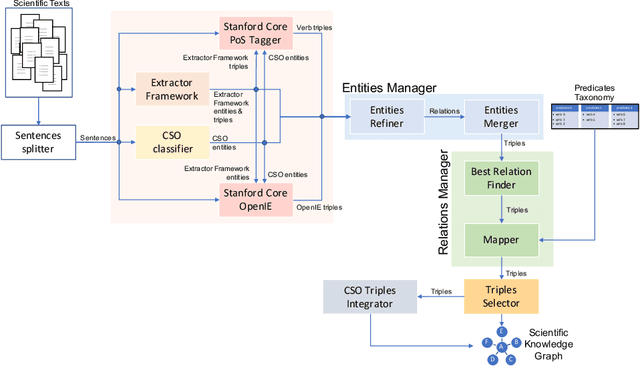
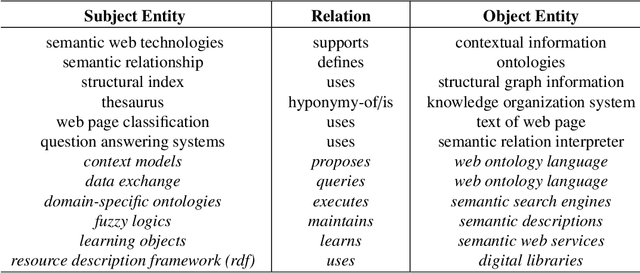
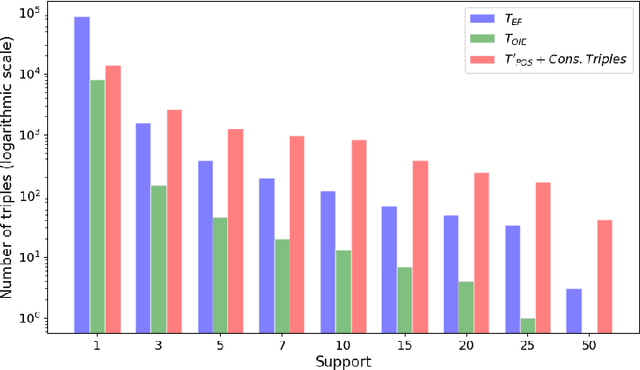
The continuous growth of scientific literature brings innovations and, at the same time, raises new challenges. One of them is related to the fact that its analysis has become difficult due to the high volume of published papers for which manual effort for annotations and management is required. Novel technological infrastructures are needed to help researchers, research policy makers, and companies to time-efficiently browse, analyse, and forecast scientific research. Knowledge graphs i.e., large networks of entities and relationships, have proved to be effective solution in this space. Scientific knowledge graphs focus on the scholarly domain and typically contain metadata describing research publications such as authors, venues, organizations, research topics, and citations. However, the current generation of knowledge graphs lacks of an explicit representation of the knowledge presented in the research papers. As such, in this paper, we present a new architecture that takes advantage of Natural Language Processing and Machine Learning methods for extracting entities and relationships from research publications and integrates them in a large-scale knowledge graph. Within this research work, we i) tackle the challenge of knowledge extraction by employing several state-of-the-art Natural Language Processing and Text Mining tools, ii) describe an approach for integrating entities and relationships generated by these tools, iii) show the advantage of such an hybrid system over alternative approaches, and vi) as a chosen use case, we generated a scientific knowledge graph including 109,105 triples, extracted from 26,827 abstracts of papers within the Semantic Web domain. As our approach is general and can be applied to any domain, we expect that it can facilitate the management, analysis, dissemination, and processing of scientific knowledge.
TexTrolls: Identifying Russian Trolls on Twitter from a Textual Perspective
Oct 03, 2019

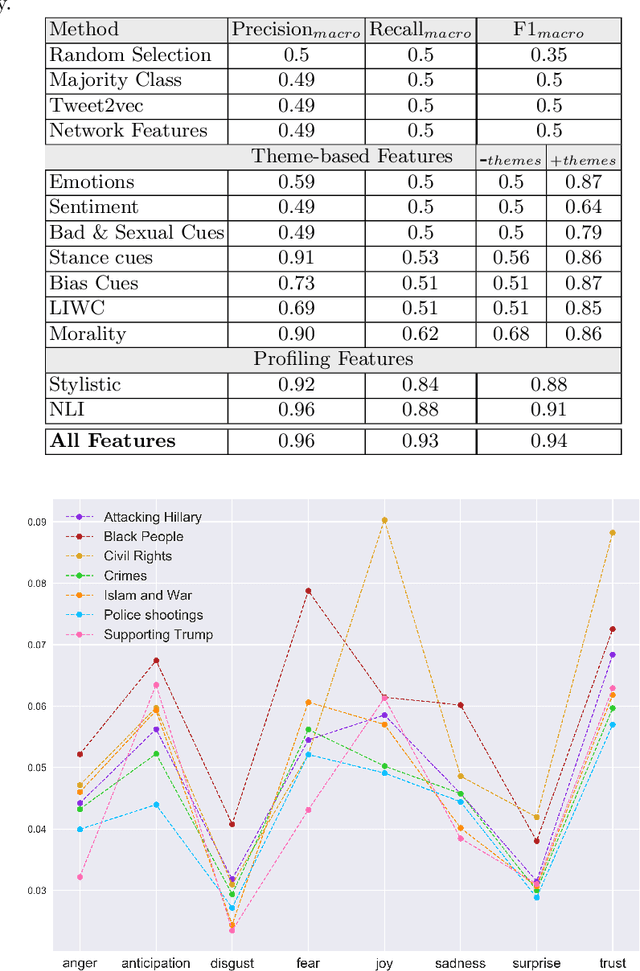
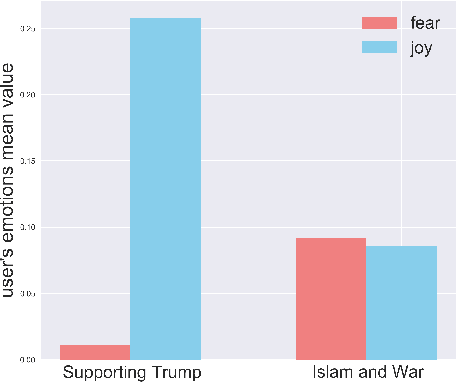
The online new emerging suspicious users, that usually are called trolls, are one of the main sources of hate, fake, and deceptive online messages. Some agendas are utilizing these harmful users to spread incitement tweets, and as a consequence, the audience get deceived. The challenge in detecting such accounts is that they conceal their identities which make them disguised in social media, adding more difficulty to identify them using just their social network information. Therefore, in this paper, we propose a text-based approach to detect the online trolls such as those that were discovered during the US 2016 presidential elections. Our approach is mainly based on textual features which utilize thematic information, and profiling features to identify the accounts from their way of writing tweets. We deduced the thematic information in a unsupervised way and we show that coupling them with the textual features enhanced the performance of the proposed model. In addition, we find that the proposed profiling features perform the best comparing to the textual features.