 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriplètoile: Extraction of Knowledge from Microblogging Text
Aug 27, 2024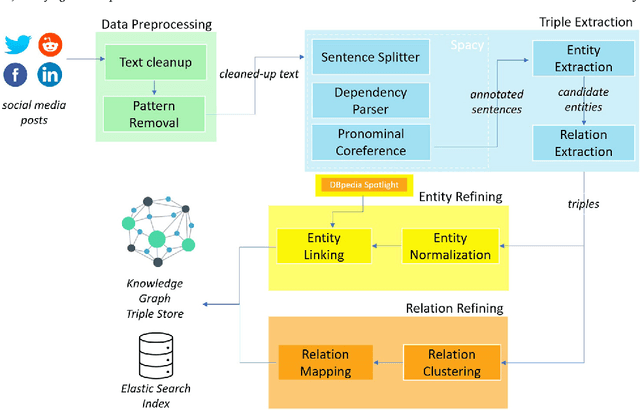



Numerous methods and pipelines have recently emerged for the automatic extraction of knowledge graphs from documents such as scientific publications and patents. However, adapting these methods to incorporate alternative text sources like micro-blogging posts and news has proven challenging as they struggle to model open-domain entities and relations, typically found in these sources. In this paper, we propose an enhanced information extraction pipeline tailored to the extraction of a knowledge graph comprising open-domain entities from micro-blogging posts on social media platforms. Our pipeline leverages dependency parsing and classifies entity relations in an unsupervised manner through hierarchical clustering over word embeddings. We provide a use case on extracting semantic triples from a corpus of 100 thousand tweets about digital transformation and publicly release the generated knowledge graph. On the same dataset, we conduct two experimental evaluations, showing that the system produces triples with precision over 95% and outperforms similar pipelines of around 5% in terms of precision, while generating a comparatively higher number of triples.
* 42 pages, 6 figures
Trans4E: Link Prediction on Scholarly Knowledge Graphs
Jul 03, 2021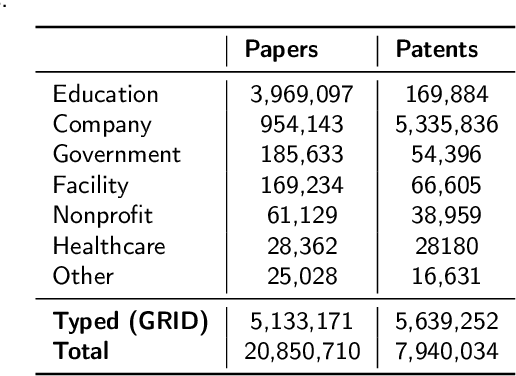
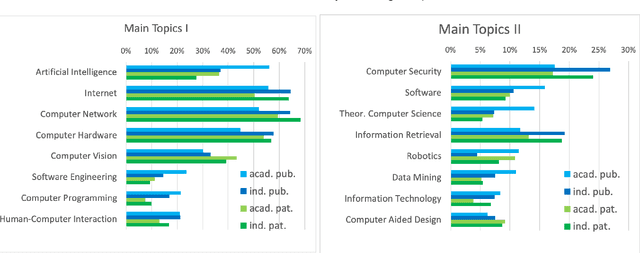
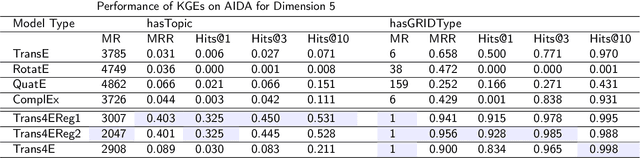
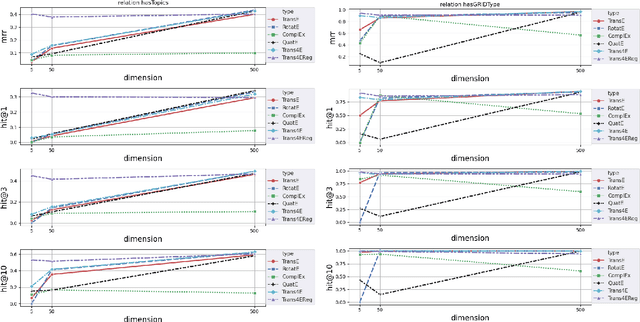
The incompleteness of Knowledge Graphs (KGs) is a crucial issue affecting the quality of AI-based services. In the scholarly domain, KGs describing research publications typically lack important information, hindering our ability to analyse and predict research dynamics. In recent years, link prediction approaches based on Knowledge Graph Embedding models became the first aid for this issue. In this work, we present Trans4E, a novel embedding model that is particularly fit for KGs which include N to M relations with N$\gg$M. This is typical for KGs that categorize a large number of entities (e.g., research articles, patents, persons) according to a relatively small set of categories. Trans4E was applied on two large-scale knowledge graphs, the Academia/Industry DynAmics (AIDA) and Microsoft Academic Graph (MAG), for completing the information about Fields of Study (e.g., 'neural networks', 'machine learning', 'artificial intelligence'), and affiliation types (e.g., 'education', 'company', 'government'), improving the scope and accuracy of the resulting data. We evaluated our approach against alternative solutions on AIDA, MAG, and four other benchmarks (FB15k, FB15k-237, WN18, and WN18RR). Trans4E outperforms the other models when using low embedding dimensions and obtains competitive results in high dimensions.