 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Task Adaptation Techniques of Large Language Models for Identifying Sustainable Development Goals
Jun 18, 2025In 2012, the United Nations introduced 17 Sustainable Development Goals (SDGs) aimed at creating a more sustainable and improved future by 2030. However, tracking progress toward these goals is difficult because of the extensive scale and complexity of the data involved. Text classification models have become vital tools in this area, automating the analysis of vast amounts of text from a variety of sources. Additionally, large language models (LLMs) have recently proven indispensable for many natural language processing tasks, including text classification, thanks to their ability to recognize complex linguistic patterns and semantics. This study analyzes various proprietary and open-source LLMs for a single-label, multi-class text classification task focused on the SDGs. Then, it also evaluates the effectiveness of task adaptation techniques (i.e., in-context learning approaches), namely Zero-Shot and Few-Shot Learning, as well as Fine-Tuning within this domain. The results reveal that smaller models, when optimized through prompt engineering, can perform on par with larger models like OpenAI's GPT (Generative Pre-trained Transformer).
Large Language Models for Scholarly Ontology Generation: An Extensive Analysis in the Engineering Field
Dec 11, 2024Ontologies of research topics are crucial for structuring scientific knowledge, enabling scientists to navigate vast amounts of research, and forming the backbone of intelligent systems such as search engines and recommendation systems. However, manual creation of these ontologies is expensive, slow, and often results in outdated and overly general representations. As a solution, researchers have been investigating ways to automate or semi-automate the process of generating these ontologies. This paper offers a comprehensive analysis of the ability of large language models (LLMs) to identify semantic relationships between different research topics, which is a critical step in the development of such ontologies. To this end, we developed a gold standard based on the IEEE Thesaurus to evaluate the task of identifying four types of relationships between pairs of topics: broader, narrower, same-as, and other. Our study evaluates the performance of seventeen LLMs, which differ in scale, accessibility (open vs. proprietary), and model type (full vs. quantised), while also assessing four zero-shot reasoning strategies. Several models have achieved outstanding results, including Mixtral-8x7B, Dolphin-Mistral-7B, and Claude 3 Sonnet, with F1-scores of 0.847, 0.920, and 0.967, respectively. Furthermore, our findings demonstrate that smaller, quantised models, when optimised through prompt engineering, can deliver performance comparable to much larger proprietary models, while requiring significantly fewer computational resources.
A Survey on Knowledge Organization Systems of Research Fields: Resources and Challenges
Sep 06, 2024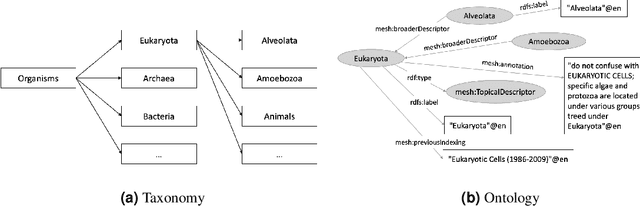
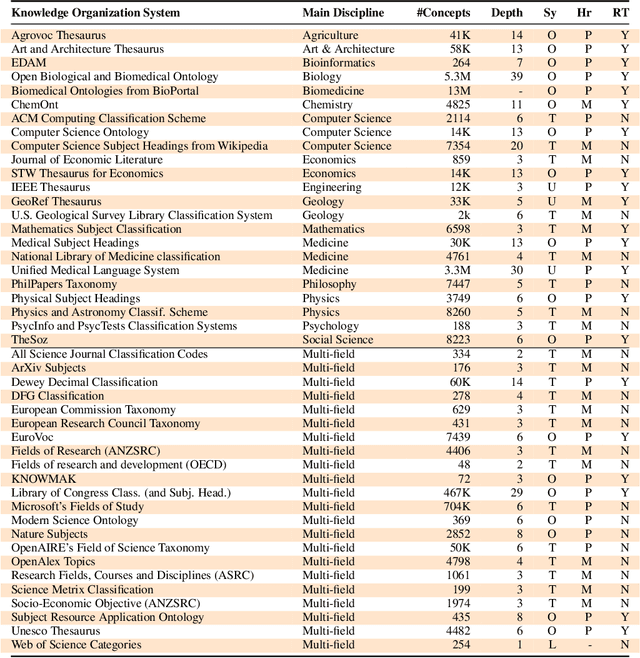
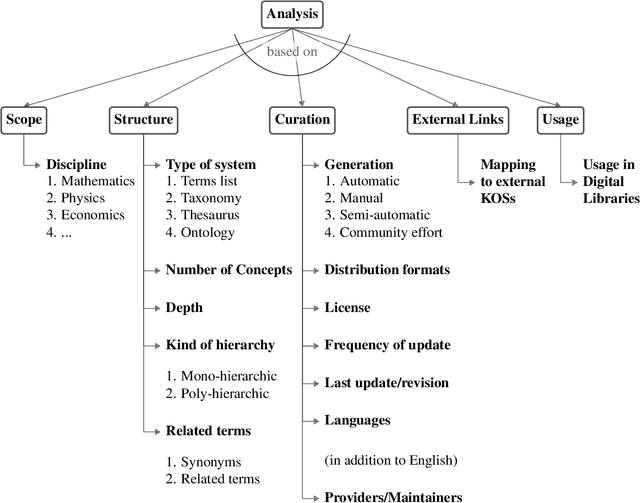
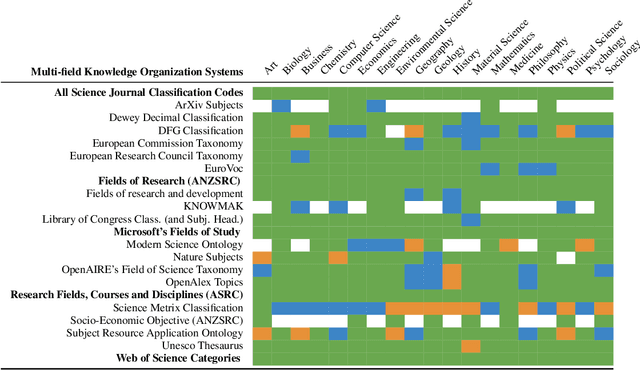
Knowledge Organization Systems (KOSs), such as term lists, thesauri, taxonomies, and ontologies, play a fundamental role in categorising, managing, and retrieving information. In the academic domain, KOSs are often adopted for representing research areas and their relationships, primarily aiming to classify research articles, academic courses, patents, books, scientific venues, domain experts, grants, software, experiment materials, and several other relevant products and agents. These structured representations of research areas, widely embraced by many academic fields, have proven effective in empowering AI-based systems to i) enhance retrievability of relevant documents, ii) enable advanced analytic solutions to quantify the impact of academic research, and iii) analyse and forecast research dynamics. This paper aims to present a comprehensive survey of the current KOS for academic disciplines. We analysed and compared 45 KOSs according to five main dimensions: scope, structure, curation, usage, and links to other KOSs. Our results reveal a very heterogeneous scenario in terms of scope, scale, quality, and usage, highlighting the need for more integrated solutions for representing research knowledge across academic fields. We conclude by discussing the main challenges and the most promising future directions.
Artificial Intelligence for Literature Reviews: Opportunities and Challenges
Feb 13, 2024



This manuscript presents a comprehensive review of the use of Artificial Intelligence (AI) in Systematic Literature Reviews (SLRs). A SLR is a rigorous and organised methodology that assesses and integrates previous research on a given topic. Numerous tools have been developed to assist and partially automate the SLR process. The increasing role of AI in this field shows great potential in providing more effective support for researchers, moving towards the semi-automatic creation of literature reviews. Our study focuses on how AI techniques are applied in the semi-automation of SLRs, specifically in the screening and extraction phases. We examine 21 leading SLR tools using a framework that combines 23 traditional features with 11 AI features. We also analyse 11 recent tools that leverage large language models for searching the literature and assisting academic writing. Finally, the paper discusses current trends in the field, outlines key research challenges, and suggests directions for future research.
Trans4E: Link Prediction on Scholarly Knowledge Graphs
Jul 03, 2021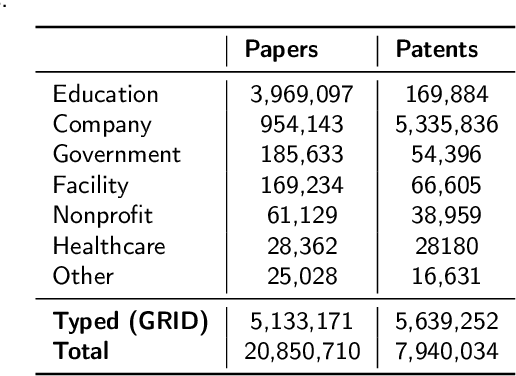
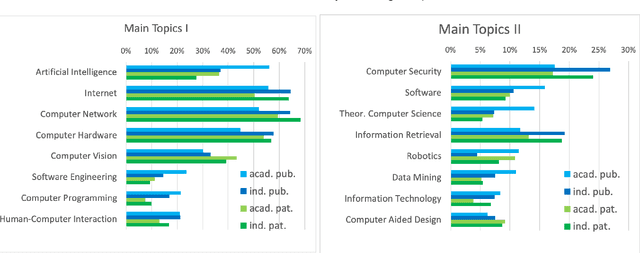
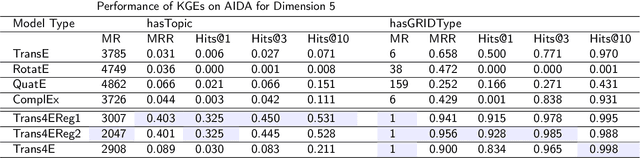
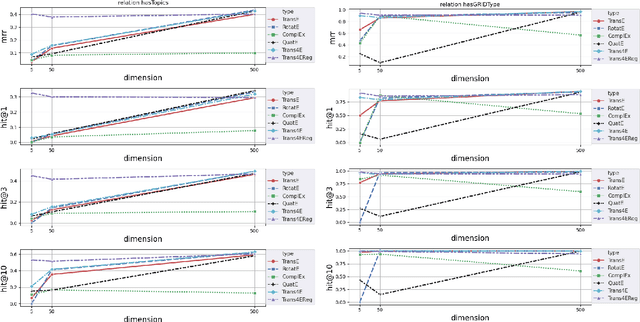
The incompleteness of Knowledge Graphs (KGs) is a crucial issue affecting the quality of AI-based services. In the scholarly domain, KGs describing research publications typically lack important information, hindering our ability to analyse and predict research dynamics. In recent years, link prediction approaches based on Knowledge Graph Embedding models became the first aid for this issue. In this work, we present Trans4E, a novel embedding model that is particularly fit for KGs which include N to M relations with N$\gg$M. This is typical for KGs that categorize a large number of entities (e.g., research articles, patents, persons) according to a relatively small set of categories. Trans4E was applied on two large-scale knowledge graphs, the Academia/Industry DynAmics (AIDA) and Microsoft Academic Graph (MAG), for completing the information about Fields of Study (e.g., 'neural networks', 'machine learning', 'artificial intelligence'), and affiliation types (e.g., 'education', 'company', 'government'), improving the scope and accuracy of the resulting data. We evaluated our approach against alternative solutions on AIDA, MAG, and four other benchmarks (FB15k, FB15k-237, WN18, and WN18RR). Trans4E outperforms the other models when using low embedding dimensions and obtains competitive results in high dimensions.
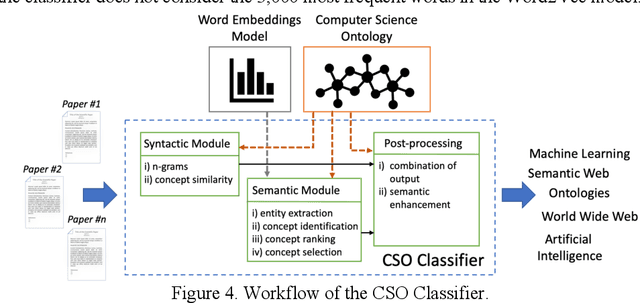
The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles
Apr 02, 2021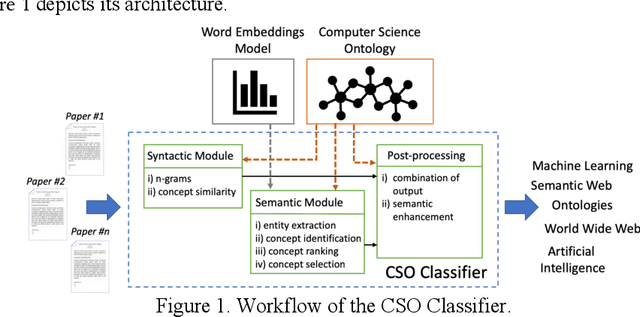
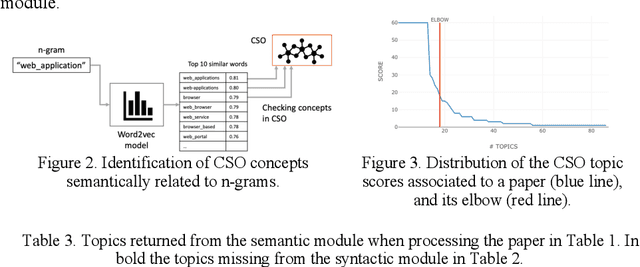
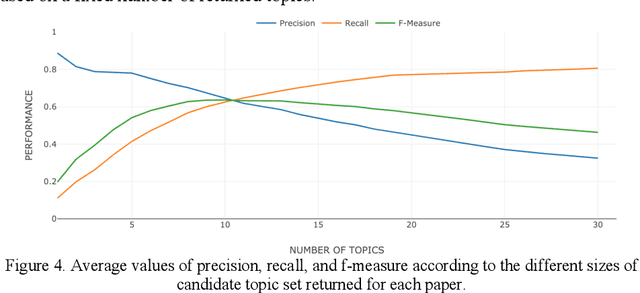
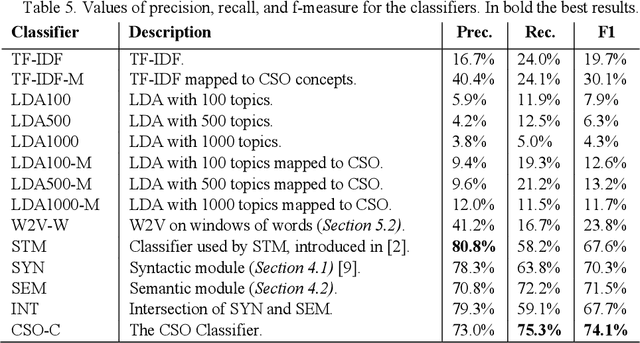
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this paper, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of re-search areas in the field of Computer Science. The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. The approach was evaluated on a gold standard of manually annotated articles yielding a significant improvement over alternative methods.
* Conference paper at TPDL 2019
Commonsense Spatial Reasoning for Visually Intelligent Agents
Apr 01, 2021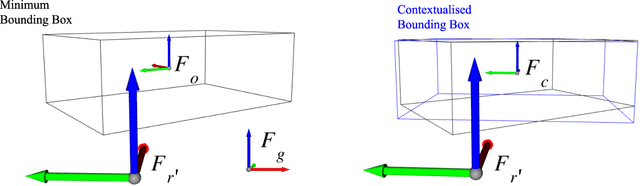
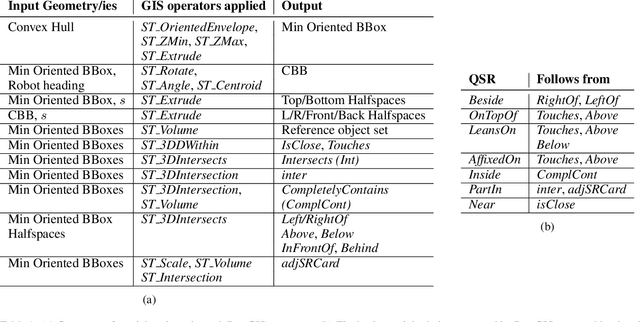
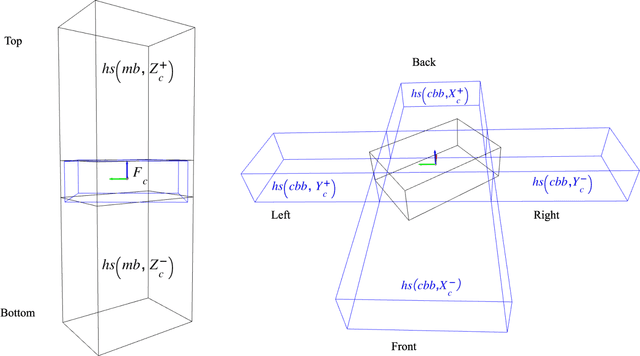
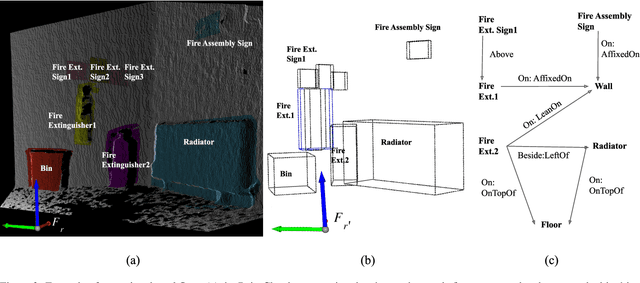
Service robots are expected to reliably make sense of complex, fast-changing environments. From a cognitive standpoint, they need the appropriate reasoning capabilities and background knowledge required to exhibit human-like Visual Intelligence. In particular, our prior work has shown that the ability to reason about spatial relations between objects in the world is a key requirement for the development of Visually Intelligent Agents. In this paper, we present a framework for commonsense spatial reasoning which is tailored to real-world robotic applications. Differently from prior approaches to qualitative spatial reasoning, the proposed framework is robust to variations in the robot's viewpoint and object orientation. The spatial relations in the proposed framework are also mapped to the types of commonsense predicates used to describe typical object configurations in English. In addition, we also show how this formally-defined framework can be implemented in a concrete spatial database.
Improving Editorial Workflow and Metadata Quality at Springer Nature
Mar 24, 2021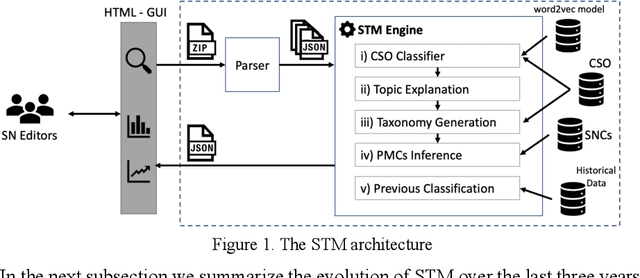

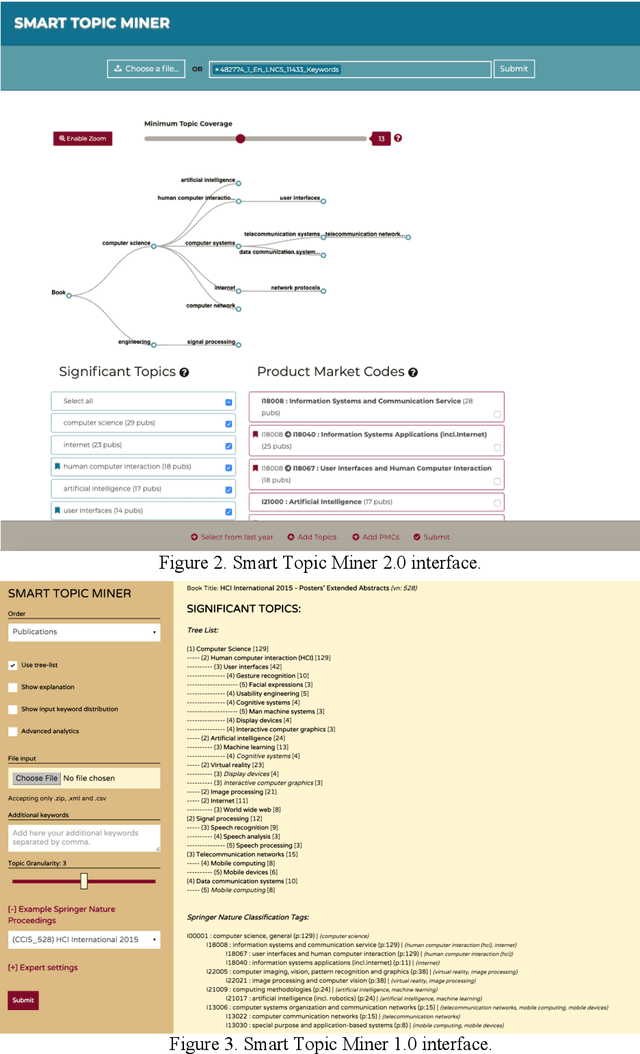
Identifying the research topics that best describe the scope of a scientific publication is a crucial task for editors, in particular because the quality of these annotations determine how effectively users are able to discover the right content in online libraries. For this reason, Springer Nature, the world's largest academic book publisher, has traditionally entrusted this task to their most expert editors. These editors manually analyse all new books, possibly including hundreds of chapters, and produce a list of the most relevant topics. Hence, this process has traditionally been very expensive, time-consuming, and confined to a few senior editors. For these reasons, back in 2016 we developed Smart Topic Miner (STM), an ontology-driven application that assists the Springer Nature editorial team in annotating the volumes of all books covering conference proceedings in Computer Science. Since then STM has been regularly used by editors in Germany, China, Brazil, India, and Japan, for a total of about 800 volumes per year. Over the past three years the initial prototype has iteratively evolved in response to feedback from the users and evolving requirements. In this paper we present the most recent version of the tool and describe the evolution of the system over the years, the key lessons learnt, and the impact on the Springer Nature workflow. In particular, our solution has drastically reduced the time needed to annotate proceedings and significantly improved their discoverability, resulting in 9.3 million additional downloads. We also present a user study involving 9 editors, which yielded excellent results in term of usability, and report an evaluation of the new topic classifier used by STM, which outperforms previous versions in recall and F-measure.
Ontology-Based Recommendation of Editorial Products
Mar 24, 2021
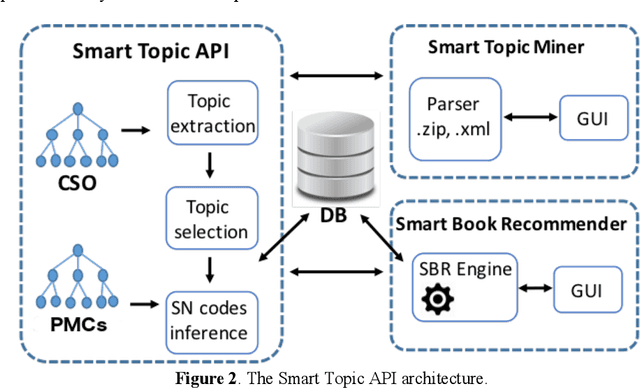

Major academic publishers need to be able to analyse their vast catalogue of products and select the best items to be marketed in scientific venues. This is a complex exercise that requires characterising with a high precision the topics of thousands of books and matching them with the interests of the relevant communities. In Springer Nature, this task has been traditionally handled manually by publishing editors. However, the rapid growth in the number of scientific publications and the dynamic nature of the Computer Science landscape has made this solution increasingly inefficient. We have addressed this issue by creating Smart Book Recommender (SBR), an ontology-based recommender system developed by The Open University (OU) in collaboration with Springer Nature, which supports their Computer Science editorial team in selecting the products to market at specific venues. SBR recommends books, journals, and conference proceedings relevant to a conference by taking advantage of a semantically enhanced representation of about 27K editorial products. This is based on the Computer Science Ontology, a very large-scale, automatically generated taxonomy of research areas. SBR also allows users to investigate why a certain publication was suggested by the system. It does so by means of an interactive graph view that displays the topic taxonomy of the recommended editorial product and compares it with the topic-centric characterization of the input conference. An evaluation carried out with seven Springer Nature editors and seven OU researchers has confirmed the effectiveness of the solution.
Generating Knowledge Graphs by Employing Natural Language Processing and Machine Learning Techniques within the Scholarly Domain
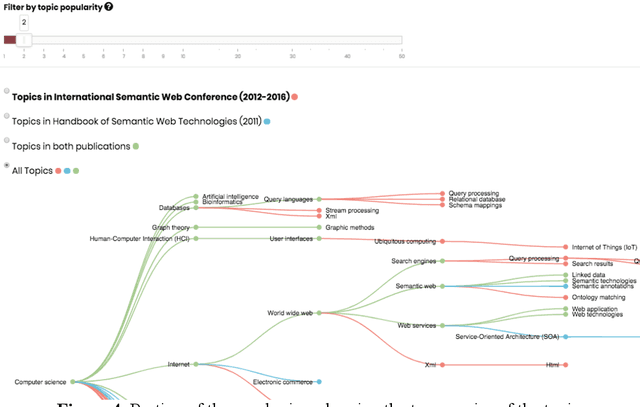
Oct 28, 2020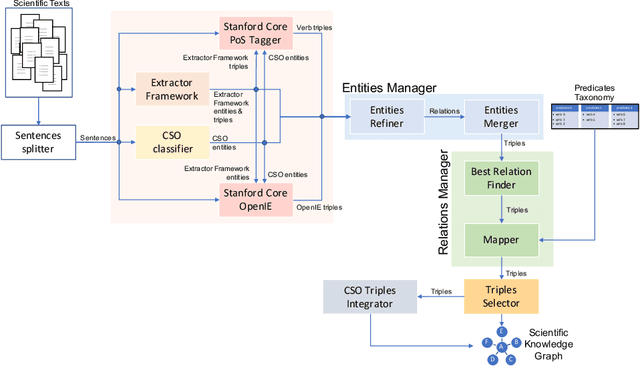
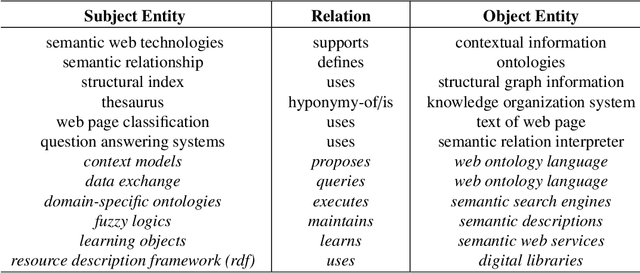
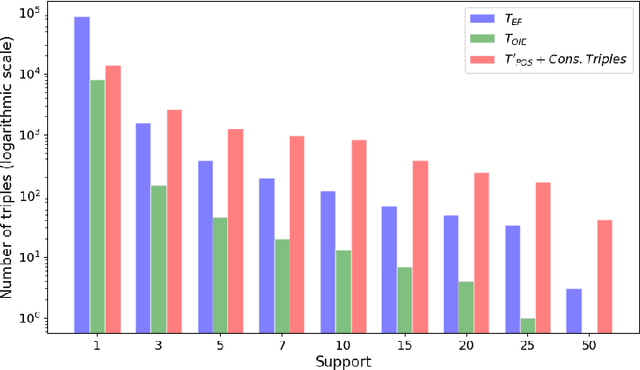
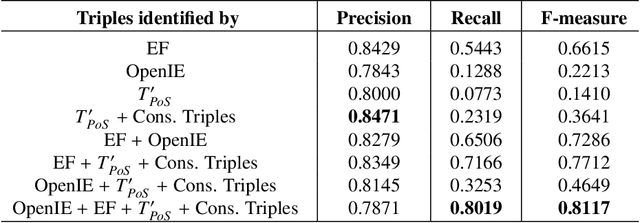
The continuous growth of scientific literature brings innovations and, at the same time, raises new challenges. One of them is related to the fact that its analysis has become difficult due to the high volume of published papers for which manual effort for annotations and management is required. Novel technological infrastructures are needed to help researchers, research policy makers, and companies to time-efficiently browse, analyse, and forecast scientific research. Knowledge graphs i.e., large networks of entities and relationships, have proved to be effective solution in this space. Scientific knowledge graphs focus on the scholarly domain and typically contain metadata describing research publications such as authors, venues, organizations, research topics, and citations. However, the current generation of knowledge graphs lacks of an explicit representation of the knowledge presented in the research papers. As such, in this paper, we present a new architecture that takes advantage of Natural Language Processing and Machine Learning methods for extracting entities and relationships from research publications and integrates them in a large-scale knowledge graph. Within this research work, we i) tackle the challenge of knowledge extraction by employing several state-of-the-art Natural Language Processing and Text Mining tools, ii) describe an approach for integrating entities and relationships generated by these tools, iii) show the advantage of such an hybrid system over alternative approaches, and vi) as a chosen use case, we generated a scientific knowledge graph including 109,105 triples, extracted from 26,827 abstracts of papers within the Semantic Web domain. As our approach is general and can be applied to any domain, we expect that it can facilitate the management, analysis, dissemination, and processing of scientific knowledge.