 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Models for Knowledge Graph Generation
Feb 06, 2026Knowledge Graph (KG) generation requires models to learn complex semantic dependencies between triples while maintaining domain validity constraints. Unlike link prediction, which scores triples independently, generative models must capture interdependencies across entire subgraphs to produce semantically coherent structures. We present ARK (Auto-Regressive Knowledge Graph Generation), a family of autoregressive models that generate KGs by treating graphs as sequences of (head, relation, tail) triples. ARK learns implicit semantic constraints directly from data, including type consistency, temporal validity, and relational patterns, without explicit rule supervision. On the IntelliGraphs benchmark, our models achieve 89.2% to 100.0% semantic validity across diverse datasets while generating novel graphs not seen during training. We also introduce SAIL, a variational extension of ARK that enables controlled generation through learned latent representations, supporting both unconditional sampling and conditional completion from partial graphs. Our analysis reveals that model capacity (hidden dimensionality >= 64) is more critical than architectural depth for KG generation, with recurrent architectures achieving comparable validity to transformer-based alternatives while offering substantial computational efficiency. These results demonstrate that autoregressive models provide an effective framework for KG generation, with practical applications in knowledge base completion and query answering.
GRAPES: Learning to Sample Graphs for Scalable Graph Neural Networks
Oct 05, 2023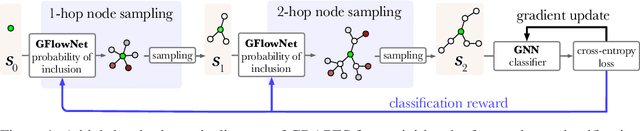
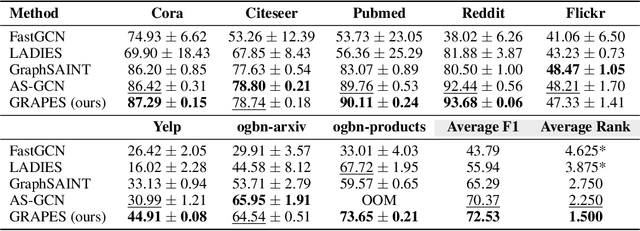
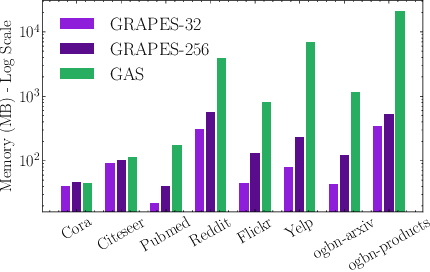
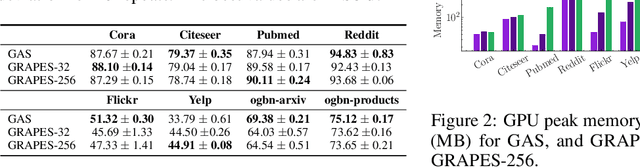
Graph neural networks (GNNs) learn the representation of nodes in a graph by aggregating the neighborhood information in various ways. As these networks grow in depth, their receptive field grows exponentially due to the increase in neighborhood sizes, resulting in high memory costs. Graph sampling solves memory issues in GNNs by sampling a small ratio of the nodes in the graph. This way, GNNs can scale to much larger graphs. Most sampling methods focus on fixed sampling heuristics, which may not generalize to different structures or tasks. We introduce GRAPES, an adaptive graph sampling method that learns to identify sets of influential nodes for training a GNN classifier. GRAPES uses a GFlowNet to learn node sampling probabilities given the classification objectives. We evaluate GRAPES across several small- and large-scale graph benchmarks and demonstrate its effectiveness in accuracy and scalability. In contrast to existing sampling methods, GRAPES maintains high accuracy even with small sample sizes and, therefore, can scale to very large graphs. Our code is publicly available at https://github.com/dfdazac/grapes.
IntelliGraphs: Datasets for Benchmarking Knowledge Graph Generation
Jul 19, 2023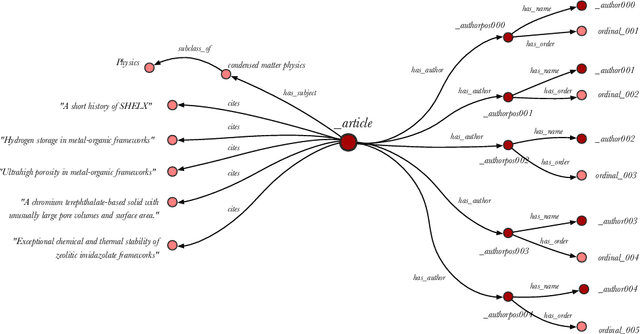
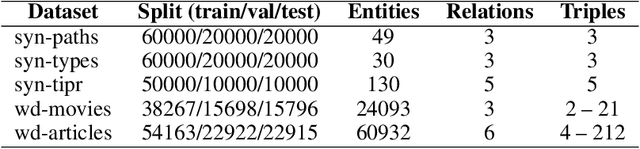
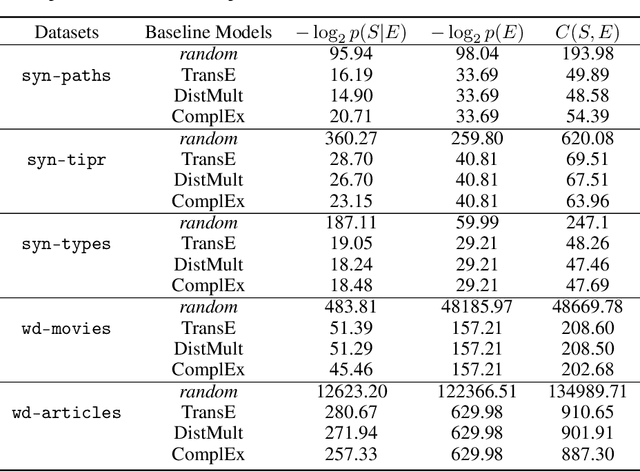
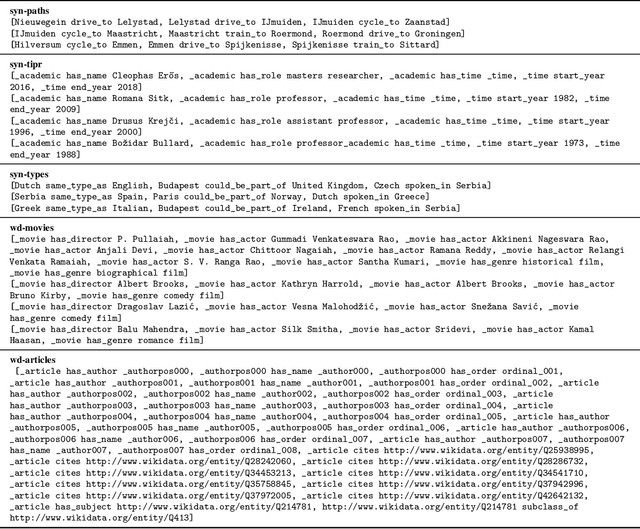
Knowledge Graph Embedding (KGE) models are used to learn continuous representations of entities and relations. A key task in the literature is predicting missing links between entities. However, Knowledge Graphs are not just sets of links but also have semantics underlying their structure. Semantics is crucial in several downstream tasks, such as query answering or reasoning. We introduce the subgraph inference task, where a model has to generate likely and semantically valid subgraphs. We propose IntelliGraphs, a set of five new Knowledge Graph datasets. The IntelliGraphs datasets contain subgraphs with semantics expressed in logical rules for evaluating subgraph inference. We also present the dataset generator that produced the synthetic datasets. We designed four novel baseline models, which include three models based on traditional KGEs. We evaluate their expressiveness and show that these models cannot capture the semantics. We believe this benchmark will encourage the development of machine learning models that emphasize semantic understanding.
A-NeSI: A Scalable Approximate Method for Probabilistic Neurosymbolic Inference
Dec 23, 2022



We study the problem of combining neural networks with symbolic reasoning. Recently introduced frameworks for Probabilistic Neurosymbolic Learning (PNL), such as DeepProbLog, perform exponential-time exact inference, limiting the scalability of PNL solutions. We introduce Approximate Neurosymbolic Inference (A-NeSI): a new framework for PNL that uses neural networks for scalable approximate inference. A-NeSI 1) performs approximate inference in polynomial time without changing the semantics of probabilistic logics; 2) is trained using data generated by the background knowledge; 3) can generate symbolic explanations of predictions; and 4) can guarantee the satisfaction of logical constraints at test time, which is vital in safety-critical applications. Our experiments show that A-NeSI is the first end-to-end method to scale the Multi-digit MNISTAdd benchmark to sums of 15 MNIST digits, up from 4 in competing systems. Finally, our experiments show that A-NeSI achieves explainability and safety without a penalty in performance.
Prompting as Probing: Using Language Models for Knowledge Base Construction
Aug 25, 2022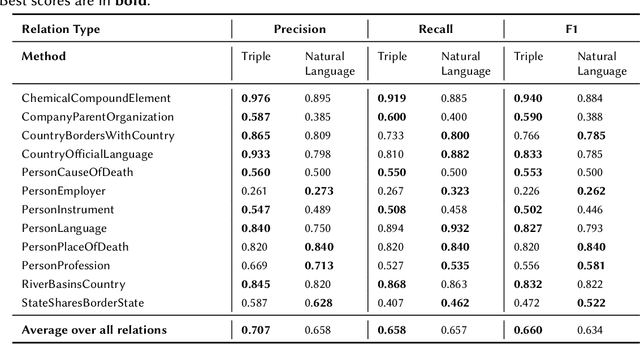
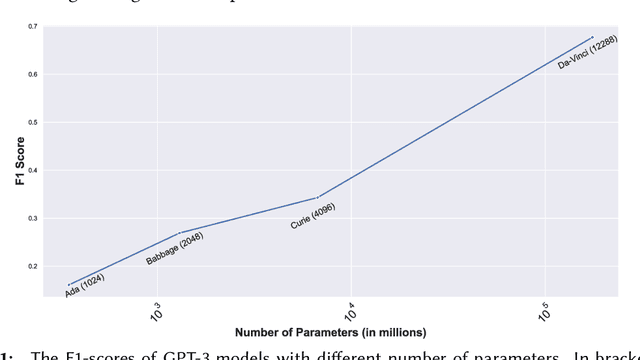
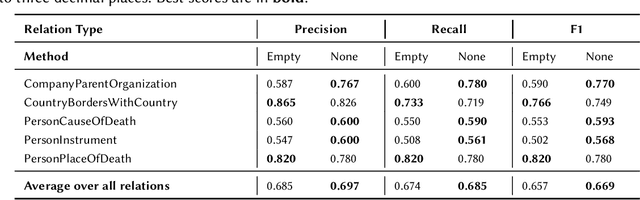
Language Models (LMs) have proven to be useful in various downstream applications, such as summarisation, translation, question answering and text classification. LMs are becoming increasingly important tools in Artificial Intelligence, because of the vast quantity of information they can store. In this work, we present ProP (Prompting as Probing), which utilizes GPT-3, a large Language Model originally proposed by OpenAI in 2020, to perform the task of Knowledge Base Construction (KBC). ProP implements a multi-step approach that combines a variety of prompting techniques to achieve this. Our results show that manual prompt curation is essential, that the LM must be encouraged to give answer sets of variable lengths, in particular including empty answer sets, that true/false questions are a useful device to increase precision on suggestions generated by the LM, that the size of the LM is a crucial factor, and that a dictionary of entity aliases improves the LM score. Our evaluation study indicates that these proposed techniques can substantially enhance the quality of the final predictions: ProP won track 2 of the LM-KBC competition, outperforming the baseline by 36.4 percentage points. Our implementation is available on https://github.com/HEmile/iswc-challenge.
Relational Graph Convolutional Networks: A Closer Look
Jul 21, 2021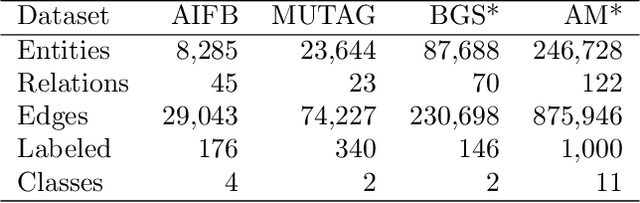
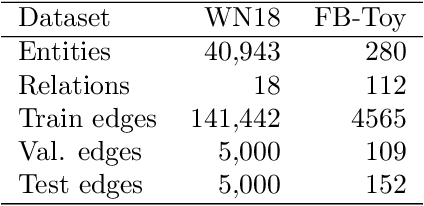
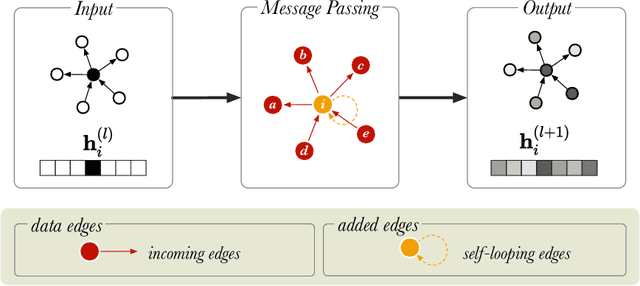
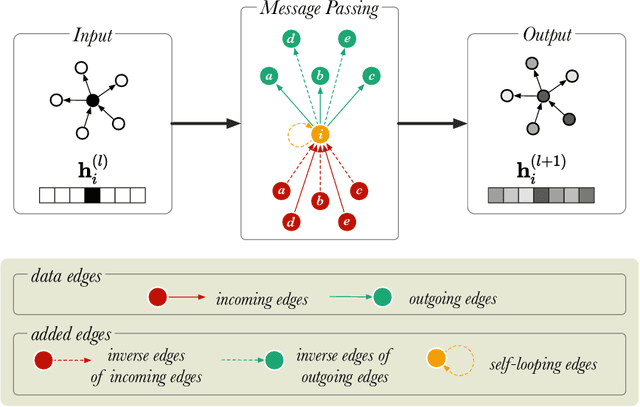
In this paper, we describe a reproduction of the Relational Graph Convolutional Network (RGCN). Using our reproduction, we explain the intuition behind the model. Our reproduction results empirically validate the correctness of our implementations using benchmark Knowledge Graph datasets on node classification and link prediction tasks. Our explanation provides a friendly understanding of the different components of the RGCN for both users and researchers extending the RGCN approach. Furthermore, we introduce two new configurations of the RGCN that are more parameter efficient. The code and datasets are available at https://github.com/thiviyanT/torch-rgcn.
The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles
Apr 02, 2021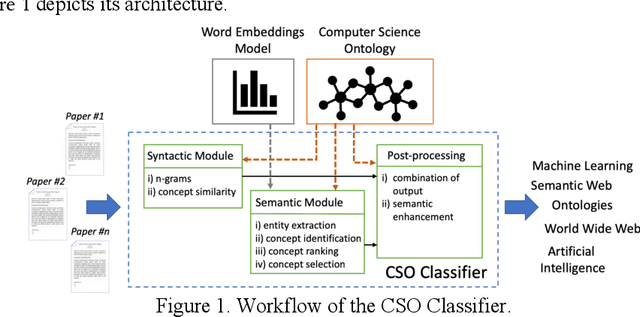
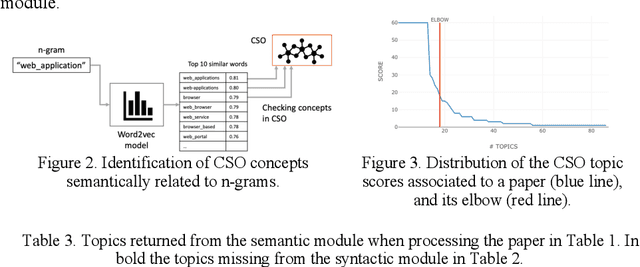
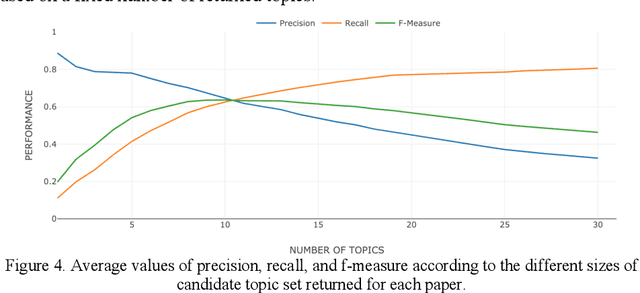
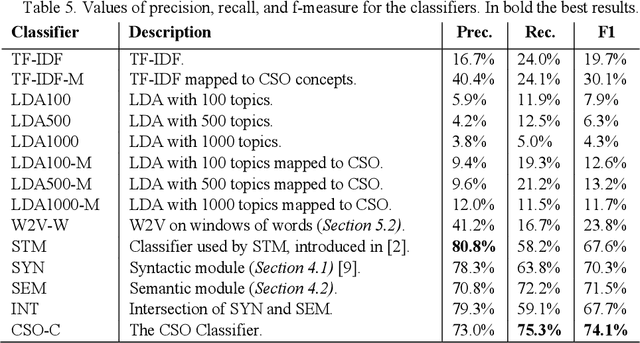
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this paper, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of re-search areas in the field of Computer Science. The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. The approach was evaluated on a gold standard of manually annotated articles yielding a significant improvement over alternative methods.
* Conference paper at TPDL 2019
Ontology-Based Recommendation of Editorial Products
Mar 24, 2021
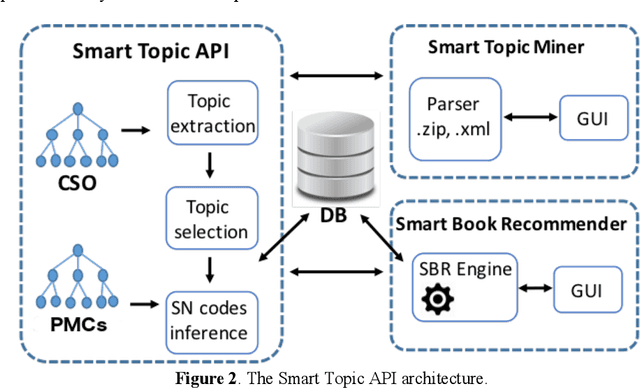

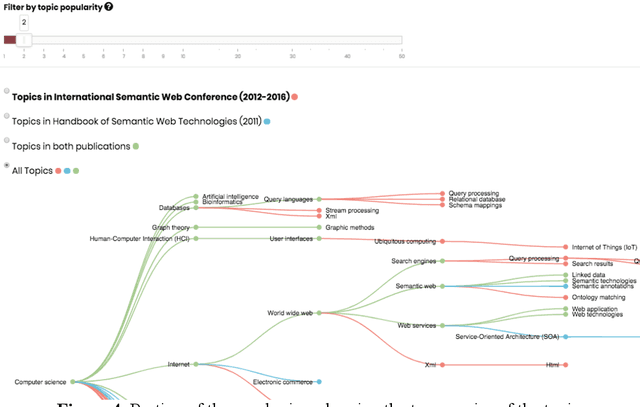
Major academic publishers need to be able to analyse their vast catalogue of products and select the best items to be marketed in scientific venues. This is a complex exercise that requires characterising with a high precision the topics of thousands of books and matching them with the interests of the relevant communities. In Springer Nature, this task has been traditionally handled manually by publishing editors. However, the rapid growth in the number of scientific publications and the dynamic nature of the Computer Science landscape has made this solution increasingly inefficient. We have addressed this issue by creating Smart Book Recommender (SBR), an ontology-based recommender system developed by The Open University (OU) in collaboration with Springer Nature, which supports their Computer Science editorial team in selecting the products to market at specific venues. SBR recommends books, journals, and conference proceedings relevant to a conference by taking advantage of a semantically enhanced representation of about 27K editorial products. This is based on the Computer Science Ontology, a very large-scale, automatically generated taxonomy of research areas. SBR also allows users to investigate why a certain publication was suggested by the system. It does so by means of an interactive graph view that displays the topic taxonomy of the recommended editorial product and compares it with the topic-centric characterization of the input conference. An evaluation carried out with seven Springer Nature editors and seven OU researchers has confirmed the effectiveness of the solution.