 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Towards Semantically Enriched Embeddings for Knowledge Graph Completion
Aug 02, 2023

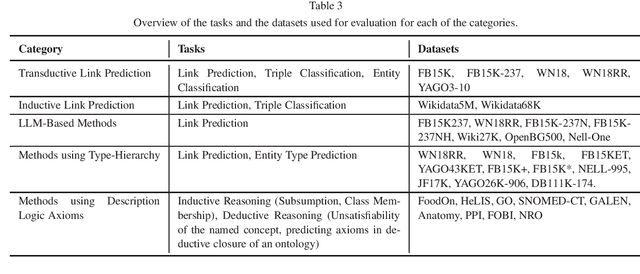
Embedding based Knowledge Graph (KG) Completion has gained much attention over the past few years. Most of the current algorithms consider a KG as a multidirectional labeled graph and lack the ability to capture the semantics underlying the schematic information. In a separate development, a vast amount of information has been captured within the Large Language Models (LLMs) which has revolutionized the field of Artificial Intelligence. KGs could benefit from these LLMs and vice versa. This vision paper discusses the existing algorithms for KG completion based on the variations for generating KG embeddings. It starts with discussing various KG completion algorithms such as transductive and inductive link prediction and entity type prediction algorithms. It then moves on to the algorithms utilizing type information within the KGs, LLMs, and finally to algorithms capturing the semantics represented in different description logic axioms. We conclude the paper with a critical reflection on the current state of work in the community and give recommendations for future directions.
A-NeSI: A Scalable Approximate Method for Probabilistic Neurosymbolic Inference
Dec 23, 2022



We study the problem of combining neural networks with symbolic reasoning. Recently introduced frameworks for Probabilistic Neurosymbolic Learning (PNL), such as DeepProbLog, perform exponential-time exact inference, limiting the scalability of PNL solutions. We introduce Approximate Neurosymbolic Inference (A-NeSI): a new framework for PNL that uses neural networks for scalable approximate inference. A-NeSI 1) performs approximate inference in polynomial time without changing the semantics of probabilistic logics; 2) is trained using data generated by the background knowledge; 3) can generate symbolic explanations of predictions; and 4) can guarantee the satisfaction of logical constraints at test time, which is vital in safety-critical applications. Our experiments show that A-NeSI is the first end-to-end method to scale the Multi-digit MNISTAdd benchmark to sums of 15 MNIST digits, up from 4 in competing systems. Finally, our experiments show that A-NeSI achieves explainability and safety without a penalty in performance.
Refining neural network predictions using background knowledge
Jun 10, 2022
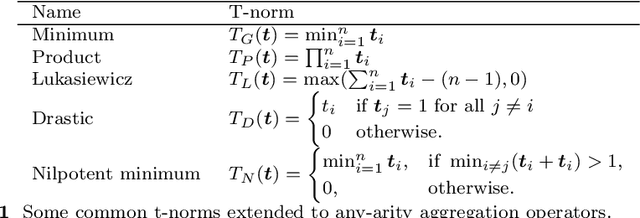
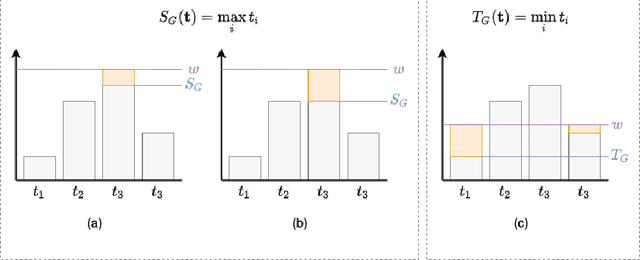
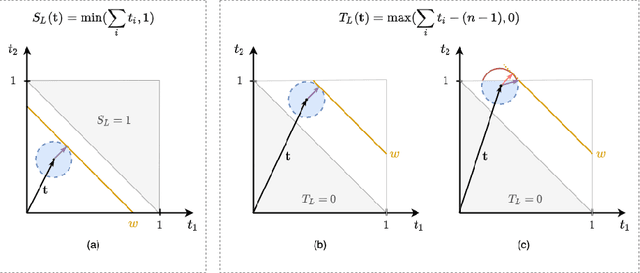
Recent work has showed we can use logical background knowledge in learning system to compensate for a lack of labeled training data. Many such methods work by creating a loss function that encodes this knowledge. However, often the logic is discarded after training, even if it is still useful at test-time. Instead, we ensure neural network predictions satisfy the knowledge by refining the predictions with an extra computation step. We introduce differentiable refinement functions that find a corrected prediction close to the original prediction. We study how to effectively and efficiently compute these refinement functions. Using a new algorithm, we combine refinement functions to find refined predictions for logical formulas of any complexity. This algorithm finds optimal refinements on complex SAT formulas in significantly fewer iterations and frequently finds solutions where gradient descent can not.
Modular Design Patterns for Hybrid Learning and Reasoning Systems: a taxonomy, patterns and use cases
Feb 23, 2021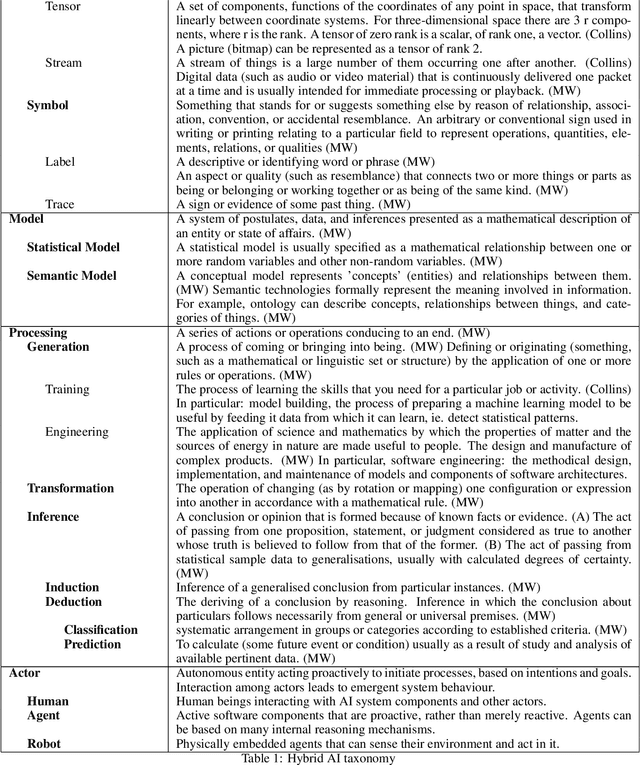
The unification of statistical (data-driven) and symbolic (knowledge-driven) methods is widely recognised as one of the key challenges of modern AI. Recent years have seen large number of publications on such hybrid neuro-symbolic AI systems. That rapidly growing literature is highly diverse and mostly empirical, and is lacking a unifying view of the large variety of these hybrid systems. In this paper we analyse a large body of recent literature and we propose a set of modular design patterns for such hybrid, neuro-symbolic systems. We are able to describe the architecture of a very large number of hybrid systems by composing only a small set of elementary patterns as building blocks. The main contributions of this paper are: 1) a taxonomically organised vocabulary to describe both processes and data structures used in hybrid systems; 2) a set of 15+ design patterns for hybrid AI systems, organised in a set of elementary patterns and a set of compositional patterns; 3) an application of these design patterns in two realistic use-cases for hybrid AI systems. Our patterns reveal similarities between systems that were not recognised until now. Finally, our design patterns extend and refine Kautz' earlier attempt at categorising neuro-symbolic architectures.
Analyzing Differentiable Fuzzy Implications
Jun 04, 2020

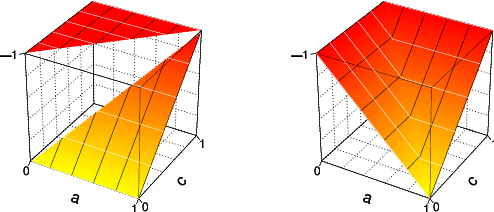

Combining symbolic and neural approaches has gained considerable attention in the AI community, as it is often argued that the strengths and weaknesses of these approaches are complementary. One such trend in the literature are weakly supervised learning techniques that employ operators from fuzzy logics. In particular, they use prior background knowledge described in such logics to help the training of a neural network from unlabeled and noisy data. By interpreting logical symbols using neural networks (or grounding them), this background knowledge can be added to regular loss functions, hence making reasoning a part of learning. In this paper, we investigate how implications from the fuzzy logic literature behave in a differentiable setting. In such a setting, we analyze the differences between the formal properties of these fuzzy implications. It turns out that various fuzzy implications, including some of the most well-known, are highly unsuitable for use in a differentiable learning setting. A further finding shows a strong imbalance between gradients driven by the antecedent and the consequent of the implication. Furthermore, we introduce a new family of fuzzy implications (called sigmoidal implications) to tackle this phenomenon. Finally, we empirically show that it is possible to use Differentiable Fuzzy Logics for semi-supervised learning, and show that sigmoidal implications outperform other choices of fuzzy implications.
Analyzing Differentiable Fuzzy Logic Operators
Feb 14, 2020



In recent years there has been a push to integrate symbolic AI and deep learning, as it is argued that the strengths and weaknesses of these approaches are complementary. One such trend in the literature are weakly supervised learning techniques that use operators from fuzzy logics. They employ prior background knowledge described in logic to benefit the training of a neural network from unlabeled and noisy data. By interpreting logical symbols using neural networks, this background knowledge can be added to regular loss functions used in deep learning to integrate reasoning and learning. In this paper, we analyze how a large collection of logical operators from the fuzzy logic literature behave in a differentiable setting. We find large differences between the formal properties of these operators that are of crucial importance in a differentiable learning setting. We show that many of these operators, including some of the best known, are highly unsuitable for use in a differentiable learning setting. A further finding concerns the treatment of implication in these fuzzy logics, with a strong imbalance between gradients driven by the antecedent and the consequent of the implication. Finally, we empirically show that it is possible to use Differentiable Fuzzy Logics for semi-supervised learning. However, to achieve the most significant performance improvement over a supervised baseline, we have to resort to non-standard combinations of logical operators which perform well in learning, but which no longer satisfy the usual logical laws. We end with a discussion on extensions to large-scale problems.
Semi-Supervised Learning using Differentiable Reasoning
Aug 13, 2019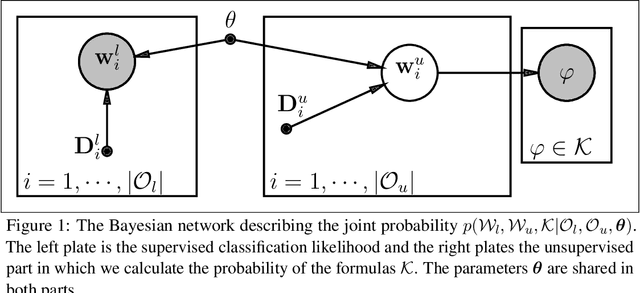


We introduce Differentiable Reasoning (DR), a novel semi-supervised learning technique which uses relational background knowledge to benefit from unlabeled data. We apply it to the Semantic Image Interpretation (SII) task and show that background knowledge provides significant improvement. We find that there is a strong but interesting imbalance between the contributions of updates from Modus Ponens (MP) and its logical equivalent Modus Tollens (MT) to the learning process, suggesting that our approach is very sensitive to a phenomenon called the Raven Paradox. We propose a solution to overcome this situation.
Reinforcement Learning for Personalized Dialogue Management
Aug 01, 2019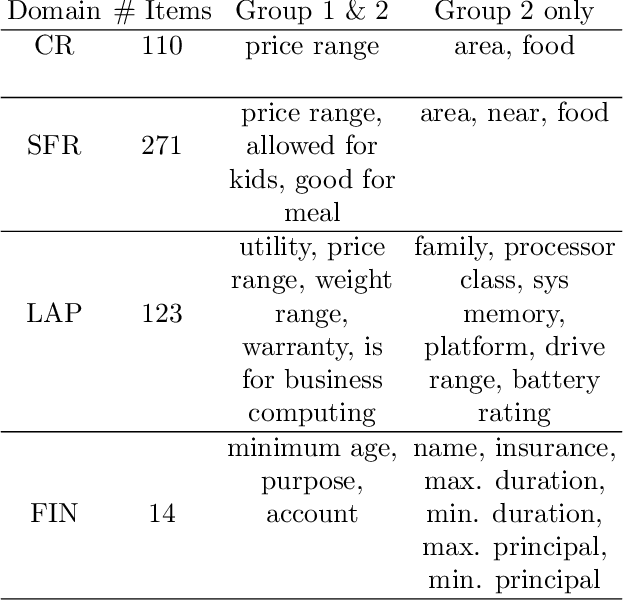
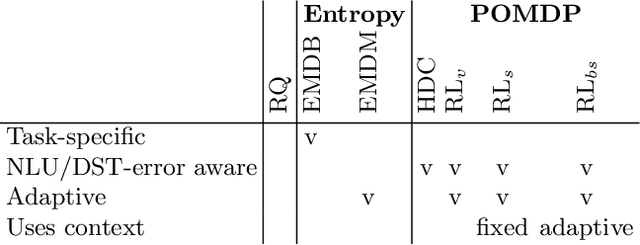
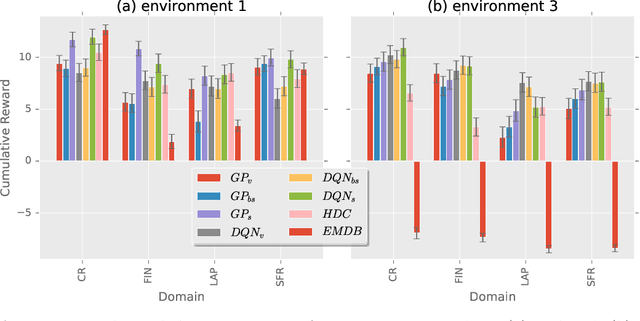
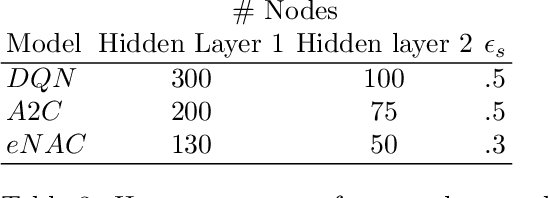
Language systems have been of great interest to the research community and have recently reached the mass market through various assistant platforms on the web. Reinforcement Learning methods that optimize dialogue policies have seen successes in past years and have recently been extended into methods that personalize the dialogue, e.g. take the personal context of users into account. These works, however, are limited to personalization to a single user with whom they require multiple interactions and do not generalize the usage of context across users. This work introduces a problem where a generalized usage of context is relevant and proposes two Reinforcement Learning (RL)-based approaches to this problem. The first approach uses a single learner and extends the traditional POMDP formulation of dialogue state with features that describe the user context. The second approach segments users by context and then employs a learner per context. We compare these approaches in a benchmark of existing non-RL and RL-based methods in three established and one novel application domain of financial product recommendation. We compare the influence of context and training experiences on performance and find that learning approaches generally outperform a handcrafted gold standard.