 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting message modification attacks on the CAN bus with Temporal Convolutional Networks
Jun 16, 2021
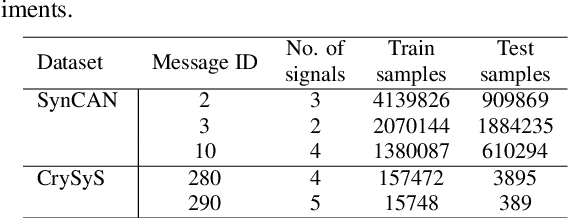
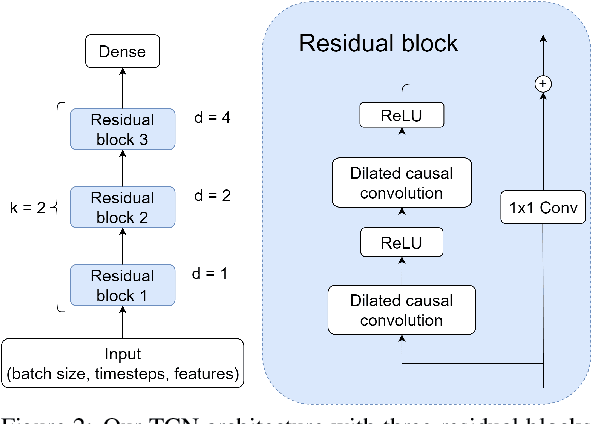

Multiple attacks have shown that in-vehicle networks have vulnerabilities which can be exploited. Securing the Controller Area Network (CAN) for modern vehicles has become a necessary task for car manufacturers. Some attacks inject potentially large amount of fake messages into the CAN network; however, such attacks are relatively easy to detect. In more sophisticated attacks, the original messages are modified, making the detection a more complex problem. In this paper, we present a novel machine learning based intrusion detection method for CAN networks. We focus on detecting message modification attacks, which do not change the timing patterns of communications. Our proposed temporal convolutional network-based solution can learn the normal behavior of CAN signals and differentiate them from malicious ones. The method is evaluated on multiple CAN-bus message IDs from two public datasets including different types of attacks. Performance results show that our lightweight approach compares favorably to the state-of-the-art unsupervised learning approach, achieving similar or better accuracy for a wide range of scenarios with a significantly lower false positive rate.
Solving Financial Regulatory Compliance Using Software Contracts
Sep 11, 2019
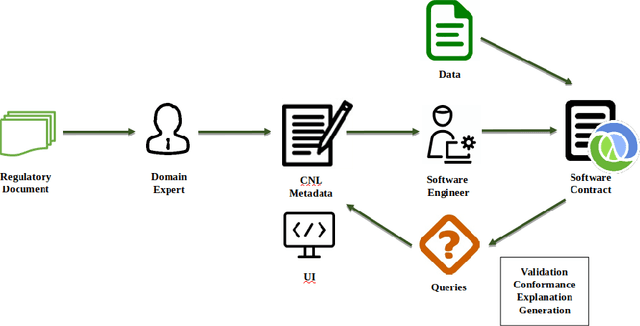

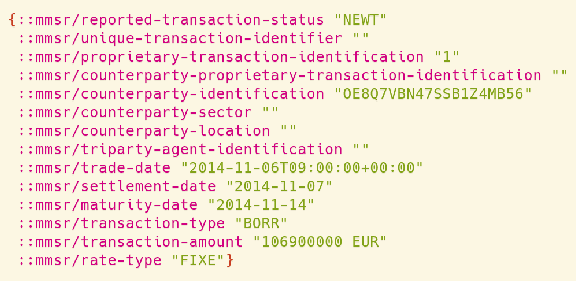
Ensuring compliance with various laws and regulations is of utmost priority for financial institutions. Traditional methods in this area have been shown to be inefficient. Manual processing does not scale well. Automated efforts are hindered due to the lack of formalization of domain knowledge and problems of integrating such knowledge into software systems. In this work we propose an approach to tackle these issues by encoding them into software contracts using a Controlled Natural Language. In particular, we encode a portion of the Money Market Statistical Reporting (MMSR) regulations into contracts specified by the clojure.spec framework. We show how various features of a contract framework, in particular clojure.spec, can help to tackle issues that occur when dealing with compliance: validation with explanations and test data generation. We benchmark our proposed solution and show that this approach can effectively solve compliance issues in this particular use case.
Reinforcement Learning for Personalized Dialogue Management
Aug 01, 2019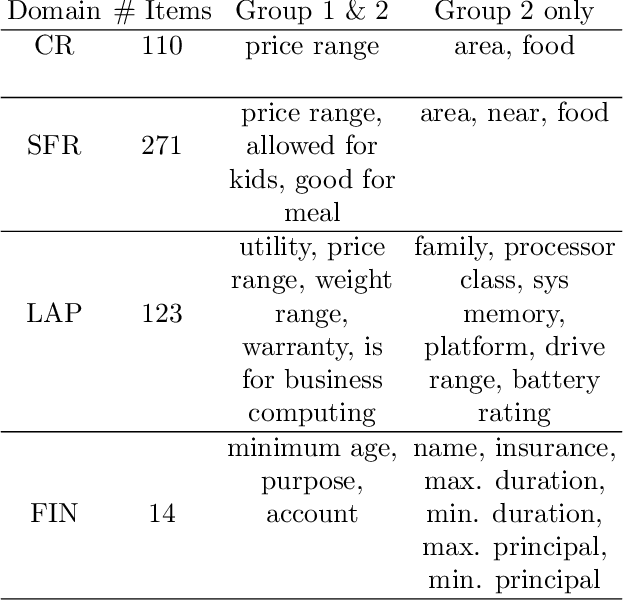
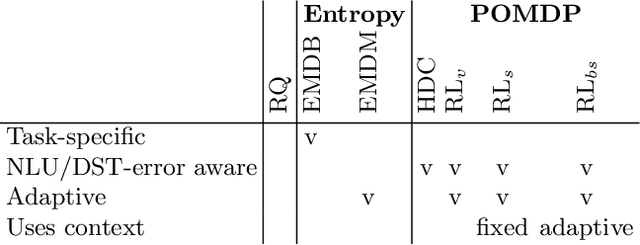
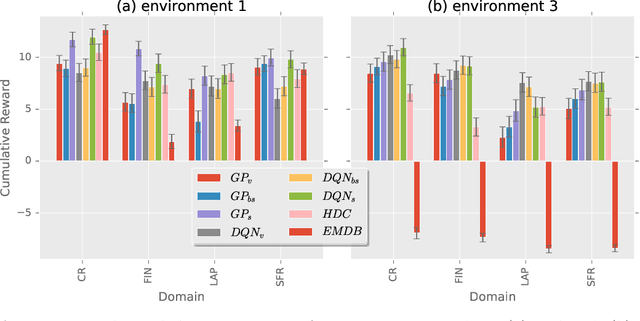
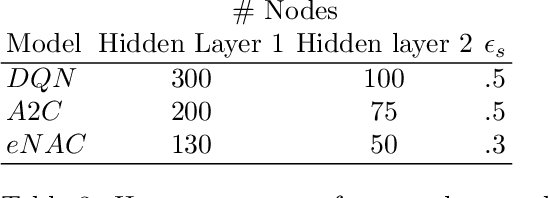
Language systems have been of great interest to the research community and have recently reached the mass market through various assistant platforms on the web. Reinforcement Learning methods that optimize dialogue policies have seen successes in past years and have recently been extended into methods that personalize the dialogue, e.g. take the personal context of users into account. These works, however, are limited to personalization to a single user with whom they require multiple interactions and do not generalize the usage of context across users. This work introduces a problem where a generalized usage of context is relevant and proposes two Reinforcement Learning (RL)-based approaches to this problem. The first approach uses a single learner and extends the traditional POMDP formulation of dialogue state with features that describe the user context. The second approach segments users by context and then employs a learner per context. We compare these approaches in a benchmark of existing non-RL and RL-based methods in three established and one novel application domain of financial product recommendation. We compare the influence of context and training experiences on performance and find that learning approaches generally outperform a handcrafted gold standard.