 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Quantile Regression for the Interpretable Prediction of Conditional Quantiles
Aug 11, 2025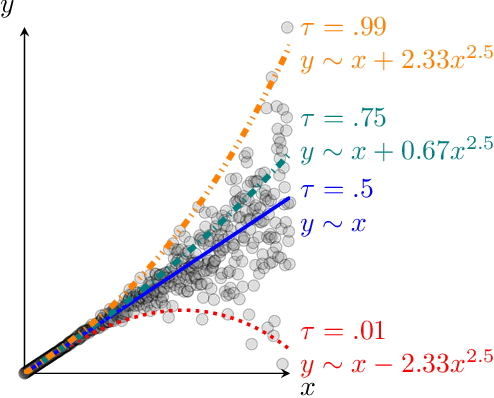

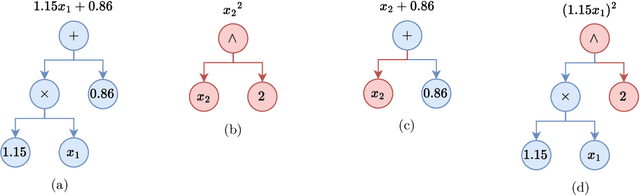
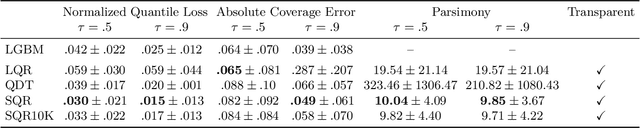
Symbolic Regression (SR) is a well-established framework for generating interpretable or white-box predictive models. Although SR has been successfully applied to create interpretable estimates of the average of the outcome, it is currently not well understood how it can be used to estimate the relationship between variables at other points in the distribution of the target variable. Such estimates of e.g. the median or an extreme value provide a fuller picture of how predictive variables affect the outcome and are necessary in high-stakes, safety-critical application domains. This study introduces Symbolic Quantile Regression (SQR), an approach to predict conditional quantiles with SR. In an extensive evaluation, we find that SQR outperforms transparent models and performs comparably to a strong black-box baseline without compromising transparency. We also show how SQR can be used to explain differences in the target distribution by comparing models that predict extreme and central outcomes in an airline fuel usage case study. We conclude that SQR is suitable for predicting conditional quantiles and understanding interesting feature influences at varying quantiles.
Detecting Linguistic Bias in Government Documents Using Large language Models
Feb 19, 2025



This paper addresses the critical need for detecting bias in government documents, an underexplored area with significant implications for governance. Existing methodologies often overlook the unique context and far-reaching impacts of governmental documents, potentially obscuring embedded biases that shape public policy and citizen-government interactions. To bridge this gap, we introduce the Dutch Government Data for Bias Detection (DGDB), a dataset sourced from the Dutch House of Representatives and annotated for bias by experts. We fine-tune several BERT-based models on this dataset and compare their performance with that of generative language models. Additionally, we conduct a comprehensive error analysis that includes explanations of the models' predictions. Our findings demonstrate that fine-tuned models achieve strong performance and significantly outperform generative language models, indicating the effectiveness of DGDB for bias detection. This work underscores the importance of labeled datasets for bias detection in various languages and contributes to more equitable governance practices.
SHARPIE: A Modular Framework for Reinforcement Learning and Human-AI Interaction Experiments
Jan 31, 2025


Reinforcement learning (RL) offers a general approach for modeling and training AI agents, including human-AI interaction scenarios. In this paper, we propose SHARPIE (Shared Human-AI Reinforcement Learning Platform for Interactive Experiments) to address the need for a generic framework to support experiments with RL agents and humans. Its modular design consists of a versatile wrapper for RL environments and algorithm libraries, a participant-facing web interface, logging utilities, deployment on popular cloud and participant recruitment platforms. It empowers researchers to study a wide variety of research questions related to the interaction between humans and RL agents, including those related to interactive reward specification and learning, learning from human feedback, action delegation, preference elicitation, user-modeling, and human-AI teaming. The platform is based on a generic interface for human-RL interactions that aims to standardize the field of study on RL in human contexts.
Conformal Intent Classification and Clarification for Fast and Accurate Intent Recognition
Mar 27, 2024We present Conformal Intent Classification and Clarification (CICC), a framework for fast and accurate intent classification for task-oriented dialogue systems. The framework turns heuristic uncertainty scores of any intent classifier into a clarification question that is guaranteed to contain the true intent at a pre-defined confidence level. By disambiguating between a small number of likely intents, the user query can be resolved quickly and accurately. Additionally, we propose to augment the framework for out-of-scope detection. In a comparative evaluation using seven intent recognition datasets we find that CICC generates small clarification questions and is capable of out-of-scope detection. CICC can help practitioners and researchers substantially in improving the user experience of dialogue agents with specific clarification questions.
Explainable Fraud Detection with Deep Symbolic Classification
Dec 01, 2023

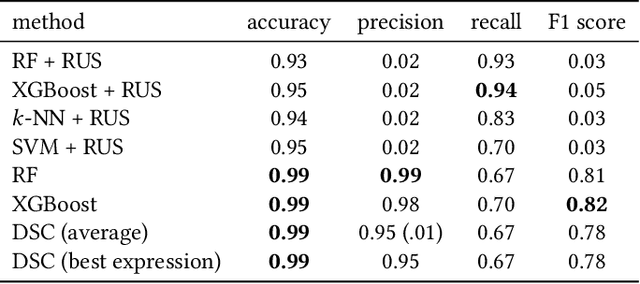

There is a growing demand for explainable, transparent, and data-driven models within the domain of fraud detection. Decisions made by fraud detection models need to be explainable in the event of a customer dispute. Additionally, the decision-making process in the model must be transparent to win the trust of regulators and business stakeholders. At the same time, fraud detection solutions can benefit from data due to the noisy, dynamic nature of fraud and the availability of large historical data sets. Finally, fraud detection is notorious for its class imbalance: there are typically several orders of magnitude more legitimate transactions than fraudulent ones. In this paper, we present Deep Symbolic Classification (DSC), an extension of the Deep Symbolic Regression framework to classification problems. DSC casts classification as a search problem in the space of all analytic functions composed of a vocabulary of variables, constants, and operations and optimizes for an arbitrary evaluation metric directly. The search is guided by a deep neural network trained with reinforcement learning. Because the functions are mathematical expressions that are in closed-form and concise, the model is inherently explainable both at the level of a single classification decision and the model's decision process. Furthermore, the class imbalance problem is successfully addressed by optimizing for metrics that are robust to class imbalance such as the F1 score. This eliminates the need for oversampling and undersampling techniques that plague traditional approaches. Finally, the model allows to explicitly balance between the prediction accuracy and the explainability. An evaluation on the PaySim data set demonstrates competitive predictive performance with state-of-the-art models, while surpassing them in terms of explainability. This establishes DSC as a promising model for fraud detection systems.
Reinforcement Learning for Personalized Dialogue Management
Aug 01, 2019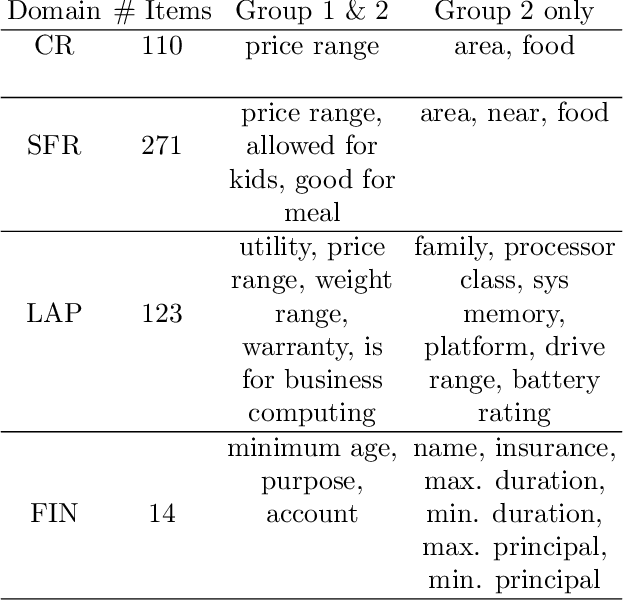
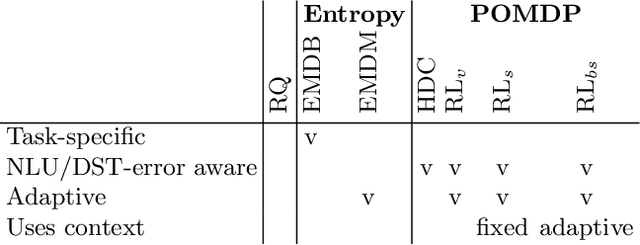
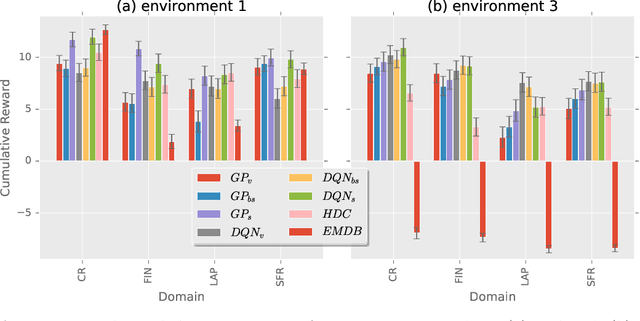
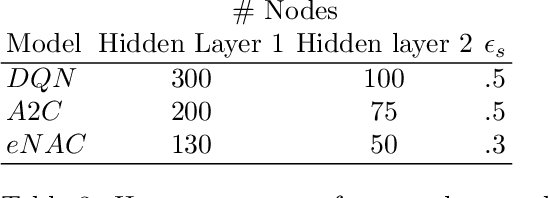
Language systems have been of great interest to the research community and have recently reached the mass market through various assistant platforms on the web. Reinforcement Learning methods that optimize dialogue policies have seen successes in past years and have recently been extended into methods that personalize the dialogue, e.g. take the personal context of users into account. These works, however, are limited to personalization to a single user with whom they require multiple interactions and do not generalize the usage of context across users. This work introduces a problem where a generalized usage of context is relevant and proposes two Reinforcement Learning (RL)-based approaches to this problem. The first approach uses a single learner and extends the traditional POMDP formulation of dialogue state with features that describe the user context. The second approach segments users by context and then employs a learner per context. We compare these approaches in a benchmark of existing non-RL and RL-based methods in three established and one novel application domain of financial product recommendation. We compare the influence of context and training experiences on performance and find that learning approaches generally outperform a handcrafted gold standard.