 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoIdeator: Evolving Scientific Ideas through Checklist-Grounded Reinforcement Learning
Mar 23, 2026Scientific idea generation is a cornerstone of autonomous knowledge discovery, yet the iterative evolution required to transform initial concepts into high-quality research proposals remains a formidable challenge for Large Language Models (LLMs). Existing Reinforcement Learning (RL) paradigms often rely on rubric-based scalar rewards that provide global quality scores but lack actionable granularity. Conversely, language-based refinement methods are typically confined to inference-time prompting, targeting models that are not explicitly optimized to internalize such critiques. To bridge this gap, we propose \textbf{EvoIdeator}, a framework that facilitates the evolution of scientific ideas by aligning the RL training objective with \textbf{checklist-grounded feedback}. EvoIdeator leverages a structured judge model to generate two synergistic signals: (1) \emph{lexicographic rewards} for multi-dimensional optimization, and (2) \emph{fine-grained language feedback} that offers span-level critiques regarding grounding, feasibility, and methodological rigor. By integrating these signals into the RL loop, we condition the policy to systematically utilize precise feedback during both optimization and inference. Extensive experiments demonstrate that EvoIdeator, built on Qwen3-4B, significantly outperforms much larger frontier models across key scientific metrics. Crucially, the learned policy exhibits strong generalization to diverse external feedback sources without further fine-tuning, offering a scalable and rigorous path toward self-refining autonomous ideation.
ACTIVA: Amortized Causal Effect Estimation without Graphs via Transformer-based Variational Autoencoder
Mar 03, 2025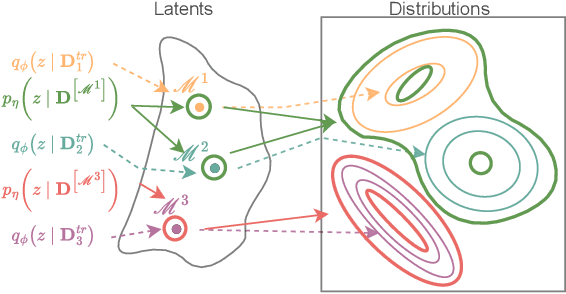
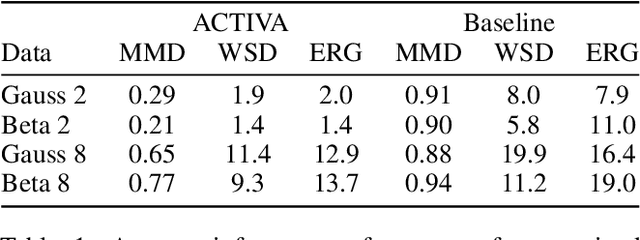
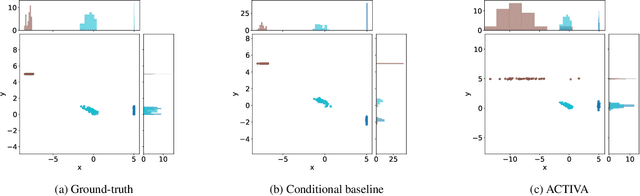

Predicting the distribution of outcomes under hypothetical interventions is crucial in domains like healthcare, economics, and policy-making. Current methods often rely on strong assumptions, such as known causal graphs or parametric models, and lack amortization across problem instances, limiting their practicality. We propose a novel transformer-based conditional variational autoencoder architecture, named ACTIVA, that extends causal transformer encoders to predict causal effects as mixtures of Gaussians. Our method requires no causal graph and predicts interventional distributions given only observational data and a queried intervention. By amortizing over many simulated instances, it enables zero-shot generalization to novel datasets without retraining. Experiments demonstrate accurate predictions for synthetic and semi-synthetic data, showcasing the effectiveness of our graph-free, amortized causal inference approach.
SHARPIE: A Modular Framework for Reinforcement Learning and Human-AI Interaction Experiments
Jan 31, 2025


Reinforcement learning (RL) offers a general approach for modeling and training AI agents, including human-AI interaction scenarios. In this paper, we propose SHARPIE (Shared Human-AI Reinforcement Learning Platform for Interactive Experiments) to address the need for a generic framework to support experiments with RL agents and humans. Its modular design consists of a versatile wrapper for RL environments and algorithm libraries, a participant-facing web interface, logging utilities, deployment on popular cloud and participant recruitment platforms. It empowers researchers to study a wide variety of research questions related to the interaction between humans and RL agents, including those related to interactive reward specification and learning, learning from human feedback, action delegation, preference elicitation, user-modeling, and human-AI teaming. The platform is based on a generic interface for human-RL interactions that aims to standardize the field of study on RL in human contexts.
CAGE: Causality-Aware Shapley Value for Global Explanations
Apr 17, 2024



As Artificial Intelligence (AI) is having more influence on our everyday lives, it becomes important that AI-based decisions are transparent and explainable. As a consequence, the field of eXplainable AI (or XAI) has become popular in recent years. One way to explain AI models is to elucidate the predictive importance of the input features for the AI model in general, also referred to as global explanations. Inspired by cooperative game theory, Shapley values offer a convenient way for quantifying the feature importance as explanations. However many methods based on Shapley values are built on the assumption of feature independence and often overlook causal relations of the features which could impact their importance for the ML model. Inspired by studies of explanations at the local level, we propose CAGE (Causally-Aware Shapley Values for Global Explanations). In particular, we introduce a novel sampling procedure for out-coalition features that respects the causal relations of the input features. We derive a practical approach that incorporates causal knowledge into global explanation and offers the possibility to interpret the predictive feature importance considering their causal relation. We evaluate our method on synthetic data and real-world data. The explanations from our approach suggest that they are not only more intuitive but also more faithful compared to previous global explanation methods.
EduGym: An Environment Suite for Reinforcement Learning Education
Nov 17, 2023


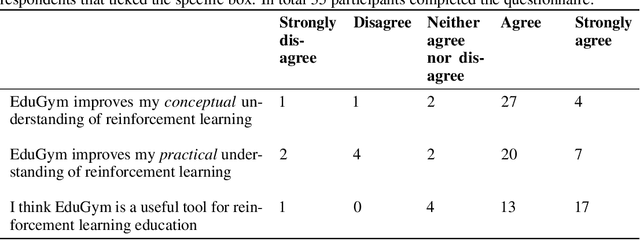
Due to the empirical success of reinforcement learning, an increasing number of students study the subject. However, from our practical teaching experience, we see students entering the field (bachelor, master and early PhD) often struggle. On the one hand, textbooks and (online) lectures provide the fundamentals, but students find it hard to translate between equations and code. On the other hand, public codebases do provide practical examples, but the implemented algorithms tend to be complex, and the underlying test environments contain multiple reinforcement learning challenges at once. Although this is realistic from a research perspective, it often hinders educational conceptual understanding. To solve this issue we introduce EduGym, a set of educational reinforcement learning environments and associated interactive notebooks tailored for education. Each EduGym environment is specifically designed to illustrate a certain aspect/challenge of reinforcement learning (e.g., exploration, partial observability, stochasticity, etc.), while the associated interactive notebook explains the challenge and its possible solution approaches, connecting equations and code in a single document. An evaluation among RL students and researchers shows 86% of them think EduGym is a useful tool for reinforcement learning education. All notebooks are available from https://sites.google.com/view/edu-gym/home, while the full software package can be installed from https://github.com/RLG-Leiden/edugym.
Evaluation of GPT-4 for chest X-ray impression generation: A reader study on performance and perception
Nov 12, 2023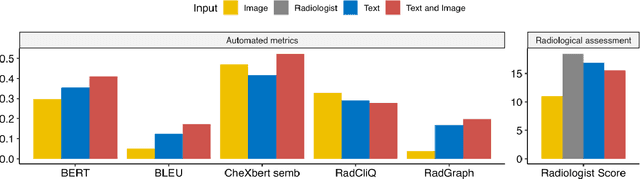
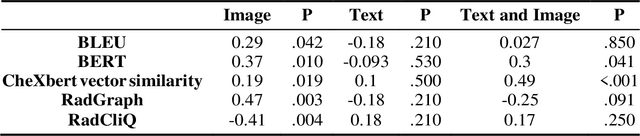
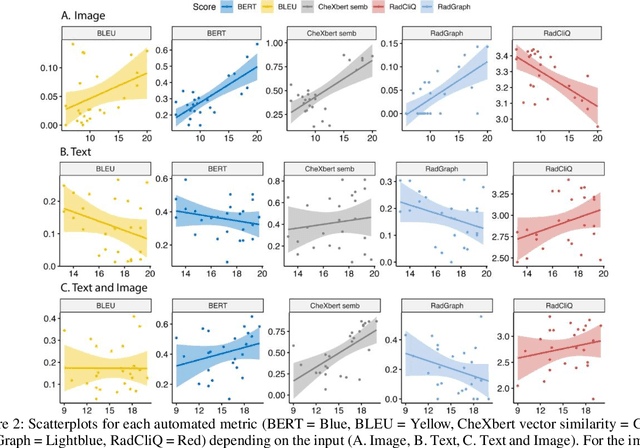
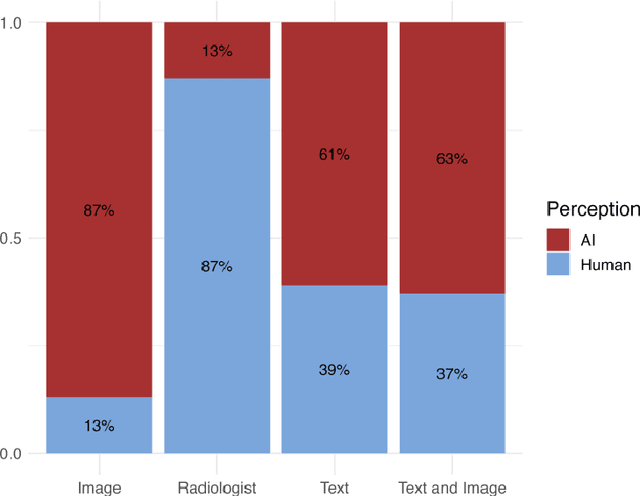
The remarkable generative capabilities of multimodal foundation models are currently being explored for a variety of applications. Generating radiological impressions is a challenging task that could significantly reduce the workload of radiologists. In our study we explored and analyzed the generative abilities of GPT-4 for Chest X-ray impression generation. To generate and evaluate impressions of chest X-rays based on different input modalities (image, text, text and image), a blinded radiological report was written for 25-cases of the publicly available NIH-dataset. GPT-4 was given image, finding section or both sequentially to generate an input dependent impression. In a blind randomized reading, 4-radiologists rated the impressions and were asked to classify the impression origin (Human, AI), providing justification for their decision. Lastly text model evaluation metrics and their correlation with the radiological score (summation of the 4 dimensions) was assessed. According to the radiological score, the human-written impression was rated highest, although not significantly different to text-based impressions. The automated evaluation metrics showed moderate to substantial correlations to the radiological score for the image impressions, however individual scores were highly divergent among inputs, indicating insufficient representation of radiological quality. Detection of AI-generated impressions varied by input and was 61% for text-based impressions. Impressions classified as AI-generated had significantly worse radiological scores even when written by a radiologist, indicating potential bias. Our study revealed significant discrepancies between a radiological assessment and common automatic evaluation metrics depending on the model input. The detection of AI-generated findings is subject to bias that highly rated impressions are perceived as human-written.
Improving Image Quality of Sparse-view Lung Cancer CT Images with a Convolutional Neural Network
Jul 28, 2023Purpose: To improve the image quality of sparse-view computed tomography (CT) images with a U-Net for lung cancer detection and to determine the best trade-off between number of views, image quality, and diagnostic confidence. Methods: CT images from 41 subjects (34 with lung cancer, seven healthy) were retrospectively selected (01.2016-12.2018) and forward projected onto 2048-view sinograms. Six corresponding sparse-view CT data subsets at varying levels of undersampling were reconstructed from sinograms using filtered backprojection with 16, 32, 64, 128, 256, and 512 views, respectively. A dual-frame U-Net was trained and evaluated for each subsampling level on 8,658 images from 22 diseased subjects. A representative image per scan was selected from 19 subjects (12 diseased, seven healthy) for a single-blinded reader study. The selected slices, for all levels of subsampling, with and without post-processing by the U-Net model, were presented to three readers. Image quality and diagnostic confidence were ranked using pre-defined scales. Subjective nodule segmentation was evaluated utilizing sensitivity (Se) and Dice Similarity Coefficient (DSC) with 95% confidence intervals (CI). Results: The 64-projection sparse-view images resulted in Se = 0.89 and DSC = 0.81 [0.75,0.86] while their counterparts, post-processed with the U-Net, had improved metrics (Se = 0.94, DSC = 0.85 [0.82,0.87]). Fewer views lead to insufficient quality for diagnostic purposes. For increased views, no substantial discrepancies were noted between the sparse-view and post-processed images. Conclusion: Projection views can be reduced from 2048 to 64 while maintaining image quality and the confidence of the radiologists on a satisfactory level.
A Meta-Reinforcement Learning Algorithm for Causal Discovery
Jul 18, 2022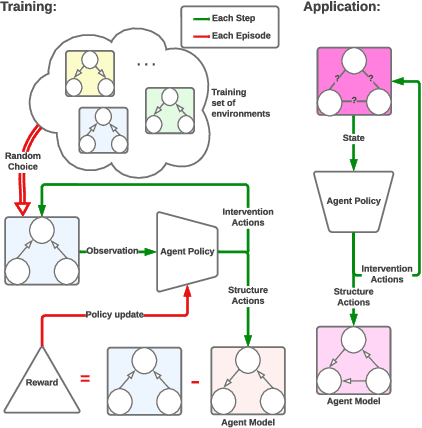
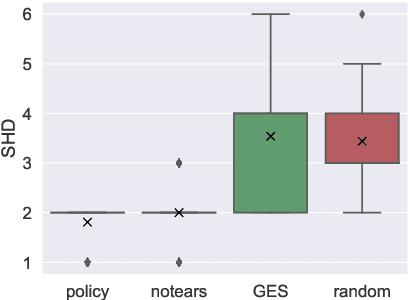
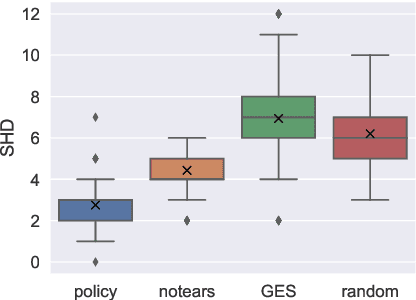
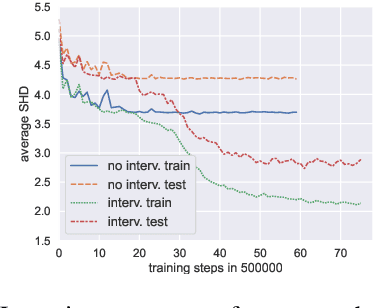
Causal discovery is a major task with the utmost importance for machine learning since causal structures can enable models to go beyond pure correlation-based inference and significantly boost their performance. However, finding causal structures from data poses a significant challenge both in computational effort and accuracy, let alone its impossibility without interventions in general. In this paper, we develop a meta-reinforcement learning algorithm that performs causal discovery by learning to perform interventions such that it can construct an explicit causal graph. Apart from being useful for possible downstream applications, the estimated causal graph also provides an explanation for the data-generating process. In this article, we show that our algorithm estimates a good graph compared to the SOTA approaches, even in environments whose underlying causal structure is previously unseen. Further, we make an ablation study that shows how learning interventions contribute to the overall performance of our approach. We conclude that interventions indeed help boost the performance, efficiently yielding an accurate estimate of the causal structure of a possibly unseen environment.