 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Training Modulates Harmful Misalignment Under On-Policy RL, But Direction Depends on Environment Design
Apr 14, 2026Specification gaming under Reinforcement Learning (RL) is known to cause LLMs to develop sycophantic, manipulative, or deceptive behavior, yet the conditions under which this occurs remain unclear. We train 11 instruction-tuned LLMs (0.5B--14B) with on-policy RL across 3 environments and find that model size acts as a safety buffer in some environments but enables greater harmful exploitation in others. Controlled ablations trace this reversal to environment-specific features such as role framing and implicit gameability cues. We further show that most safety benchmarks do not predict RL-induced misalignment, except in the case of Sycophancy scores when the exploit relies on inferring the user's preference. Finally, we find that on-policy RL preserves a safety buffer inherent in the model's own generation distribution, one that is bypassed during off-policy settings.
Neuro-symbolic Action Masking for Deep Reinforcement Learning
Feb 11, 2026Deep reinforcement learning (DRL) may explore infeasible actions during training and execution. Existing approaches assume a symbol grounding function that maps high-dimensional states to consistent symbolic representations and a manually specified action masking techniques to constrain actions. In this paper, we propose Neuro-symbolic Action Masking (NSAM), a novel framework that automatically learn symbolic models, which are consistent with given domain constraints of high-dimensional states, in a minimally supervised manner during the DRL process. Based on the learned symbolic model of states, NSAM learns action masks that rules out infeasible actions. NSAM enables end-to-end integration of symbolic reasoning and deep policy optimization, where improvements in symbolic grounding and policy learning mutually reinforce each other. We evaluate NSAM on multiple domains with constraints, and experimental results demonstrate that NSAM significantly improves sample efficiency of DRL agent while substantially reducing constraint violations.
Credit Assignment and Efficient Exploration based on Influence Scope in Multi-agent Reinforcement Learning
May 13, 2025



Training cooperative agents in sparse-reward scenarios poses significant challenges for multi-agent reinforcement learning (MARL). Without clear feedback on actions at each step in sparse-reward setting, previous methods struggle with precise credit assignment among agents and effective exploration. In this paper, we introduce a novel method to deal with both credit assignment and exploration problems in reward-sparse domains. Accordingly, we propose an algorithm that calculates the Influence Scope of Agents (ISA) on states by taking specific value of the dimensions/attributes of states that can be influenced by individual agents. The mutual dependence between agents' actions and state attributes are then used to calculate the credit assignment and to delimit the exploration space for each individual agent. We then evaluate ISA in a variety of sparse-reward multi-agent scenarios. The results show that our method significantly outperforms the state-of-art baselines.
Short-circuiting Shortcuts: Mechanistic Investigation of Shortcuts in Text Classification
May 09, 2025Reliance on spurious correlations (shortcuts) has been shown to underlie many of the successes of language models. Previous work focused on identifying the input elements that impact prediction. We investigate how shortcuts are actually processed within the model's decision-making mechanism. We use actor names in movie reviews as controllable shortcuts with known impact on the outcome. We use mechanistic interpretability methods and identify specific attention heads that focus on shortcuts. These heads gear the model towards a label before processing the complete input, effectively making premature decisions that bypass contextual analysis. Based on these findings, we introduce Head-based Token Attribution (HTA), which traces intermediate decisions back to input tokens. We show that HTA is effective in detecting shortcuts in LLMs and enables targeted mitigation by selectively deactivating shortcut-related attention heads.
Reducing Variance Caused by Communication in Decentralized Multi-agent Deep Reinforcement Learning
Feb 10, 2025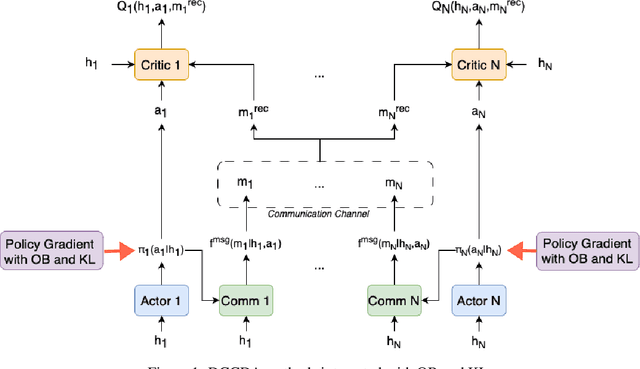
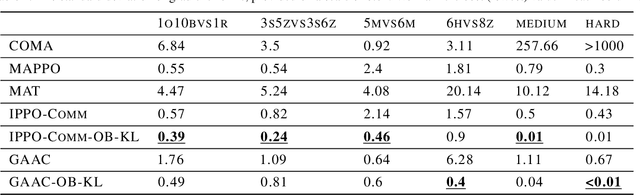
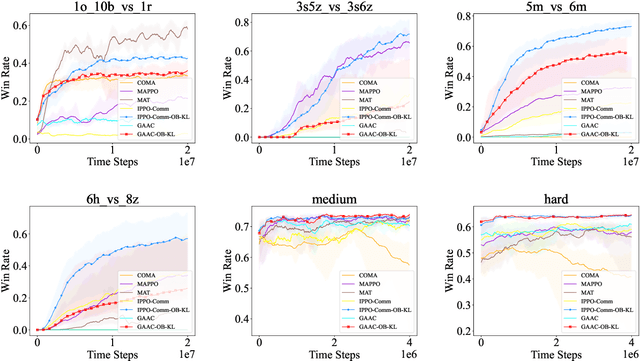

In decentralized multi-agent deep reinforcement learning (MADRL), communication can help agents to gain a better understanding of the environment to better coordinate their behaviors. Nevertheless, communication may involve uncertainty, which potentially introduces variance to the learning of decentralized agents. In this paper, we focus on a specific decentralized MADRL setting with communication and conduct a theoretical analysis to study the variance that is caused by communication in policy gradients. We propose modular techniques to reduce the variance in policy gradients during training. We adopt our modular techniques into two existing algorithms for decentralized MADRL with communication and evaluate them on multiple tasks in the StarCraft Multi-Agent Challenge and Traffic Junction domains. The results show that decentralized MADRL communication methods extended with our proposed techniques not only achieve high-performing agents but also reduce variance in policy gradients during training.
SHARPIE: A Modular Framework for Reinforcement Learning and Human-AI Interaction Experiments
Jan 31, 2025


Reinforcement learning (RL) offers a general approach for modeling and training AI agents, including human-AI interaction scenarios. In this paper, we propose SHARPIE (Shared Human-AI Reinforcement Learning Platform for Interactive Experiments) to address the need for a generic framework to support experiments with RL agents and humans. Its modular design consists of a versatile wrapper for RL environments and algorithm libraries, a participant-facing web interface, logging utilities, deployment on popular cloud and participant recruitment platforms. It empowers researchers to study a wide variety of research questions related to the interaction between humans and RL agents, including those related to interactive reward specification and learning, learning from human feedback, action delegation, preference elicitation, user-modeling, and human-AI teaming. The platform is based on a generic interface for human-RL interactions that aims to standardize the field of study on RL in human contexts.
Non-Progressive Influence Maximization in Dynamic Social Networks
Dec 10, 2024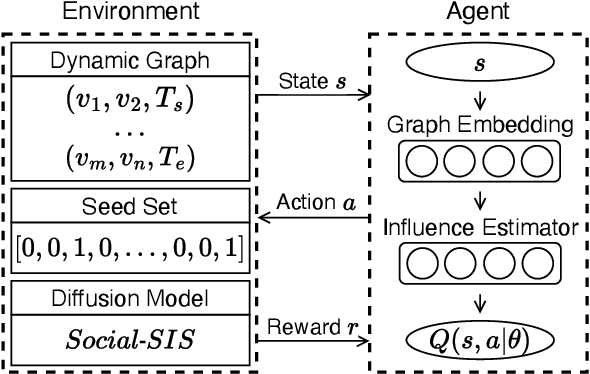



The influence maximization (IM) problem involves identifying a set of key individuals in a social network who can maximize the spread of influence through their network connections. With the advent of geometric deep learning on graphs, great progress has been made towards better solutions for the IM problem. In this paper, we focus on the dynamic non-progressive IM problem, which considers the dynamic nature of real-world social networks and the special case where the influence diffusion is non-progressive, i.e., nodes can be activated multiple times. We first extend an existing diffusion model to capture the non-progressive influence propagation in dynamic social networks. We then propose the method, DNIMRL, which employs deep reinforcement learning and dynamic graph embedding to solve the dynamic non-progressive IM problem. In particular, we propose a novel algorithm that effectively leverages graph embedding to capture the temporal changes of dynamic networks and seamlessly integrates with deep reinforcement learning. The experiments, on different types of real-world social network datasets, demonstrate that our method outperforms state-of-the-art baselines.
Balancing the Scales: Reinforcement Learning for Fair Classification
Jul 15, 2024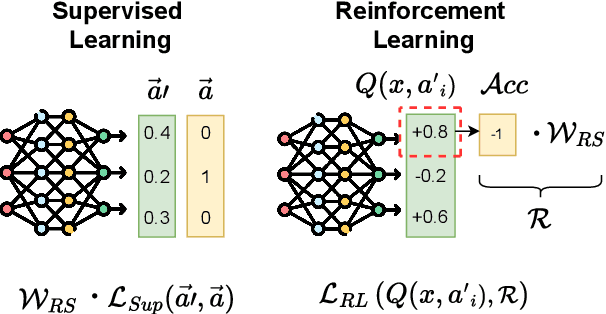
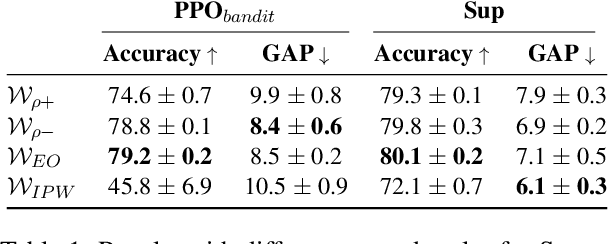
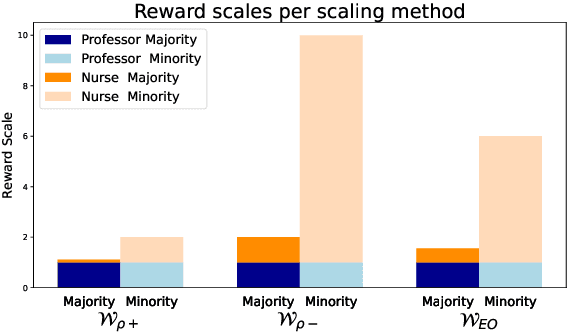
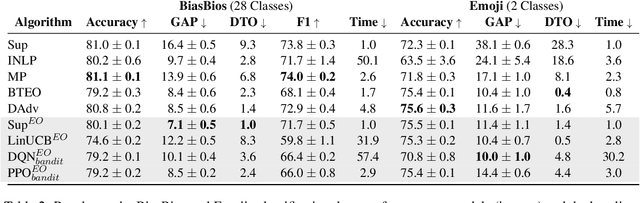
Fairness in classification tasks has traditionally focused on bias removal from neural representations, but recent trends favor algorithmic methods that embed fairness into the training process. These methods steer models towards fair performance, preventing potential elimination of valuable information that arises from representation manipulation. Reinforcement Learning (RL), with its capacity for learning through interaction and adjusting reward functions to encourage desired behaviors, emerges as a promising tool in this domain. In this paper, we explore the usage of RL to address bias in imbalanced classification by scaling the reward function to mitigate bias. We employ the contextual multi-armed bandit framework and adapt three popular RL algorithms to suit our objectives, demonstrating a novel approach to mitigating bias.
Knowledge acquisition for dialogue agents using reinforcement learning on graph representations
Jun 27, 2024We develop an artificial agent motivated to augment its knowledge base beyond its initial training. The agent actively participates in dialogues with other agents, strategically acquiring new information. The agent models its knowledge as an RDF knowledge graph, integrating new beliefs acquired through conversation. Responses in dialogue are generated by identifying graph patterns around these new integrated beliefs. We show that policies can be learned using reinforcement learning to select effective graph patterns during an interaction, without relying on explicit user feedback. Within this context, our study is a proof of concept for leveraging users as effective sources of information.
Sample Efficient Reinforcement Learning by Automatically Learning to Compose Subtasks
Jan 25, 2024Improving sample efficiency is central to Reinforcement Learning (RL), especially in environments where the rewards are sparse. Some recent approaches have proposed to specify reward functions as manually designed or learned reward structures whose integrations in the RL algorithms are claimed to significantly improve the learning efficiency. Manually designed reward structures can suffer from inaccuracy and existing automatically learning methods are often computationally intractable for complex tasks. The integration of inaccurate or partial reward structures in RL algorithms fail to learn optimal policies. In this work, we propose an RL algorithm that can automatically structure the reward function for sample efficiency, given a set of labels that signify subtasks. Given such minimal knowledge about the task, we train a high-level policy that selects optimal sub-tasks in each state together with a low-level policy that efficiently learns to complete each sub-task. We evaluate our algorithm in a variety of sparse-reward environments. The experiment results show that our approach significantly outperforms the state-of-art baselines as the difficulty of the task increases.