 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushdown Reward Machines for Reinforcement Learning
Aug 09, 2025Reward machines (RMs) are automata structures that encode (non-Markovian) reward functions for reinforcement learning (RL). RMs can reward any behaviour representable in regular languages and, when paired with RL algorithms that exploit RM structure, have been shown to significantly improve sample efficiency in many domains. In this work, we present pushdown reward machines (pdRMs), an extension of reward machines based on deterministic pushdown automata. pdRMs can recognize and reward temporally extended behaviours representable in deterministic context-free languages, making them more expressive than reward machines. We introduce two variants of pdRM-based policies, one which has access to the entire stack of the pdRM, and one which can only access the top $k$ symbols (for a given constant $k$) of the stack. We propose a procedure to check when the two kinds of policies (for a given environment, pdRM, and constant $k$) achieve the same optimal expected reward. We then provide theoretical results establishing the expressive power of pdRMs, and space complexity results about the proposed learning problems. Finally, we provide experimental results showing how agents can be trained to perform tasks representable in deterministic context-free languages using pdRMs.
Credit Assignment and Efficient Exploration based on Influence Scope in Multi-agent Reinforcement Learning
May 13, 2025Training cooperative agents in sparse-reward scenarios poses significant challenges for multi-agent reinforcement learning (MARL). Without clear feedback on actions at each step in sparse-reward setting, previous methods struggle with precise credit assignment among agents and effective exploration. In this paper, we introduce a novel method to deal with both credit assignment and exploration problems in reward-sparse domains. Accordingly, we propose an algorithm that calculates the Influence Scope of Agents (ISA) on states by taking specific value of the dimensions/attributes of states that can be influenced by individual agents. The mutual dependence between agents' actions and state attributes are then used to calculate the credit assignment and to delimit the exploration space for each individual agent. We then evaluate ISA in a variety of sparse-reward multi-agent scenarios. The results show that our method significantly outperforms the state-of-art baselines.
Causes and Strategies in Multiagent Systems
Feb 19, 2025


Causality plays an important role in daily processes, human reasoning, and artificial intelligence. There has however not been much research on causality in multi-agent strategic settings. In this work, we introduce a systematic way to build a multi-agent system model, represented as a concurrent game structure, for a given structural causal model. In the obtained so-called causal concurrent game structure, transitions correspond to interventions on agent variables of the given causal model. The Halpern and Pearl framework of causality is used to determine the effects of a certain value for an agent variable on other variables. The causal concurrent game structure allows us to analyse and reason about causal effects of agents' strategic decisions. We formally investigate the relation between causal concurrent game structures and the original structural causal models.
The Minimal Search Space for Conditional Causal Bandits
Feb 10, 2025Causal knowledge can be used to support decision-making problems. This has been recognized in the causal bandits literature, where a causal (multi-armed) bandit is characterized by a causal graphical model and a target variable. The arms are then interventions on the causal model, and rewards are samples of the target variable. Causal bandits were originally studied with a focus on hard interventions. We focus instead on cases where the arms are conditional interventions, which more accurately model many real-world decision-making problems by allowing the value of the intervened variable to be chosen based on the observed values of other variables. This paper presents a graphical characterization of the minimal set of nodes guaranteed to contain the optimal conditional intervention, which maximizes the expected reward. We then propose an efficient algorithm with a time complexity of $O(|V| + |E|)$ to identify this minimal set of nodes. We prove that the graphical characterization and the proposed algorithm are correct. Finally, we empirically demonstrate that our algorithm significantly prunes the search space and substantially accelerates convergence rates when integrated into standard multi-armed bandit algorithms.
Reducing Variance Caused by Communication in Decentralized Multi-agent Deep Reinforcement Learning
Feb 10, 2025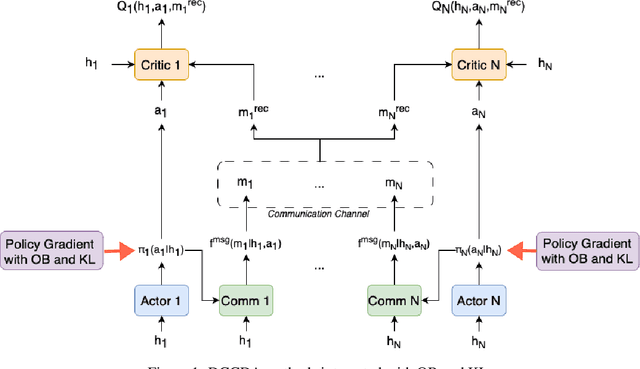
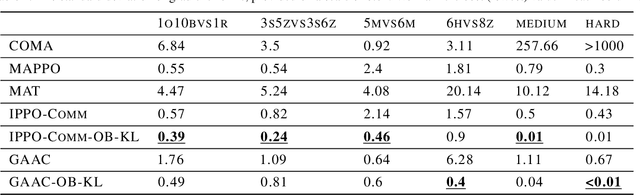
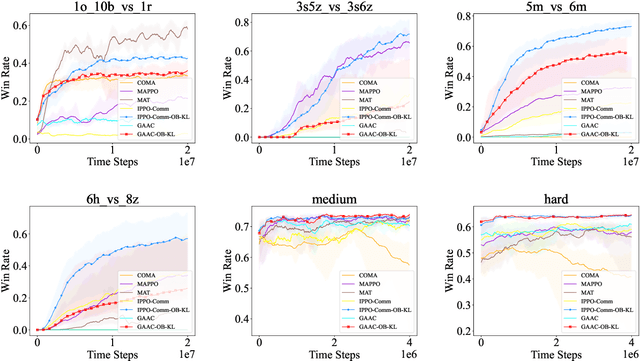

In decentralized multi-agent deep reinforcement learning (MADRL), communication can help agents to gain a better understanding of the environment to better coordinate their behaviors. Nevertheless, communication may involve uncertainty, which potentially introduces variance to the learning of decentralized agents. In this paper, we focus on a specific decentralized MADRL setting with communication and conduct a theoretical analysis to study the variance that is caused by communication in policy gradients. We propose modular techniques to reduce the variance in policy gradients during training. We adopt our modular techniques into two existing algorithms for decentralized MADRL with communication and evaluate them on multiple tasks in the StarCraft Multi-Agent Challenge and Traffic Junction domains. The results show that decentralized MADRL communication methods extended with our proposed techniques not only achieve high-performing agents but also reduce variance in policy gradients during training.
Temporal Causal Reasoning with (Non-Recursive) Structural Equation Models
Jan 17, 2025



Structural Equation Models (SEM) are the standard approach to representing causal dependencies between variables in causal models. In this paper we propose a new interpretation of SEMs when reasoning about Actual Causality, in which SEMs are viewed as mechanisms transforming the dynamics of exogenous variables into the dynamics of endogenous variables. This allows us to combine counterfactual causal reasoning with existing temporal logic formalisms, and to introduce a temporal logic, CPLTL, for causal reasoning about such structures. We show that the standard restriction to so-called \textit{recursive} models (with no cycles in the dependency graph) is not necessary in our approach, allowing us to reason about mutually dependent processes and feedback loops. Finally, we introduce new notions of model equivalence for temporal causal models, and show that CPLTL has an efficient model-checking procedure.
Optimal Causal Representations and the Causal Information Bottleneck
Oct 02, 2024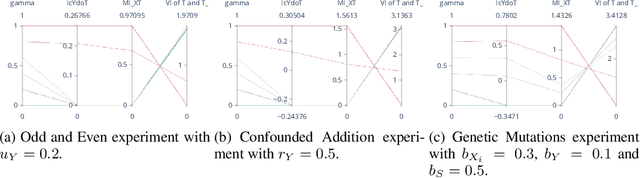



To effectively study complex causal systems, it is often useful to construct representations that simplify parts of the system by discarding irrelevant details while preserving key features. The Information Bottleneck (IB) method is a widely used approach in representation learning that compresses random variables while retaining information about a target variable. Traditional methods like IB are purely statistical and ignore underlying causal structures, making them ill-suited for causal tasks. We propose the Causal Information Bottleneck (CIB), a causal extension of the IB, which compresses a set of chosen variables while maintaining causal control over a target variable. This method produces representations which are causally interpretable, and which can be used when reasoning about interventions. We present experimental results demonstrating that the learned representations accurately capture causality as intended.
Maximally Permissive Reward Machines
Aug 15, 2024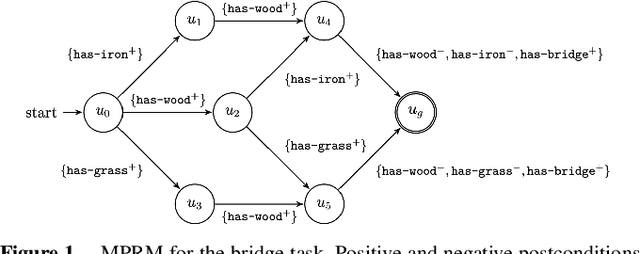
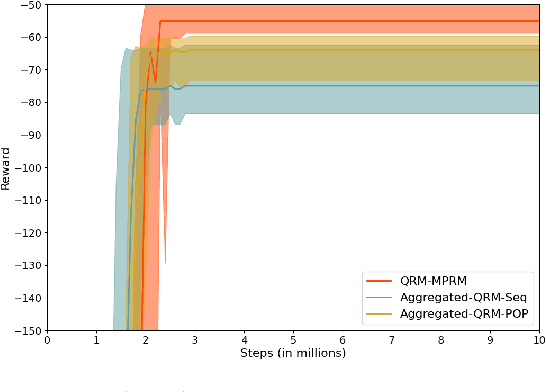
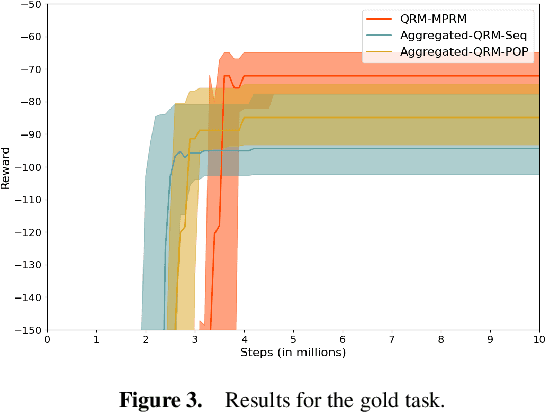
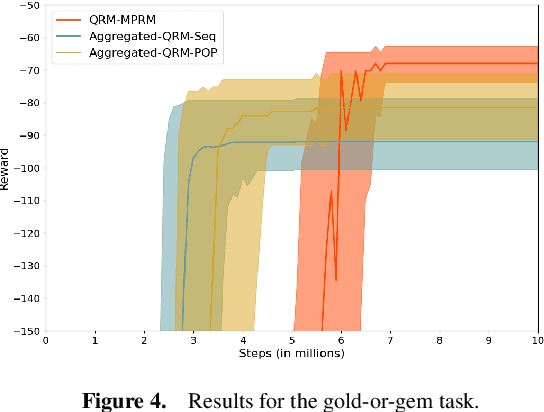
Reward machines allow the definition of rewards for temporally extended tasks and behaviors. Specifying "informative" reward machines can be challenging. One way to address this is to generate reward machines from a high-level abstract description of the learning environment, using techniques such as AI planning. However, previous planning-based approaches generate a reward machine based on a single (sequential or partial-order) plan, and do not allow maximum flexibility to the learning agent. In this paper we propose a new approach to synthesising reward machines which is based on the set of partial order plans for a goal. We prove that learning using such "maximally permissive" reward machines results in higher rewards than learning using RMs based on a single plan. We present experimental results which support our theoretical claims by showing that our approach obtains higher rewards than the single-plan approach in practice.
Cooperative Multi-agent Approach for Automated Computer Game Testing
May 18, 2024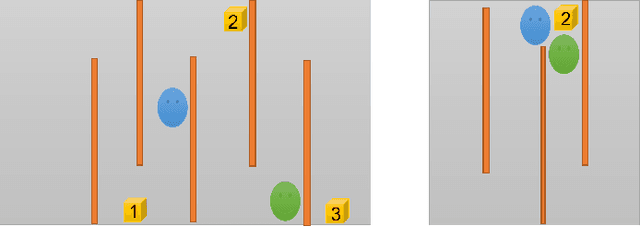



Automated testing of computer games is a challenging problem, especially when lengthy scenarios have to be tested. Automating such a scenario boils down to finding the right sequence of interactions given an abstract description of the scenario. Recent works have shown that an agent-based approach works well for the purpose, e.g. due to agents' reactivity, hence enabling a test agent to immediately react to game events and changing state. Many games nowadays are multi-player. This opens up an interesting possibility to deploy multiple cooperative test agents to test such a game, for example to speed up the execution of multiple testing tasks. This paper offers a cooperative multi-agent testing approach and a study of its performance based on a case study on a 3D game called Lab Recruits.
Fundamental Properties of Causal Entropy and Information Gain
Feb 02, 2024
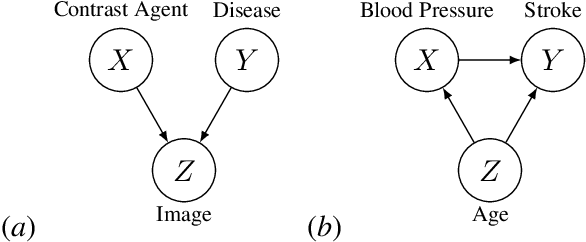
Recent developments enable the quantification of causal control given a structural causal model (SCM). This has been accomplished by introducing quantities which encode changes in the entropy of one variable when intervening on another. These measures, named causal entropy and causal information gain, aim to address limitations in existing information theoretical approaches for machine learning tasks where causality plays a crucial role. They have not yet been properly mathematically studied. Our research contributes to the formal understanding of the notions of causal entropy and causal information gain by establishing and analyzing fundamental properties of these concepts, including bounds and chain rules. Furthermore, we elucidate the relationship between causal entropy and stochastic interventions. We also propose definitions for causal conditional entropy and causal conditional information gain. Overall, this exploration paves the way for enhancing causal machine learning tasks through the study of recently-proposed information theoretic quantities grounded in considerations about causality.