 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Variance Caused by Communication in Decentralized Multi-agent Deep Reinforcement Learning
Feb 10, 2025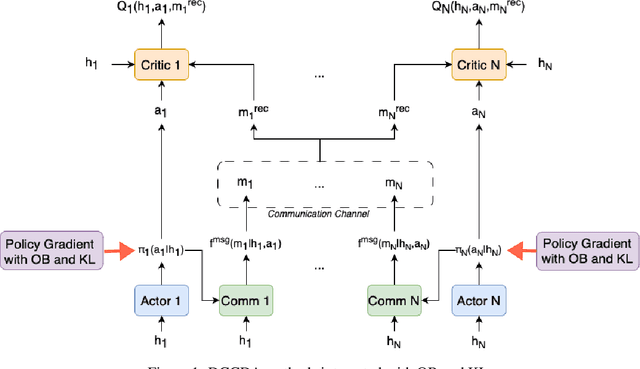
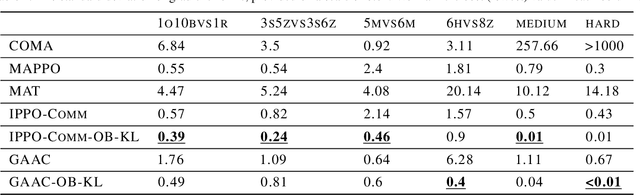
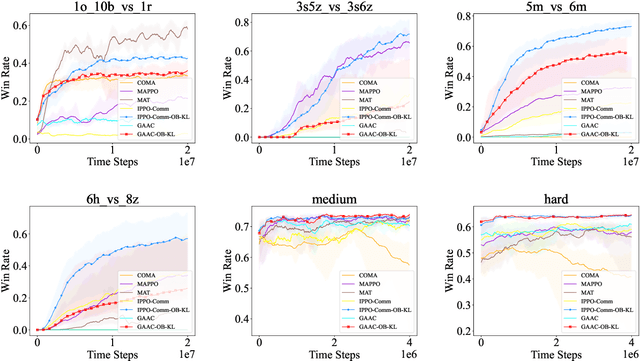

In decentralized multi-agent deep reinforcement learning (MADRL), communication can help agents to gain a better understanding of the environment to better coordinate their behaviors. Nevertheless, communication may involve uncertainty, which potentially introduces variance to the learning of decentralized agents. In this paper, we focus on a specific decentralized MADRL setting with communication and conduct a theoretical analysis to study the variance that is caused by communication in policy gradients. We propose modular techniques to reduce the variance in policy gradients during training. We adopt our modular techniques into two existing algorithms for decentralized MADRL with communication and evaluate them on multiple tasks in the StarCraft Multi-Agent Challenge and Traffic Junction domains. The results show that decentralized MADRL communication methods extended with our proposed techniques not only achieve high-performing agents but also reduce variance in policy gradients during training.
A Survey of Multi-Agent Reinforcement Learning with Communication
Mar 16, 2022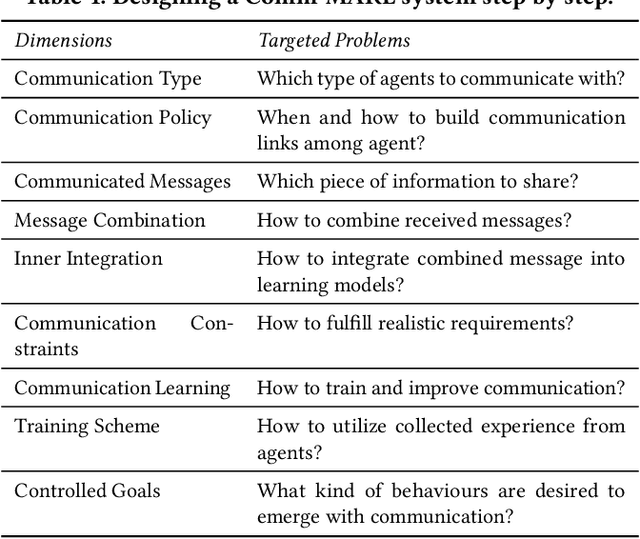
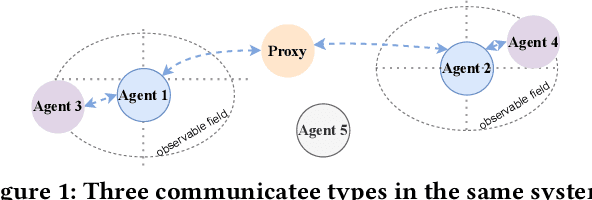

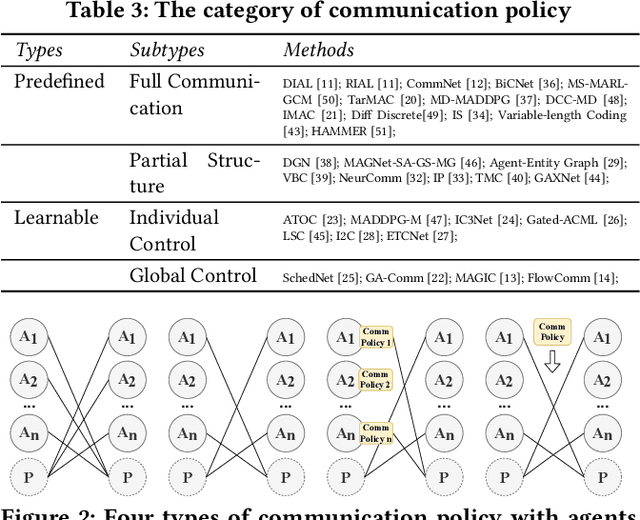
Communication is an effective mechanism for coordinating the behavior of multiple agents. In the field of multi-agent reinforcement learning, agents can improve the overall learning performance and achieve their objectives by communication. Moreover, agents can communicate various types of messages, either to all agents or to specific agent groups, and through specific channels. With the growing body of research work in MARL with communication (Comm-MARL), there is lack of a systematic and structural approach to distinguish and classify existing Comm-MARL systems. In this paper, we survey recent works in the Comm-MARL field and consider various aspects of communication that can play a role in the design and development of multi-agent reinforcement learning systems. With these aspects in mind, we propose several dimensions along which Comm-MARL systems can be analyzed, developed, and compared.