 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushdown Reward Machines for Reinforcement Learning
Aug 09, 2025Reward machines (RMs) are automata structures that encode (non-Markovian) reward functions for reinforcement learning (RL). RMs can reward any behaviour representable in regular languages and, when paired with RL algorithms that exploit RM structure, have been shown to significantly improve sample efficiency in many domains. In this work, we present pushdown reward machines (pdRMs), an extension of reward machines based on deterministic pushdown automata. pdRMs can recognize and reward temporally extended behaviours representable in deterministic context-free languages, making them more expressive than reward machines. We introduce two variants of pdRM-based policies, one which has access to the entire stack of the pdRM, and one which can only access the top $k$ symbols (for a given constant $k$) of the stack. We propose a procedure to check when the two kinds of policies (for a given environment, pdRM, and constant $k$) achieve the same optimal expected reward. We then provide theoretical results establishing the expressive power of pdRMs, and space complexity results about the proposed learning problems. Finally, we provide experimental results showing how agents can be trained to perform tasks representable in deterministic context-free languages using pdRMs.
Maximally Permissive Reward Machines
Aug 15, 2024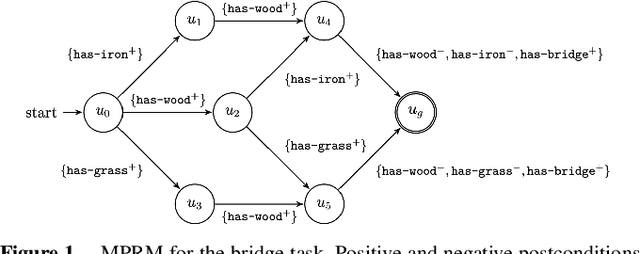
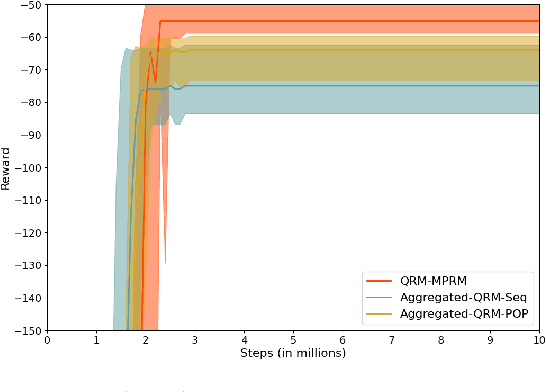
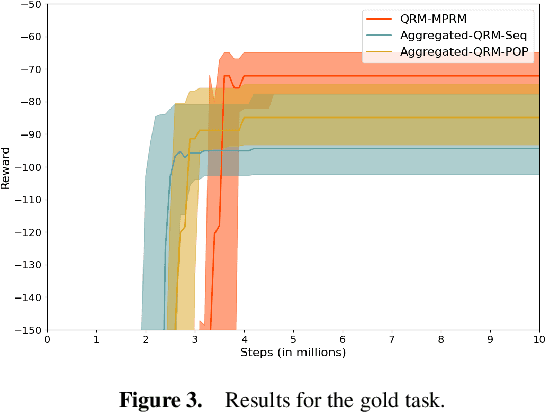
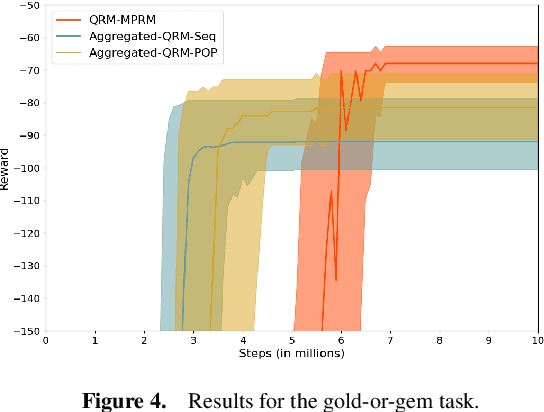
Reward machines allow the definition of rewards for temporally extended tasks and behaviors. Specifying "informative" reward machines can be challenging. One way to address this is to generate reward machines from a high-level abstract description of the learning environment, using techniques such as AI planning. However, previous planning-based approaches generate a reward machine based on a single (sequential or partial-order) plan, and do not allow maximum flexibility to the learning agent. In this paper we propose a new approach to synthesising reward machines which is based on the set of partial order plans for a goal. We prove that learning using such "maximally permissive" reward machines results in higher rewards than learning using RMs based on a single plan. We present experimental results which support our theoretical claims by showing that our approach obtains higher rewards than the single-plan approach in practice.