 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushdown Reward Machines for Reinforcement Learning
Aug 09, 2025



Reward machines (RMs) are automata structures that encode (non-Markovian) reward functions for reinforcement learning (RL). RMs can reward any behaviour representable in regular languages and, when paired with RL algorithms that exploit RM structure, have been shown to significantly improve sample efficiency in many domains. In this work, we present pushdown reward machines (pdRMs), an extension of reward machines based on deterministic pushdown automata. pdRMs can recognize and reward temporally extended behaviours representable in deterministic context-free languages, making them more expressive than reward machines. We introduce two variants of pdRM-based policies, one which has access to the entire stack of the pdRM, and one which can only access the top $k$ symbols (for a given constant $k$) of the stack. We propose a procedure to check when the two kinds of policies (for a given environment, pdRM, and constant $k$) achieve the same optimal expected reward. We then provide theoretical results establishing the expressive power of pdRMs, and space complexity results about the proposed learning problems. Finally, we provide experimental results showing how agents can be trained to perform tasks representable in deterministic context-free languages using pdRMs.
Causes and Strategies in Multiagent Systems
Feb 19, 2025


Causality plays an important role in daily processes, human reasoning, and artificial intelligence. There has however not been much research on causality in multi-agent strategic settings. In this work, we introduce a systematic way to build a multi-agent system model, represented as a concurrent game structure, for a given structural causal model. In the obtained so-called causal concurrent game structure, transitions correspond to interventions on agent variables of the given causal model. The Halpern and Pearl framework of causality is used to determine the effects of a certain value for an agent variable on other variables. The causal concurrent game structure allows us to analyse and reason about causal effects of agents' strategic decisions. We formally investigate the relation between causal concurrent game structures and the original structural causal models.
Temporal Causal Reasoning with (Non-Recursive) Structural Equation Models
Jan 17, 2025



Structural Equation Models (SEM) are the standard approach to representing causal dependencies between variables in causal models. In this paper we propose a new interpretation of SEMs when reasoning about Actual Causality, in which SEMs are viewed as mechanisms transforming the dynamics of exogenous variables into the dynamics of endogenous variables. This allows us to combine counterfactual causal reasoning with existing temporal logic formalisms, and to introduce a temporal logic, CPLTL, for causal reasoning about such structures. We show that the standard restriction to so-called \textit{recursive} models (with no cycles in the dependency graph) is not necessary in our approach, allowing us to reason about mutually dependent processes and feedback loops. Finally, we introduce new notions of model equivalence for temporal causal models, and show that CPLTL has an efficient model-checking procedure.
Probabilistic Strategy Logic with Degrees of Observability
Dec 19, 2024
There has been considerable work on reasoning about the strategic ability of agents under imperfect information. However, existing logics such as Probabilistic Strategy Logic are unable to express properties relating to information transparency. Information transparency concerns the extent to which agents' actions and behaviours are observable by other agents. Reasoning about information transparency is useful in many domains including security, privacy, and decision-making. In this paper, we present a formal framework for reasoning about information transparency properties in stochastic multi-agent systems. We extend Probabilistic Strategy Logic with new observability operators that capture the degree of observability of temporal properties by agents. We show that the model checking problem for the resulting logic is decidable.
Maximally Permissive Reward Machines
Aug 15, 2024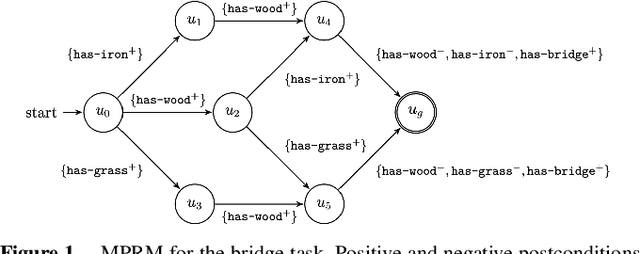
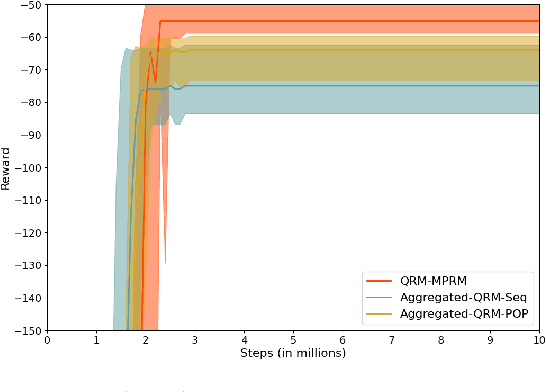
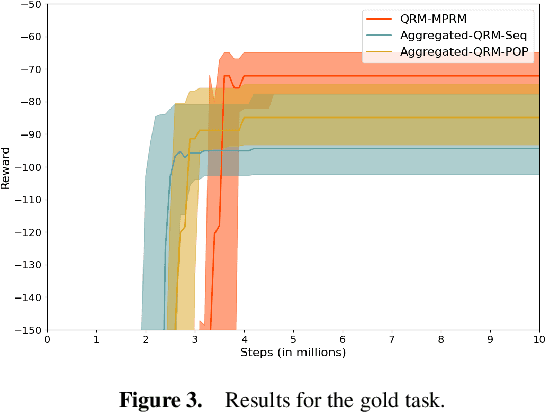
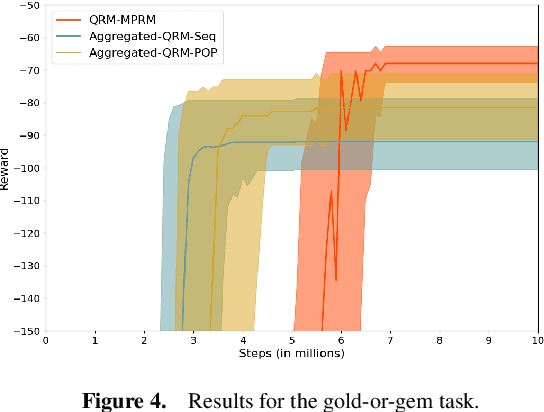
Reward machines allow the definition of rewards for temporally extended tasks and behaviors. Specifying "informative" reward machines can be challenging. One way to address this is to generate reward machines from a high-level abstract description of the learning environment, using techniques such as AI planning. However, previous planning-based approaches generate a reward machine based on a single (sequential or partial-order) plan, and do not allow maximum flexibility to the learning agent. In this paper we propose a new approach to synthesising reward machines which is based on the set of partial order plans for a goal. We prove that learning using such "maximally permissive" reward machines results in higher rewards than learning using RMs based on a single plan. We present experimental results which support our theoretical claims by showing that our approach obtains higher rewards than the single-plan approach in practice.
The Complexity of Data-Driven Norm Synthesis and Revision
Dec 05, 2021Norms have been widely proposed as a way of coordinating and controlling the activities of agents in a multi-agent system (MAS). A norm specifies the behaviour an agent should follow in order to achieve the objective of the MAS. However, designing norms to achieve a particular system objective can be difficult, particularly when there is no direct link between the language in which the system objective is stated and the language in which the norms can be expressed. In this paper, we consider the problem of synthesising a norm from traces of agent behaviour, where each trace is labelled with whether the behaviour satisfies the system objective. We show that the norm synthesis problem is NP-complete.
Causality, Responsibility and Blame in Team Plans
May 20, 2020Many objectives can be achieved (or may be achieved more effectively) only by a group of agents executing a team plan. If a team plan fails, it is often of interest to determine what caused the failure, the degree of responsibility of each agent for the failure, and the degree of blame attached to each agent. We show how team plans can be represented in terms of structural equations, and then apply the definitions of causality introduced by Halpern [2015] and degree of responsibility and blame introduced by Chockler and Halpern [2004] to determine the agent(s) who caused the failure and what their degree of responsibility/blame is. We also prove new results on the complexity of computing causality and degree of responsibility and blame, showing that they can be determined in polynomial time for many team plans of interest.
Expressibility of norms in temporal logic
Aug 24, 2016In this short note we address the issue of expressing norms (such as obligations and prohibitions) in temporal logic. In particular, we address the argument from [Governatori 2015] that norms cannot be expressed in Linear Time Temporal Logic (LTL).