 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Self-Sustainable Information-Bearing RIS in Underlay CR-NOMA Networks
Mar 22, 2026Information-bearing reconfigurable intelligent surfaces (IB-RIS) provide a promising solution to self-sustainable and green communications by harvesting ambient radio frequency energy while embedding information via passive reflection. This paper investigates a self-sustainable IB-RIS (SIB-RIS)-assisted non-orthogonal multiple access (NOMA) network operating in an underlay cognitive radio (CR) system. Specifically, a multi-antenna primary transmitter (PT) serves a primary user (PU) and concurrently illuminates the secondary nodes, which enables each SIB-RIS to perform simultaneous energy harvesting and backscatter-based information embedding at each RIS. Based on this model, a weighted sum spectral efficiency (WSSE) maximization problem is formulated for the secondary network by jointly optimizing the PT transmit beamforming vector, the SIB-RIS reflection coefficients, and the power-splitting ratios. To tackle the intricately-coupled non-convex problem, an efficient block coordinate descent (BCD) optimization framework is developed, which leverages fractional programming via Lagrangian dual and quadratic transforms together with a difference-of-convex programming approach. Numerical results demonstrate that the proposed SIB-RIS-assisted NOMA CR system yields substantial WSSE gains over both orthogonal multiple access (OMA)-based and active antenna schemes. Moreover, a 2-bit discrete-phase SIB-RIS implementation achieves competitive to which WSSE performance, confirming the practicality of the low-resolution architecture.
Neuro-symbolic Action Masking for Deep Reinforcement Learning
Feb 11, 2026Deep reinforcement learning (DRL) may explore infeasible actions during training and execution. Existing approaches assume a symbol grounding function that maps high-dimensional states to consistent symbolic representations and a manually specified action masking techniques to constrain actions. In this paper, we propose Neuro-symbolic Action Masking (NSAM), a novel framework that automatically learn symbolic models, which are consistent with given domain constraints of high-dimensional states, in a minimally supervised manner during the DRL process. Based on the learned symbolic model of states, NSAM learns action masks that rules out infeasible actions. NSAM enables end-to-end integration of symbolic reasoning and deep policy optimization, where improvements in symbolic grounding and policy learning mutually reinforce each other. We evaluate NSAM on multiple domains with constraints, and experimental results demonstrate that NSAM significantly improves sample efficiency of DRL agent while substantially reducing constraint violations.
Pinching-Antenna-Enabled Cognitive Radio Networks
Nov 17, 2025This paper investigates a pinching-antenna (PA)-enabled cognitive radio network, where both the primary transmitter (PT) and secondary transmitter (ST) are equipped with a single waveguide and multiple PAs to facilitate simultaneous spectrum sharing. Under a general Ricean fading channel model, a closed-form analytical expression for the average spectral efficiency (SE) achieved by PAs is first derived. Based on this, a sum-SE maximization problem is formulated to jointly optimize the primary and secondary pinching beamforming, subject to system constraints on the transmission power budgets, minimum antenna separation requirements, and feasible PA deployment regions. To address this non-convex problem, a three-stage optimization algorithm is developed to sequentially optimize both the PT and ST pinching beamforming, and the ST power control. For the PT and ST pinching beamforming optimization, the coarse positions of PA are first determined at the waveguide-level. Then, wavelength-level refinements achieve constructive signal combination at the intended user and destructive superposition at the unintended user. For the ST power control, a closed-form solution is derived. Simulation results demonstrate that i) PAs can achieve significant SE improvements over conventional fixed-position antennas; ii) the proposed pinching beamforming design achieves effective interference suppression and superior performance for both even and odd numbers of PAs; and iii) the developed three-stage optimization algorithm enables nearly orthogonal transmission between the primary and secondary networks.
Joint Antenna Positioning and Beamforming for Movable Antenna Array Aided Ground Station in Low-Earth Orbit Satellite Communication
Sep 09, 2025

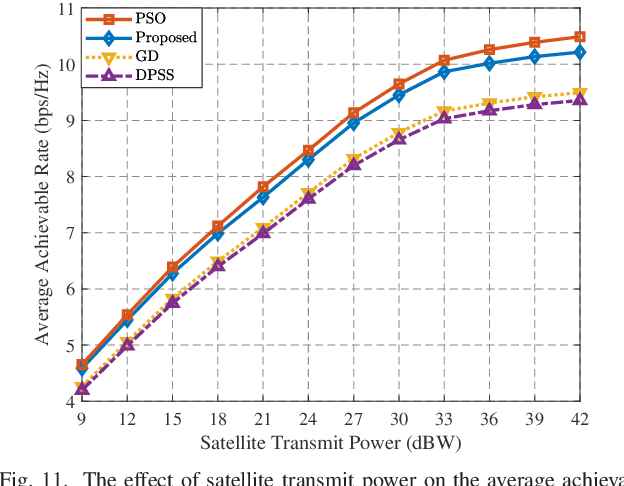

This paper proposes a new architecture for the low-earth orbit (LEO) satellite ground station aided by movable antenna (MA) array. Unlike conventional fixed-position antenna (FPA), the MA array can flexibly adjust antenna positions to reconfigure array geometry, for more effectively mitigating interference and improving communication performance in ultra-dense LEO satellite networks. To reduce movement overhead, we configure antenna positions at the antenna initialization stage, which remain unchanged during the whole communication period of the ground station. To this end, an optimization problem is formulated to maximize the average achievable rate of the ground station by jointly optimizing its antenna position vector (APV) and time-varying beamforming weights, i.e., antenna weight vectors (AWVs). To solve the resulting non-convex optimization problem, we adopt the Lagrangian dual transformation and quadratic transformation to reformulate the objective function into a more tractable form. Then, we develop an efficient block coordinate descent-based iterative algorithm that alternately optimizes the APV and AWVs until convergence is reached. Simulation results demonstrate that our proposed MA scheme significantly outperforms traditional FPA by increasing the achievable rate at ground stations under various system setups, thus providing an efficient solution for interference mitigation in future ultra-dense LEO satellite communication networks.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025
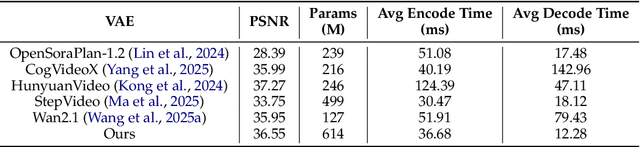
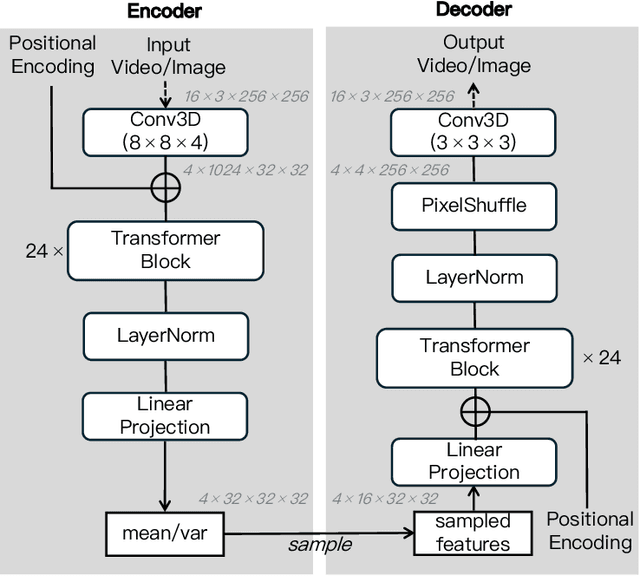
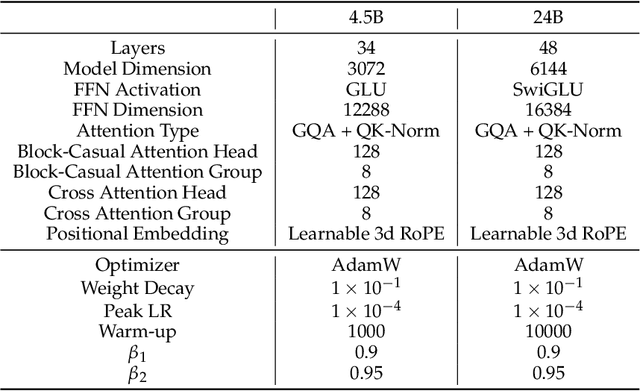
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Credit Assignment and Efficient Exploration based on Influence Scope in Multi-agent Reinforcement Learning
May 13, 2025



Training cooperative agents in sparse-reward scenarios poses significant challenges for multi-agent reinforcement learning (MARL). Without clear feedback on actions at each step in sparse-reward setting, previous methods struggle with precise credit assignment among agents and effective exploration. In this paper, we introduce a novel method to deal with both credit assignment and exploration problems in reward-sparse domains. Accordingly, we propose an algorithm that calculates the Influence Scope of Agents (ISA) on states by taking specific value of the dimensions/attributes of states that can be influenced by individual agents. The mutual dependence between agents' actions and state attributes are then used to calculate the credit assignment and to delimit the exploration space for each individual agent. We then evaluate ISA in a variety of sparse-reward multi-agent scenarios. The results show that our method significantly outperforms the state-of-art baselines.
Unifying Physics- and Data-Driven Modeling via Novel Causal Spatiotemporal Graph Neural Network for Interpretable Epidemic Forecasting
Apr 07, 2025



Accurate epidemic forecasting is crucial for effective disease control and prevention. Traditional compartmental models often struggle to estimate temporally and spatially varying epidemiological parameters, while deep learning models typically overlook disease transmission dynamics and lack interpretability in the epidemiological context. To address these limitations, we propose a novel Causal Spatiotemporal Graph Neural Network (CSTGNN), a hybrid framework that integrates a Spatio-Contact SIR model with Graph Neural Networks (GNNs) to capture the spatiotemporal propagation of epidemics. Inter-regional human mobility exhibits continuous and smooth spatiotemporal patterns, leading to adjacent graph structures that share underlying mobility dynamics. To model these dynamics, we employ an adaptive static connectivity graph to represent the stable components of human mobility and utilize a temporal dynamics model to capture fluctuations within these patterns. By integrating the adaptive static connectivity graph with the temporal dynamics graph, we construct a dynamic graph that encapsulates the comprehensive properties of human mobility networks. Additionally, to capture temporal trends and variations in infectious disease spread, we introduce a temporal decomposition model to handle temporal dependence. This model is then integrated with a dynamic graph convolutional network for epidemic forecasting. We validate our model using real-world datasets at the provincial level in China and the state level in Germany. Extensive studies demonstrate that our method effectively models the spatiotemporal dynamics of infectious diseases, providing a valuable tool for forecasting and intervention strategies. Furthermore, analysis of the learned parameters offers insights into disease transmission mechanisms, enhancing the interpretability and practical applicability of our model.
Sample Efficient Reinforcement Learning by Automatically Learning to Compose Subtasks
Jan 25, 2024Improving sample efficiency is central to Reinforcement Learning (RL), especially in environments where the rewards are sparse. Some recent approaches have proposed to specify reward functions as manually designed or learned reward structures whose integrations in the RL algorithms are claimed to significantly improve the learning efficiency. Manually designed reward structures can suffer from inaccuracy and existing automatically learning methods are often computationally intractable for complex tasks. The integration of inaccurate or partial reward structures in RL algorithms fail to learn optimal policies. In this work, we propose an RL algorithm that can automatically structure the reward function for sample efficiency, given a set of labels that signify subtasks. Given such minimal knowledge about the task, we train a high-level policy that selects optimal sub-tasks in each state together with a low-level policy that efficiently learns to complete each sub-task. We evaluate our algorithm in a variety of sparse-reward environments. The experiment results show that our approach significantly outperforms the state-of-art baselines as the difficulty of the task increases.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Approaching epidemiological dynamics of COVID-19 with physics-informed neural networks
Feb 20, 2023



A physics-informed neural network (PINN) embedded with the susceptible-infected-removed (SIR) model is devised to understand the temporal evolution dynamics of infectious diseases. Firstly, the effectiveness of this approach is demonstrated on synthetic data as generated from the numerical solution of the susceptible-asymptomatic-infected-recovered-dead (SAIRD) model. Then, the method is applied to COVID-19 data reported for Germany and shows that it can accurately identify and predict virus spread trends. The results indicate that an incomplete physics-informed model can approach more complicated dynamics efficiently. Thus, the present work demonstrates the high potential of using machine learning methods, e.g., PINNs, to study and predict epidemic dynamics in combination with compartmental models.