 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
Mar 23, 2026We present daVinci-MagiHuman, an open-source audio-video generative foundation model for human-centric generation. daVinci-MagiHuman jointly generates synchronized video and audio using a single-stream Transformer that processes text, video, and audio within a unified token sequence via self-attention only. This single-stream design avoids the complexity of multi-stream or cross-attention architectures while remaining easy to optimize with standard training and inference infrastructure. The model is particularly strong in human-centric scenarios, producing expressive facial performance, natural speech-expression coordination, realistic body motion, and precise audio-video synchronization. It supports multilingual spoken generation across Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, and French. For efficient inference, we combine the single-stream backbone with model distillation, latent-space super-resolution, and a Turbo VAE decoder, enabling generation of a 5-second 256p video in 2 seconds on a single H100 GPU. In automatic evaluation, daVinci-MagiHuman achieves the highest visual quality and text alignment among leading open models, along with the lowest word error rate (14.60%) for speech intelligibility. In pairwise human evaluation, it achieves win rates of 80.0% against Ovi 1.1 and 60.9% against LTX 2.3 over 2000 comparisons. We open-source the complete model stack, including the base model, the distilled model, the super-resolution model, and the inference codebase.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025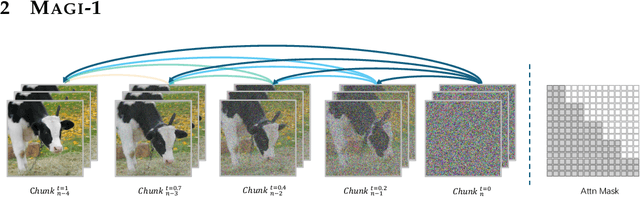
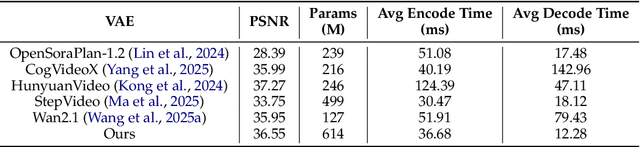
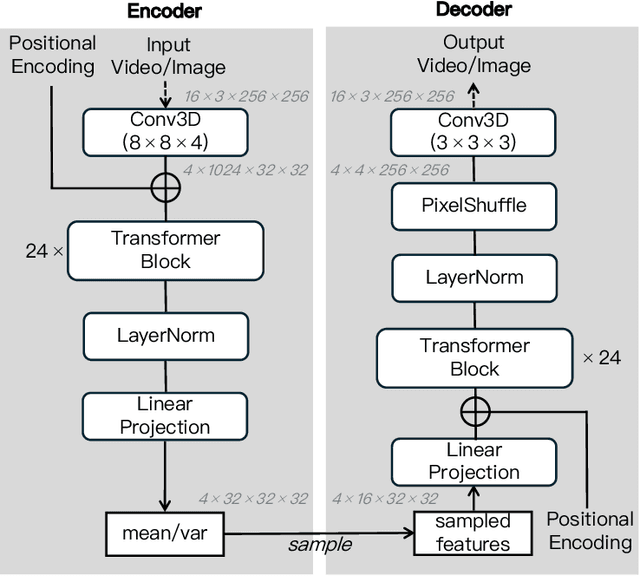
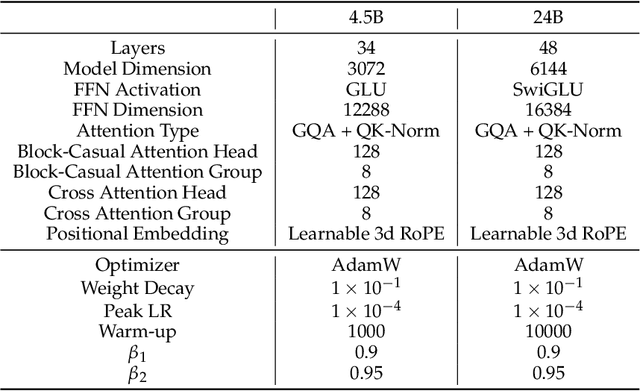
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Fast Information Streaming Handler (FisH): A Unified Seismic Neural Network for Single Station Real-Time Earthquake Early Warning
Aug 13, 2024



Existing EEW approaches often treat phase picking, location estimation, and magnitude estimation as separate tasks, lacking a unified framework. Additionally, most deep learning models in seismology rely on full three-component waveforms and are not suitable for real-time streaming data. To address these limitations, we propose a novel unified seismic neural network called Fast Information Streaming Handler (FisH). FisH is designed to process real-time streaming seismic data and generate simultaneous results for phase picking, location estimation, and magnitude estimation in an end-to-end fashion. By integrating these tasks within a single model, FisH simplifies the overall process and leverages the nonlinear relationships between tasks for improved performance. The FisH model utilizes RetNet as its backbone, enabling parallel processing during training and recurrent handling during inference. This capability makes FisH suitable for real-time applications, reducing latency in EEW systems. Extensive experiments conducted on the STEAD benchmark dataset provide strong validation for the effectiveness of our proposed FisH model. The results demonstrate that FisH achieves impressive performance across multiple seismic event detection and characterization tasks. Specifically, it achieves an F1 score of 0.99/0.96. Also, FisH demonstrates precise earthquake location estimation, with location error of only 6.0km, a distance error of 2.6km, and a back-azimuth error of 19{\deg}. The model also exhibits accurate earthquake magnitude estimation, with a magnitude error of just 0.14. Additionally, FisH is capable of generating real-time estimations, providing location and magnitude estimations with a location error of 8.06km and a magnitude error of 0.18 within a mere 3 seconds after the P-wave arrives.
DocReLM: Mastering Document Retrieval with Language Model
May 19, 2024With over 200 million published academic documents and millions of new documents being written each year, academic researchers face the challenge of searching for information within this vast corpus. However, existing retrieval systems struggle to understand the semantics and domain knowledge present in academic papers. In this work, we demonstrate that by utilizing large language models, a document retrieval system can achieve advanced semantic understanding capabilities, significantly outperforming existing systems. Our approach involves training the retriever and reranker using domain-specific data generated by large language models. Additionally, we utilize large language models to identify candidates from the references of retrieved papers to further enhance the performance. We use a test set annotated by academic researchers in the fields of quantum physics and computer vision to evaluate our system's performance. The results show that DocReLM achieves a Top 10 accuracy of 44.12% in computer vision, compared to Google Scholar's 15.69%, and an increase to 36.21% in quantum physics, while that of Google Scholar is 12.96%.
FengWu: Pushing the Skillful Global Medium-range Weather Forecast beyond 10 Days Lead
Apr 06, 2023



We present FengWu, an advanced data-driven global medium-range weather forecast system based on Artificial Intelligence (AI). Different from existing data-driven weather forecast methods, FengWu solves the medium-range forecast problem from a multi-modal and multi-task perspective. Specifically, a deep learning architecture equipped with model-specific encoder-decoders and cross-modal fusion Transformer is elaborately designed, which is learned under the supervision of an uncertainty loss to balance the optimization of different predictors in a region-adaptive manner. Besides this, a replay buffer mechanism is introduced to improve medium-range forecast performance. With 39-year data training based on the ERA5 reanalysis, FengWu is able to accurately reproduce the atmospheric dynamics and predict the future land and atmosphere states at 37 vertical levels on a 0.25{\deg} latitude-longitude resolution. Hindcasts of 6-hourly weather in 2018 based on ERA5 demonstrate that FengWu performs better than GraphCast in predicting 80\% of the 880 reported predictands, e.g., reducing the root mean square error (RMSE) of 10-day lead global z500 prediction from 733 to 651 $m^{2}/s^2$. In addition, the inference cost of each iteration is merely 600ms on NVIDIA Tesla A100 hardware. The results suggest that FengWu can significantly improve the forecast skill and extend the skillful global medium-range weather forecast out to 10.75 days lead (with ACC of z500 > 0.6) for the first time.
Stack operation of tensor networks
Mar 28, 2022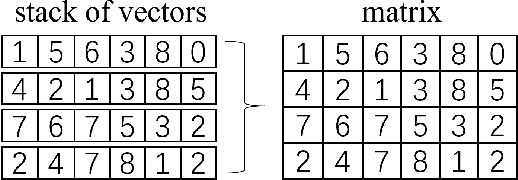
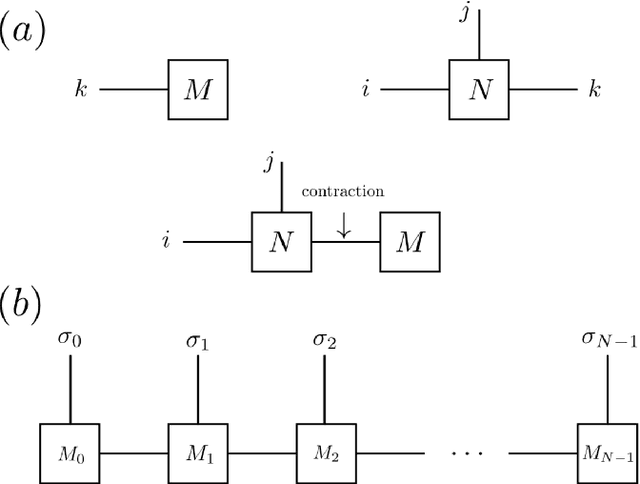
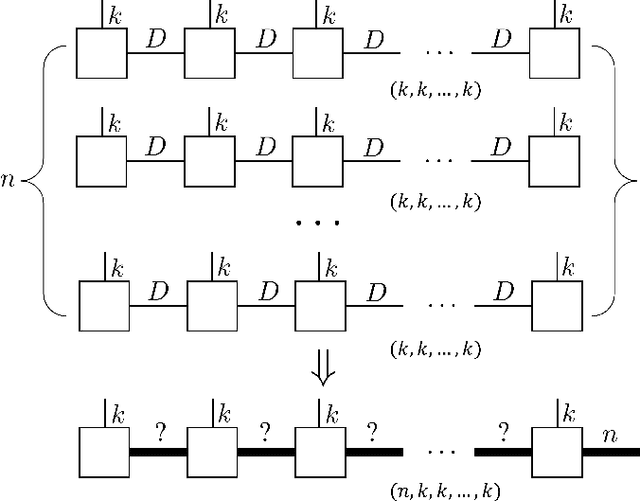
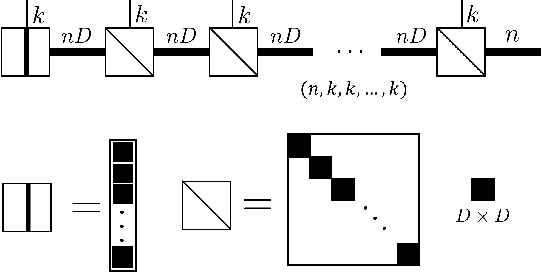
The tensor network, as a facterization of tensors, aims at performing the operations that are common for normal tensors, such as addition, contraction and stacking. However, due to its non-unique network structure, only the tensor network contraction is so far well defined. In this paper, we propose a mathematically rigorous definition for the tensor network stack approach, that compress a large amount of tensor networks into a single one without changing their structures and configurations. We illustrate the main ideas with the matrix product states based machine learning as an example. Our results are compared with the for loop and the efficient coding method on both CPU and GPU.
SUTD-PRCM Dataset and Neural Architecture Search Approach for Complex Metasurface Design
Feb 24, 2022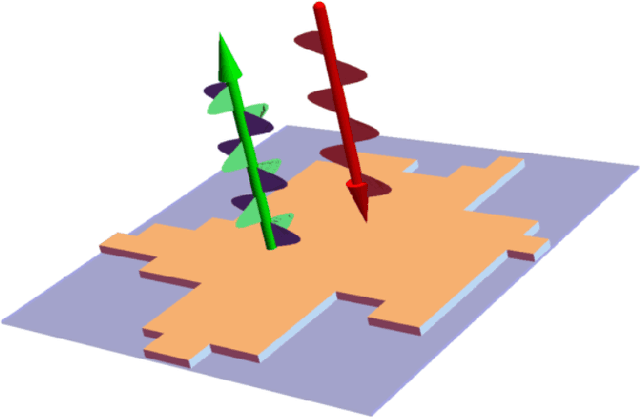


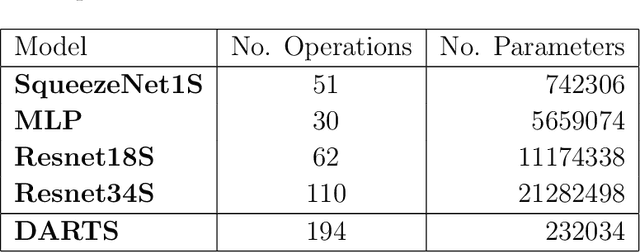
Metasurfaces have received a lot of attentions recently due to their versatile capability in manipulating electromagnetic wave. Advanced designs to satisfy multiple objectives with non-linear constraints have motivated researchers in using machine learning (ML) techniques like deep learning (DL) for accelerated design of metasurfaces. For metasurfaces, it is difficult to make quantitative comparisons between different ML models without having a common and yet complex dataset used in many disciplines like image classification. Many studies were directed to a relatively constrained datasets that are limited to specified patterns or shapes in metasurfaces. In this paper, we present our SUTD polarized reflection of complex metasurfaces (SUTD-PRCM) dataset, which contains approximately 260,000 samples of complex metasurfaces created from electromagnetic simulation, and it has been used to benchmark our DL models. The metasurface patterns are divided into different classes to facilitate different degree of complexity, which involves identifying and exploiting the relationship between the patterns and the electromagnetic responses that can be compared in using different DL models. With the release of this SUTD-PRCM dataset, we hope that it will be useful for benchmarking existing or future DL models developed in the ML community. We also propose a classification problem that is less encountered and apply neural architecture search to have a preliminary understanding of potential modification to the neural architecture that will improve the prediction by DL models. Our finding shows that convolution stacking is not the dominant element of the neural architecture anymore, which implies that low-level features are preferred over the traditional deep hierarchical high-level features thus explains why deep convolutional neural network based models are not performing well in our dataset.