 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient ANN-Guided Distillation: Aligning Rate-based Features of Spiking Neural Networks through Hybrid Block-wise Replacement
Mar 20, 2025Spiking Neural Networks (SNNs) have garnered considerable attention as a potential alternative to Artificial Neural Networks (ANNs). Recent studies have highlighted SNNs' potential on large-scale datasets. For SNN training, two main approaches exist: direct training and ANN-to-SNN (ANN2SNN) conversion. To fully leverage existing ANN models in guiding SNN learning, either direct ANN-to-SNN conversion or ANN-SNN distillation training can be employed. In this paper, we propose an ANN-SNN distillation framework from the ANN-to-SNN perspective, designed with a block-wise replacement strategy for ANN-guided learning. By generating intermediate hybrid models that progressively align SNN feature spaces to those of ANN through rate-based features, our framework naturally incorporates rate-based backpropagation as a training method. Our approach achieves results comparable to or better than state-of-the-art SNN distillation methods, showing both training and learning efficiency.
Efficient Distillation of Deep Spiking Neural Networks for Full-Range Timestep Deployment
Jan 27, 2025Spiking Neural Networks (SNNs) are emerging as a brain-inspired alternative to traditional Artificial Neural Networks (ANNs), prized for their potential energy efficiency on neuromorphic hardware. Despite this, SNNs often suffer from accuracy degradation compared to ANNs and face deployment challenges due to fixed inference timesteps, which require retraining for adjustments, limiting operational flexibility. To address these issues, our work considers the spatio-temporal property inherent in SNNs, and proposes a novel distillation framework for deep SNNs that optimizes performance across full-range timesteps without specific retraining, enhancing both efficacy and deployment adaptability. We provide both theoretical analysis and empirical validations to illustrate that training guarantees the convergence of all implicit models across full-range timesteps. Experimental results on CIFAR-10, CIFAR-100, CIFAR10-DVS, and ImageNet demonstrate state-of-the-art performance among distillation-based SNNs training methods.
Advancing Training Efficiency of Deep Spiking Neural Networks through Rate-based Backpropagation
Oct 15, 2024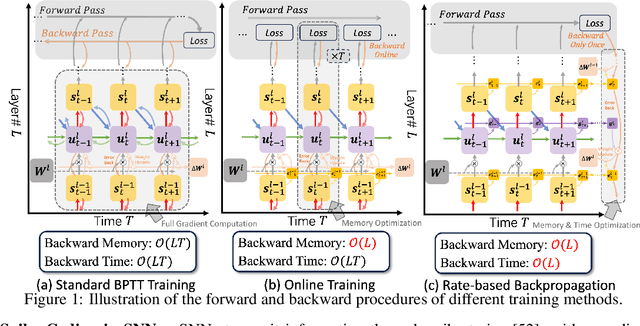
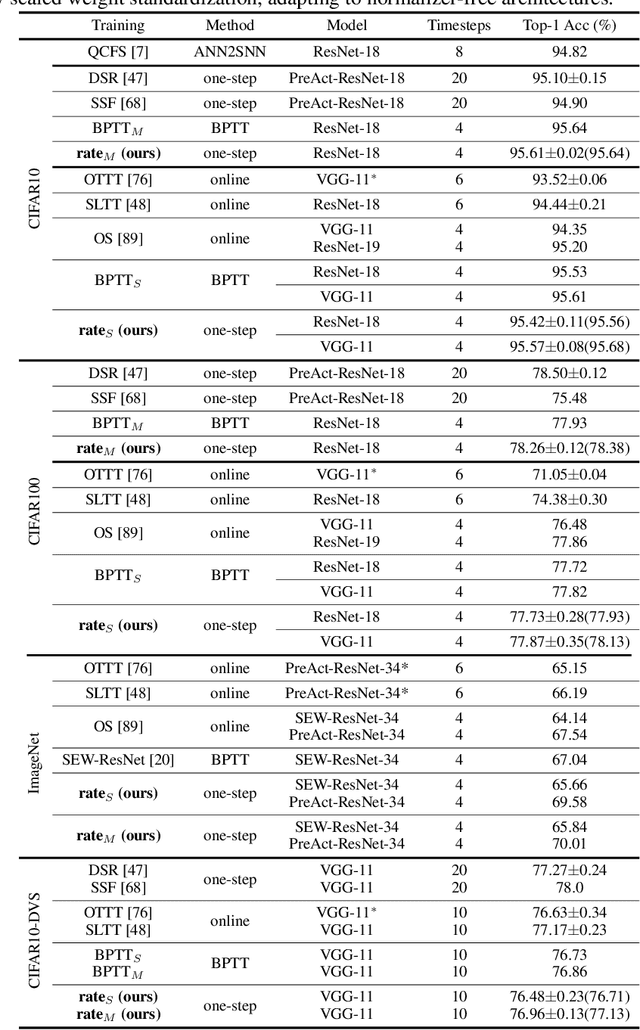
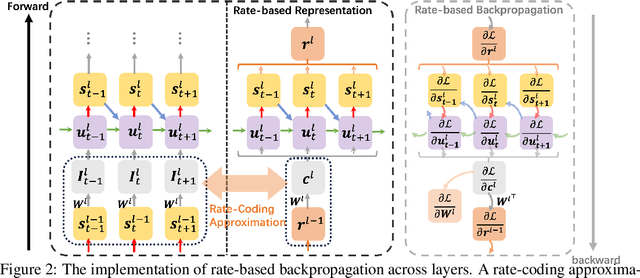
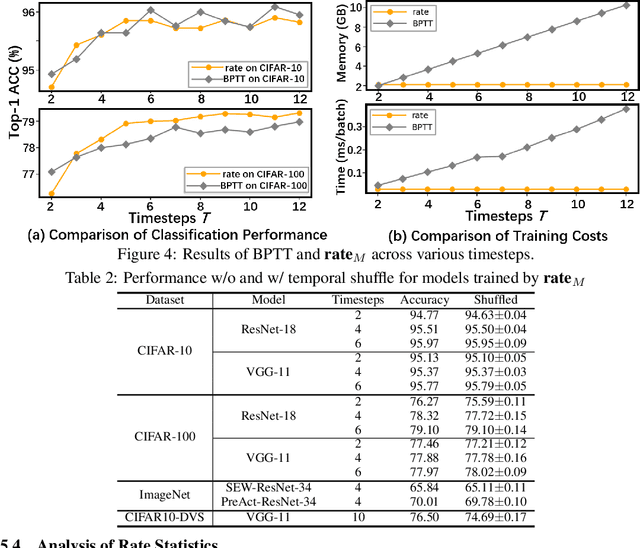
Recent insights have revealed that rate-coding is a primary form of information representation captured by surrogate-gradient-based Backpropagation Through Time (BPTT) in training deep Spiking Neural Networks (SNNs). Motivated by these findings, we propose rate-based backpropagation, a training strategy specifically designed to exploit rate-based representations to reduce the complexity of BPTT. Our method minimizes reliance on detailed temporal derivatives by focusing on averaged dynamics, streamlining the computational graph to reduce memory and computational demands of SNNs training. We substantiate the rationality of the gradient approximation between BPTT and the proposed method through both theoretical analysis and empirical observations. Comprehensive experiments on CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS validate that our method achieves comparable performance to BPTT counterparts, and surpasses state-of-the-art efficient training techniques. By leveraging the inherent benefits of rate-coding, this work sets the stage for more scalable and efficient SNNs training within resource-constrained environments. Our code is available at https://github.com/Tab-ct/rate-based-backpropagation.
Go beyond End-to-End Training: Boosting Greedy Local Learning with Context Supply
Dec 12, 2023



Traditional end-to-end (E2E) training of deep networks necessitates storing intermediate activations for back-propagation, resulting in a large memory footprint on GPUs and restricted model parallelization. As an alternative, greedy local learning partitions the network into gradient-isolated modules and trains supervisely based on local preliminary losses, thereby providing asynchronous and parallel training methods that substantially reduce memory cost. However, empirical experiments reveal that as the number of segmentations of the gradient-isolated module increases, the performance of the local learning scheme degrades substantially, severely limiting its expansibility. To avoid this issue, we theoretically analyze the greedy local learning from the standpoint of information theory and propose a ContSup scheme, which incorporates context supply between isolated modules to compensate for information loss. Experiments on benchmark datasets (i.e. CIFAR, SVHN, STL-10) achieve SOTA results and indicate that our proposed method can significantly improve the performance of greedy local learning with minimal memory and computational overhead, allowing for the boost of the number of isolated modules. Our codes are available at https://github.com/Tab-ct/ContSup.
STSC-SNN: Spatio-Temporal Synaptic Connection with Temporal Convolution and Attention for Spiking Neural Networks
Oct 11, 2022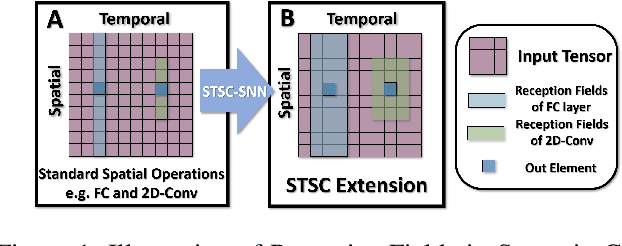
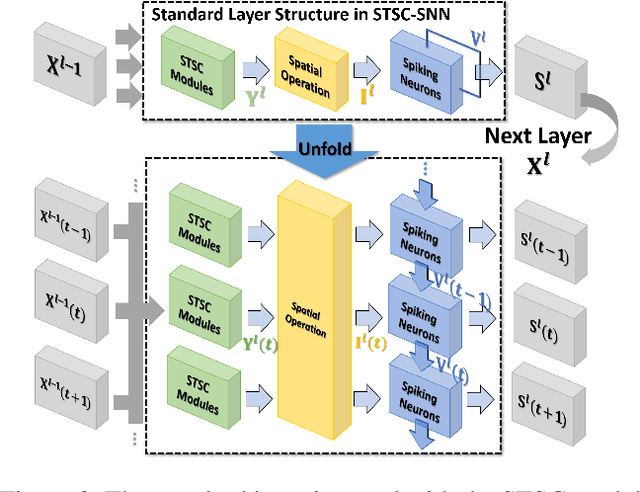
Spiking Neural Networks (SNNs), as one of the algorithmic models in neuromorphic computing, have gained a great deal of research attention owing to temporal information processing capability, low power consumption, and high biological plausibility. The potential to efficiently extract spatio-temporal features makes it suitable for processing the event streams. However, existing synaptic structures in SNNs are almost full-connections or spatial 2D convolution, neither of which can extract temporal dependencies adequately. In this work, we take inspiration from biological synapses and propose a spatio-temporal synaptic connection SNN (STSC-SNN) model, to enhance the spatio-temporal receptive fields of synaptic connections, thereby establishing temporal dependencies across layers. Concretely, we incorporate temporal convolution and attention mechanisms to implement synaptic filtering and gating functions. We show that endowing synaptic models with temporal dependencies can improve the performance of SNNs on classification tasks. In addition, we investigate the impact of performance vias varied spatial-temporal receptive fields and reevaluate the temporal modules in SNNs. Our approach is tested on neuromorphic datasets, including DVS128 Gesture (gesture recognition), N-MNIST, CIFAR10-DVS (image classification), and SHD (speech digit recognition). The results show that the proposed model outperforms the state-of-the-art accuracy on nearly all datasets.
MAP-SNN: Mapping Spike Activities with Multiplicity, Adaptability, and Plasticity into Bio-Plausible Spiking Neural Networks
Apr 21, 2022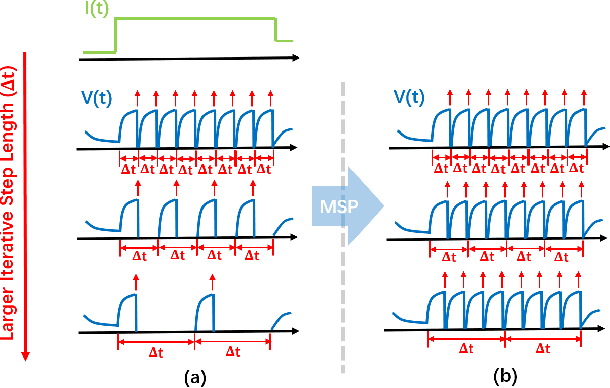
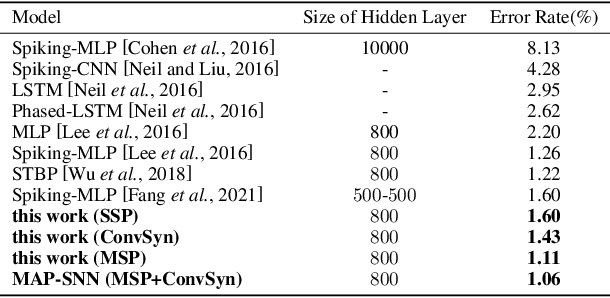
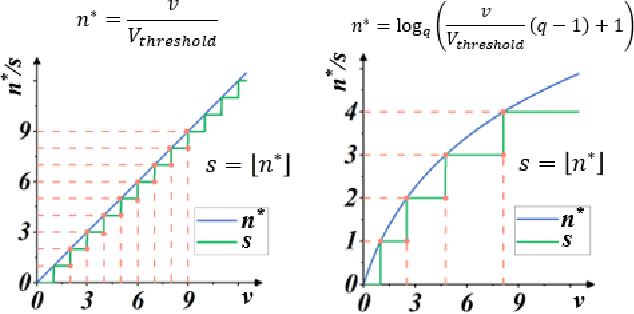
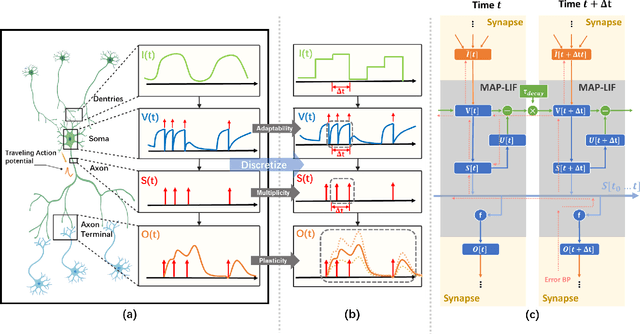
Spiking Neural Network (SNN) is considered more biologically realistic and power-efficient as it imitates the fundamental mechanism of the human brain. Recently, backpropagation (BP) based SNN learning algorithms that utilize deep learning frameworks have achieved good performance. However, bio-interpretability is partially neglected in those BP-based algorithms. Toward bio-plausible BP-based SNNs, we consider three properties in modeling spike activities: Multiplicity, Adaptability, and Plasticity (MAP). In terms of multiplicity, we propose a Multiple-Spike Pattern (MSP) with multiple spike transmission to strengthen model robustness in discrete time-iteration. To realize adaptability, we adopt Spike Frequency Adaption (SFA) under MSP to decrease spike activities for improved efficiency. For plasticity, we propose a trainable convolutional synapse that models spike response current to enhance the diversity of spiking neurons for temporal feature extraction. The proposed SNN model achieves competitive performances on neuromorphic datasets: N-MNIST and SHD. Furthermore, experimental results demonstrate that the proposed three aspects are significant to iterative robustness, spike efficiency, and temporal feature extraction capability of spike activities. In summary, this work proposes a feasible scheme for bio-inspired spike activities with MAP, offering a new neuromorphic perspective to embed biological characteristics into spiking neural networks.
Stack operation of tensor networks
Mar 28, 2022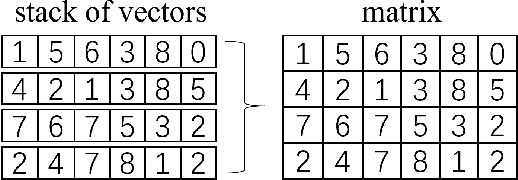
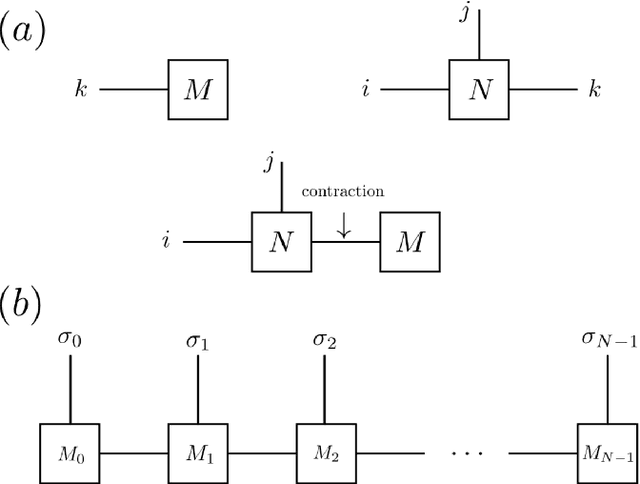
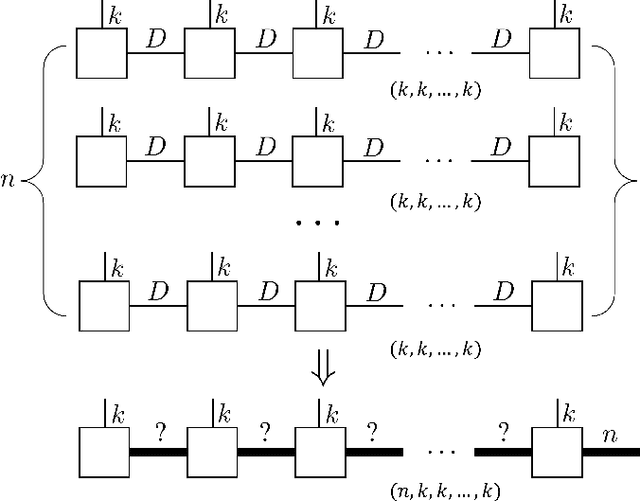
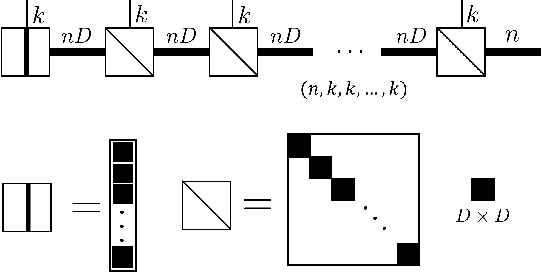
The tensor network, as a facterization of tensors, aims at performing the operations that are common for normal tensors, such as addition, contraction and stacking. However, due to its non-unique network structure, only the tensor network contraction is so far well defined. In this paper, we propose a mathematically rigorous definition for the tensor network stack approach, that compress a large amount of tensor networks into a single one without changing their structures and configurations. We illustrate the main ideas with the matrix product states based machine learning as an example. Our results are compared with the for loop and the efficient coding method on both CPU and GPU.
SUTD-PRCM Dataset and Neural Architecture Search Approach for Complex Metasurface Design
Feb 24, 2022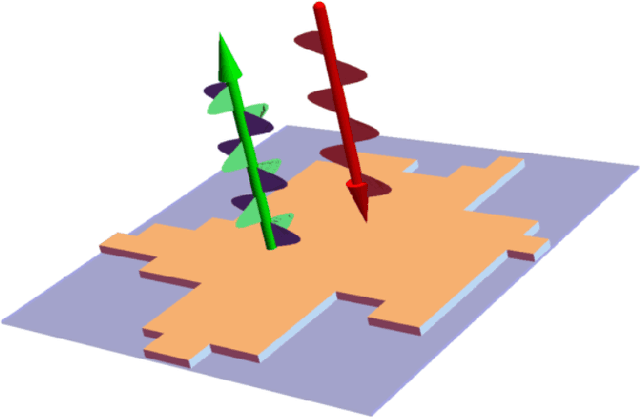


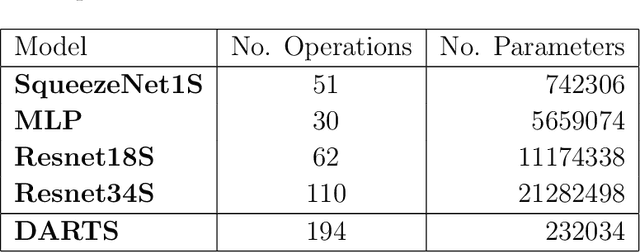
Metasurfaces have received a lot of attentions recently due to their versatile capability in manipulating electromagnetic wave. Advanced designs to satisfy multiple objectives with non-linear constraints have motivated researchers in using machine learning (ML) techniques like deep learning (DL) for accelerated design of metasurfaces. For metasurfaces, it is difficult to make quantitative comparisons between different ML models without having a common and yet complex dataset used in many disciplines like image classification. Many studies were directed to a relatively constrained datasets that are limited to specified patterns or shapes in metasurfaces. In this paper, we present our SUTD polarized reflection of complex metasurfaces (SUTD-PRCM) dataset, which contains approximately 260,000 samples of complex metasurfaces created from electromagnetic simulation, and it has been used to benchmark our DL models. The metasurface patterns are divided into different classes to facilitate different degree of complexity, which involves identifying and exploiting the relationship between the patterns and the electromagnetic responses that can be compared in using different DL models. With the release of this SUTD-PRCM dataset, we hope that it will be useful for benchmarking existing or future DL models developed in the ML community. We also propose a classification problem that is less encountered and apply neural architecture search to have a preliminary understanding of potential modification to the neural architecture that will improve the prediction by DL models. Our finding shows that convolution stacking is not the dominant element of the neural architecture anymore, which implies that low-level features are preferred over the traditional deep hierarchical high-level features thus explains why deep convolutional neural network based models are not performing well in our dataset.