 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
May 30, 2024



Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (Synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive "low-entropy" tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a notable enhancement over existing synthetic content detectors designed for general texts, with an improvement of 20.5% in the APPS benchmark and 29.1% in the MBPP benchmark.
AdaCCD: Adaptive Semantic Contrasts Discovery based Cross Lingual Adaptation for Code Clone Detection
Nov 13, 2023



Code Clone Detection, which aims to retrieve functionally similar programs from large code bases, has been attracting increasing attention. Modern software often involves a diverse range of programming languages. However, current code clone detection methods are generally limited to only a few popular programming languages due to insufficient annotated data as well as their own model design constraints. To address these issues, we present AdaCCD, a novel cross-lingual adaptation method that can detect cloned codes in a new language without any annotations in that language. AdaCCD leverages language-agnostic code representations from pre-trained programming language models and propose an Adaptively Refined Contrastive Learning framework to transfer knowledge from resource-rich languages to resource-poor languages. We evaluate the cross-lingual adaptation results of AdaCCD by constructing a multilingual code clone detection benchmark consisting of 5 programming languages. AdaCCD achieves significant improvements over other baselines, and it is even comparable to supervised fine-tuning.
CP-BCS: Binary Code Summarization Guided by Control Flow Graph and Pseudo Code
Oct 24, 2023Automatically generating function summaries for binaries is an extremely valuable but challenging task, since it involves translating the execution behavior and semantics of the low-level language (assembly code) into human-readable natural language. However, most current works on understanding assembly code are oriented towards generating function names, which involve numerous abbreviations that make them still confusing. To bridge this gap, we focus on generating complete summaries for binary functions, especially for stripped binary (no symbol table and debug information in reality). To fully exploit the semantics of assembly code, we present a control flow graph and pseudo code guided binary code summarization framework called CP-BCS. CP-BCS utilizes a bidirectional instruction-level control flow graph and pseudo code that incorporates expert knowledge to learn the comprehensive binary function execution behavior and logic semantics. We evaluate CP-BCS on 3 different binary optimization levels (O1, O2, and O3) for 3 different computer architectures (X86, X64, and ARM). The evaluation results demonstrate CP-BCS is superior and significantly improves the efficiency of reverse engineering.
Tram: A Token-level Retrieval-augmented Mechanism for Source Code Summarization
May 18, 2023



Automatically generating human-readable text describing the functionality of a program is the intent of source code summarization. Although Neural Language Models achieve significant performance in this field, an emerging trend is combining neural models with external knowledge. Most previous approaches rely on the sentence-level retrieval and combination paradigm (retrieval of similar code snippets and use of the corresponding code and summary pairs) on the encoder side. However, this paradigm is coarse-grained and cannot directly take advantage of the high-quality retrieved summary tokens on the decoder side. In this paper, we explore a fine-grained token-level retrieval-augmented mechanism on the decoder side to help the vanilla neural model generate a better code summary. Furthermore, to mitigate the limitation of token-level retrieval on capturing contextual code semantics, we propose to integrate code semantics into summary tokens. Extensive experiments and human evaluation reveal that our token-level retrieval-augmented approach significantly improves performance and is more interpretive.
Improving Long Tailed Document-Level Relation Extraction via Easy Relation Augmentation and Contrastive Learning
May 21, 2022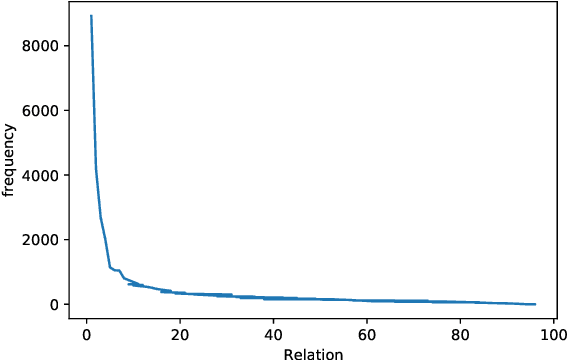
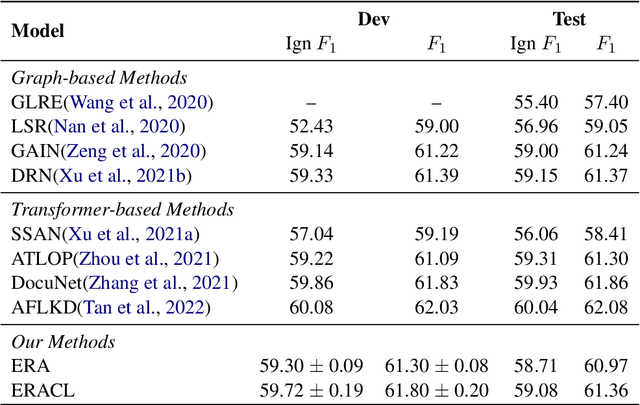
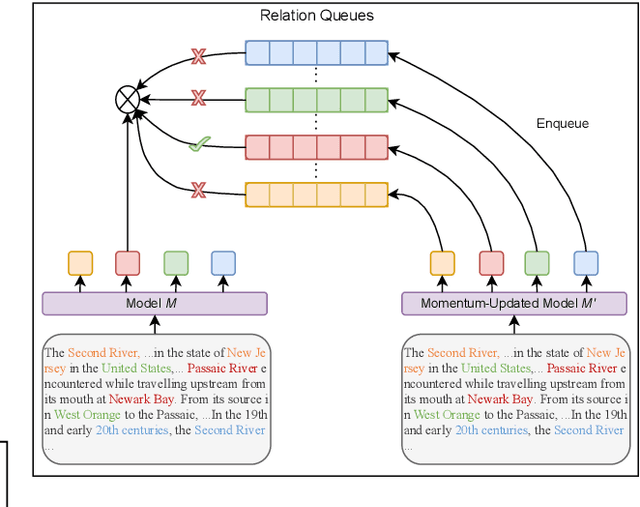
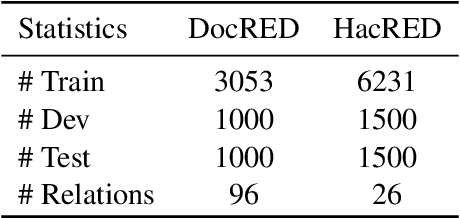
Towards real-world information extraction scenario, research of relation extraction is advancing to document-level relation extraction(DocRE). Existing approaches for DocRE aim to extract relation by encoding various information sources in the long context by novel model architectures. However, the inherent long-tailed distribution problem of DocRE is overlooked by prior work. We argue that mitigating the long-tailed distribution problem is crucial for DocRE in the real-world scenario. Motivated by the long-tailed distribution problem, we propose an Easy Relation Augmentation(ERA) method for improving DocRE by enhancing the performance of tailed relations. In addition, we further propose a novel contrastive learning framework based on our ERA, i.e., ERACL, which can further improve the model performance on tailed relations and achieve competitive overall DocRE performance compared to the state-of-arts.
MAP-SNN: Mapping Spike Activities with Multiplicity, Adaptability, and Plasticity into Bio-Plausible Spiking Neural Networks
Apr 21, 2022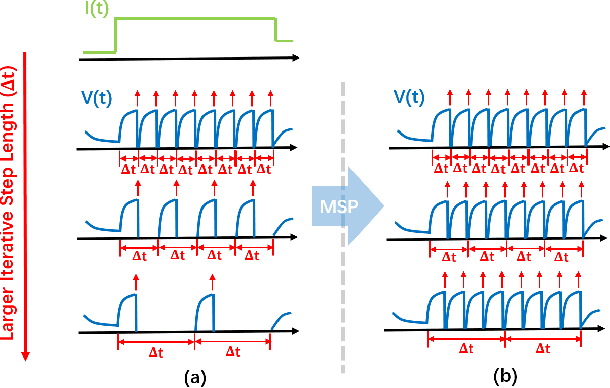
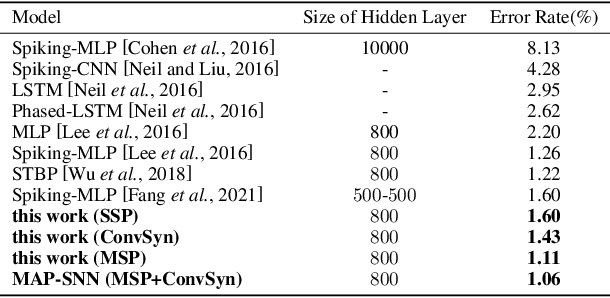
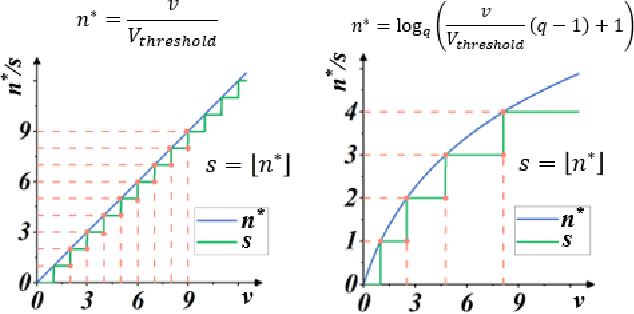
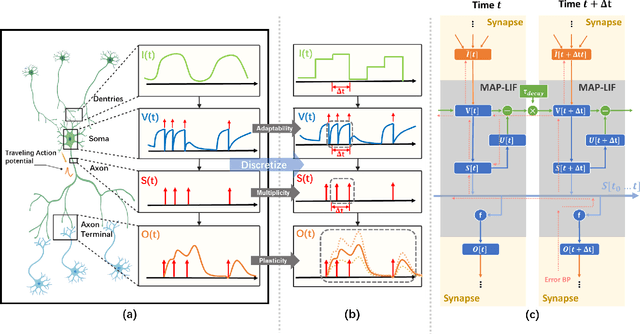
Spiking Neural Network (SNN) is considered more biologically realistic and power-efficient as it imitates the fundamental mechanism of the human brain. Recently, backpropagation (BP) based SNN learning algorithms that utilize deep learning frameworks have achieved good performance. However, bio-interpretability is partially neglected in those BP-based algorithms. Toward bio-plausible BP-based SNNs, we consider three properties in modeling spike activities: Multiplicity, Adaptability, and Plasticity (MAP). In terms of multiplicity, we propose a Multiple-Spike Pattern (MSP) with multiple spike transmission to strengthen model robustness in discrete time-iteration. To realize adaptability, we adopt Spike Frequency Adaption (SFA) under MSP to decrease spike activities for improved efficiency. For plasticity, we propose a trainable convolutional synapse that models spike response current to enhance the diversity of spiking neurons for temporal feature extraction. The proposed SNN model achieves competitive performances on neuromorphic datasets: N-MNIST and SHD. Furthermore, experimental results demonstrate that the proposed three aspects are significant to iterative robustness, spike efficiency, and temporal feature extraction capability of spike activities. In summary, this work proposes a feasible scheme for bio-inspired spike activities with MAP, offering a new neuromorphic perspective to embed biological characteristics into spiking neural networks.
Constructing Contrastive samples via Summarization for Text Classification with limited annotations
Apr 11, 2021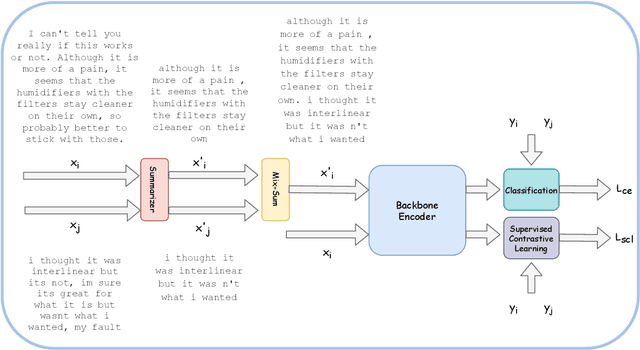
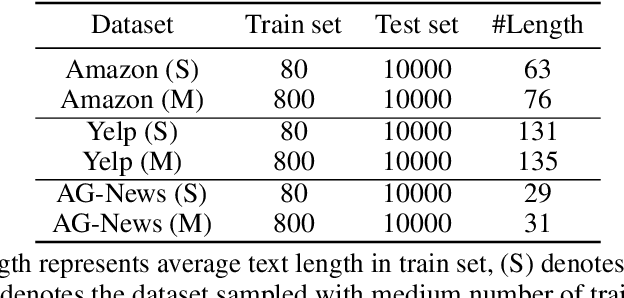
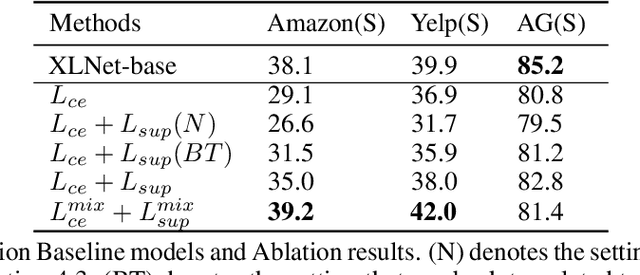
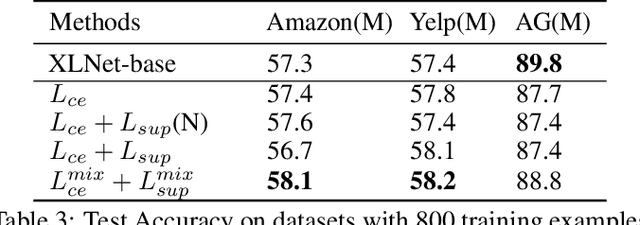
Contrastive Learning has emerged as a powerful representation learning method and facilitates various downstream tasks especially when supervised data is limited. How to construct efficient contrastive samples through data augmentation is key to its success. Unlike vision tasks, the data augmentation method for contrastive learning has not been investigated sufficiently in language tasks. In this paper, we propose a novel approach to constructing contrastive samples for language tasks using text summarization. We use these samples for supervised contrastive learning to gain better text representations which greatly benefit text classification tasks with limited annotations. To further improve the method, we mix up samples from different classes and add an extra regularization, named mix-sum regularization, in addition to the cross-entropy-loss. Experiments on real-world text classification datasets (Amazon-5, Yelp-5, AG News) demonstrate the effectiveness of the proposed contrastive learning framework with summarization-based data augmentation and mix-sum regularization.