 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised makeup transfer with a curated dataset: Decoupling identity and makeup features for enhanced transformation
Jan 31, 2026Diffusion models have recently shown strong progress in generative tasks, offering a more stable alternative to GAN-based approaches for makeup transfer. Existing methods often suffer from limited datasets, poor disentanglement between identity and makeup features, and weak controllability. To address these issues, we make three contributions. First, we construct a curated high-quality dataset using a train-generate-filter-retrain strategy that combines synthetic, realistic, and filtered samples to improve diversity and fidelity. Second, we design a diffusion-based framework that disentangles identity and makeup features, ensuring facial structure and skin tone are preserved while applying accurate and diverse cosmetic styles. Third, we propose a text-guided mechanism that allows fine-grained and region-specific control, enabling users to modify eyes, lips, or face makeup with natural language prompts. Experiments on benchmarks and real-world scenarios demonstrate improvements in fidelity, identity preservation, and flexibility. Examples of our dataset can be found at: https://makeup-adapter.github.io.
Mass Concept Erasure in Diffusion Models with Concept Hierarchy
Jan 06, 2026The success of diffusion models has raised concerns about the generation of unsafe or harmful content, prompting concept erasure approaches that fine-tune modules to suppress specific concepts while preserving general generative capabilities. However, as the number of erased concepts grows, these methods often become inefficient and ineffective, since each concept requires a separate set of fine-tuned parameters and may degrade the overall generation quality. In this work, we propose a supertype-subtype concept hierarchy that organizes erased concepts into a parent-child structure. Each erased concept is treated as a child node, and semantically related concepts (e.g., macaw, and bald eagle) are grouped under a shared parent node, referred to as a supertype concept (e.g., bird). Rather than erasing concepts individually, we introduce an effective and efficient group-wise suppression method, where semantically similar concepts are grouped and erased jointly by sharing a single set of learnable parameters. During the erasure phase, standard diffusion regularization is applied to preserve denoising process in unmasked regions. To mitigate the degradation of supertype generation caused by excessive erasure of semantically related subtypes, we propose a novel method called Supertype-Preserving Low-Rank Adaptation (SuPLoRA), which encodes the supertype concept information in the frozen down-projection matrix and updates only the up-projection matrix during erasure. Theoretical analysis demonstrates the effectiveness of SuPLoRA in mitigating generation performance degradation. We construct a more challenging benchmark that requires simultaneous erasure of concepts across diverse domains, including celebrities, objects, and pornographic content.
On-Device Diffusion Transformer Policy for Efficient Robot Manipulation
Aug 01, 2025Diffusion Policies have significantly advanced robotic manipulation tasks via imitation learning, but their application on resource-constrained mobile platforms remains challenging due to computational inefficiency and extensive memory footprint. In this paper, we propose LightDP, a novel framework specifically designed to accelerate Diffusion Policies for real-time deployment on mobile devices. LightDP addresses the computational bottleneck through two core strategies: network compression of the denoising modules and reduction of the required sampling steps. We first conduct an extensive computational analysis on existing Diffusion Policy architectures, identifying the denoising network as the primary contributor to latency. To overcome performance degradation typically associated with conventional pruning methods, we introduce a unified pruning and retraining pipeline, optimizing the model's post-pruning recoverability explicitly. Furthermore, we combine pruning techniques with consistency distillation to effectively reduce sampling steps while maintaining action prediction accuracy. Experimental evaluations on the standard datasets, \ie, PushT, Robomimic, CALVIN, and LIBERO, demonstrate that LightDP achieves real-time action prediction on mobile devices with competitive performance, marking an important step toward practical deployment of diffusion-based policies in resource-limited environments. Extensive real-world experiments also show the proposed LightDP can achieve performance comparable to state-of-the-art Diffusion Policies.
Improving vision-language alignment with graph spiking hybrid Networks
Jan 31, 2025To bridge the semantic gap between vision and language (VL), it is necessary to develop a good alignment strategy, which includes handling semantic diversity, abstract representation of visual information, and generalization ability of models. Recent works use detector-based bounding boxes or patches with regular partitions to represent visual semantics. While current paradigms have made strides, they are still insufficient for fully capturing the nuanced contextual relations among various objects. This paper proposes a comprehensive visual semantic representation module, necessitating the utilization of panoptic segmentation to generate coherent fine-grained semantic features. Furthermore, we propose a novel Graph Spiking Hybrid Network (GSHN) that integrates the complementary advantages of Spiking Neural Networks (SNNs) and Graph Attention Networks (GATs) to encode visual semantic information. Intriguingly, the model not only encodes the discrete and continuous latent variables of instances but also adeptly captures both local and global contextual features, thereby significantly enhancing the richness and diversity of semantic representations. Leveraging the spatiotemporal properties inherent in SNNs, we employ contrastive learning (CL) to enhance the similarity-based representation of embeddings. This strategy alleviates the computational overhead of the model and enriches meaningful visual representations by constructing positive and negative sample pairs. We design an innovative pre-training method, Spiked Text Learning (STL), which uses text features to improve the encoding ability of discrete semantics. Experiments show that the proposed GSHN exhibits promising results on multiple VL downstream tasks.
MoTe: Learning Motion-Text Diffusion Model for Multiple Generation Tasks
Nov 29, 2024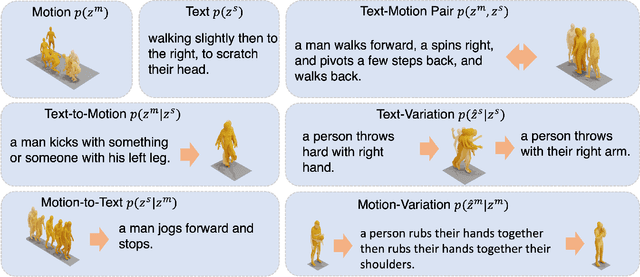

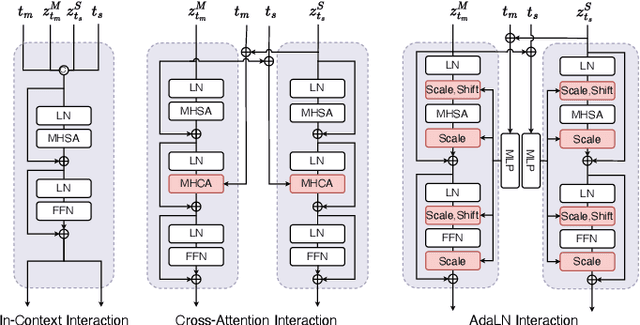

Recently, human motion analysis has experienced great improvement due to inspiring generative models such as the denoising diffusion model and large language model. While the existing approaches mainly focus on generating motions with textual descriptions and overlook the reciprocal task. In this paper, we present~\textbf{MoTe}, a unified multi-modal model that could handle diverse tasks by learning the marginal, conditional, and joint distributions of motion and text simultaneously. MoTe enables us to handle the paired text-motion generation, motion captioning, and text-driven motion generation by simply modifying the input context. Specifically, MoTe is composed of three components: Motion Encoder-Decoder (MED), Text Encoder-Decoder (TED), and Moti-on-Text Diffusion Model (MTDM). In particular, MED and TED are trained for extracting latent embeddings, and subsequently reconstructing the motion sequences and textual descriptions from the extracted embeddings, respectively. MTDM, on the other hand, performs an iterative denoising process on the input context to handle diverse tasks. Experimental results on the benchmark datasets demonstrate the superior performance of our proposed method on text-to-motion generation and competitive performance on motion captioning.
Individual Content and Motion Dynamics Preserved Pruning for Video Diffusion Models
Nov 27, 2024



The high computational cost and slow inference time are major obstacles to deploying the video diffusion model (VDM) in practical applications. To overcome this, we introduce a new Video Diffusion Model Compression approach using individual content and motion dynamics preserved pruning and consistency loss. First, we empirically observe that deeper VDM layers are crucial for maintaining the quality of \textbf{motion dynamics} e.g., coherence of the entire video, while shallower layers are more focused on \textbf{individual content} e.g., individual frames. Therefore, we prune redundant blocks from the shallower layers while preserving more of the deeper layers, resulting in a lightweight VDM variant called VDMini. Additionally, we propose an \textbf{Individual Content and Motion Dynamics (ICMD)} Consistency Loss to gain comparable generation performance as larger VDM, i.e., the teacher to VDMini i.e., the student. Particularly, we first use the Individual Content Distillation (ICD) Loss to ensure consistency in the features of each generated frame between the teacher and student models. Next, we introduce a Multi-frame Content Adversarial (MCA) Loss to enhance the motion dynamics across the generated video as a whole. This method significantly accelerates inference time while maintaining high-quality video generation. Extensive experiments demonstrate the effectiveness of our VDMini on two important video generation tasks, Text-to-Video (T2V) and Image-to-Video (I2V), where we respectively achieve an average 2.5 $\times$ and 1.4 $\times$ speed up for the I2V method SF-V and the T2V method T2V-Turbo-v2, while maintaining the quality of the generated videos on two benchmarks, i.e., UCF101 and VBench.
Towards Small Object Editing: A Benchmark Dataset and A Training-Free Approach
Nov 03, 2024



A plethora of text-guided image editing methods has recently been developed by leveraging the impressive capabilities of large-scale diffusion-based generative models especially Stable Diffusion. Despite the success of diffusion models in producing high-quality images, their application to small object generation has been limited due to difficulties in aligning cross-modal attention maps between text and these objects. Our approach offers a training-free method that significantly mitigates this alignment issue with local and global attention guidance , enhancing the model's ability to accurately render small objects in accordance with textual descriptions. We detail the methodology in our approach, emphasizing its divergence from traditional generation techniques and highlighting its advantages. What's more important is that we also provide~\textit{SOEBench} (Small Object Editing), a standardized benchmark for quantitatively evaluating text-based small object generation collected from \textit{MSCOCO} and \textit{OpenImage}. Preliminary results demonstrate the effectiveness of our method, showing marked improvements in the fidelity and accuracy of small object generation compared to existing models. This advancement not only contributes to the field of AI and computer vision but also opens up new possibilities for applications in various industries where precise image generation is critical. We will release our dataset on our project page: \href{https://soebench.github.io/}{https://soebench.github.io/}.
Self-distilled Dynamic Fusion Network for Language-based Fashion Retrieval
May 24, 2024



In the domain of language-based fashion image retrieval, pinpointing the desired fashion item using both a reference image and its accompanying textual description is an intriguing challenge. Existing approaches lean heavily on static fusion techniques, intertwining image and text. Despite their commendable advancements, these approaches are still limited by a deficiency in flexibility. In response, we propose a Self-distilled Dynamic Fusion Network to compose the multi-granularity features dynamically by considering the consistency of routing path and modality-specific information simultaneously. Two new modules are included in our proposed method: (1) Dynamic Fusion Network with Modality Specific Routers. The dynamic network enables a flexible determination of the routing for each reference image and modification text, taking into account their distinct semantics and distributions. (2) Self Path Distillation Loss. A stable path decision for queries benefits the optimization of feature extraction as well as routing, and we approach this by progressively refine the path decision with previous path information. Extensive experiments demonstrate the effectiveness of our proposed model compared to existing methods.
PoinTramba: A Hybrid Transformer-Mamba Framework for Point Cloud Analysis
May 24, 2024



Point cloud analysis has seen substantial advancements due to deep learning, although previous Transformer-based methods excel at modeling long-range dependencies on this task, their computational demands are substantial. Conversely, the Mamba offers greater efficiency but shows limited potential compared with Transformer-based methods. In this study, we introduce PoinTramba, a pioneering hybrid framework that synergies the analytical power of Transformer with the remarkable computational efficiency of Mamba for enhanced point cloud analysis. Specifically, our approach first segments point clouds into groups, where the Transformer meticulously captures intricate intra-group dependencies and produces group embeddings, whose inter-group relationships will be simultaneously and adeptly captured by efficient Mamba architecture, ensuring comprehensive analysis. Unlike previous Mamba approaches, we introduce a bi-directional importance-aware ordering (BIO) strategy to tackle the challenges of random ordering effects. This innovative strategy intelligently reorders group embeddings based on their calculated importance scores, significantly enhancing Mamba's performance and optimizing the overall analytical process. Our framework achieves a superior balance between computational efficiency and analytical performance by seamlessly integrating these advanced techniques, marking a substantial leap forward in point cloud analysis. Extensive experiments on datasets such as ScanObjectNN, ModelNet40, and ShapeNetPart demonstrate the effectiveness of our approach, establishing a new state-of-the-art analysis benchmark on point cloud recognition. For the first time, this paradigm leverages the combined strengths of both Transformer and Mamba architectures, facilitating a new standard in the field. The code is available at https://github.com/xiaoyao3302/PoinTramba.
SOEDiff: Efficient Distillation for Small Object Editing
May 15, 2024In this paper, we delve into a new task known as small object editing (SOE), which focuses on text-based image inpainting within a constrained, small-sized area. Despite the remarkable success have been achieved by current image inpainting approaches, their application to the SOE task generally results in failure cases such as Object Missing, Text-Image Mismatch, and Distortion. These failures stem from the limited use of small-sized objects in training datasets and the downsampling operations employed by U-Net models, which hinders accurate generation. To overcome these challenges, we introduce a novel training-based approach, SOEDiff, aimed at enhancing the capability of baseline models like StableDiffusion in editing small-sized objects while minimizing training costs. Specifically, our method involves two key components: SO-LoRA, which efficiently fine-tunes low-rank matrices, and Cross-Scale Score Distillation loss, which leverages high-resolution predictions from the pre-trained teacher diffusion model. Our method presents significant improvements on the test dataset collected from MSCOCO and OpenImage, validating the effectiveness of our proposed method in small object editing. In particular, when comparing SOEDiff with SD-I model on the OpenImage-f dataset, we observe a 0.99 improvement in CLIP-Score and a reduction of 2.87 in FID. Our project page can be found in https://soediff.github.io/.