 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-distilled Dynamic Fusion Network for Language-based Fashion Retrieval
May 24, 2024



In the domain of language-based fashion image retrieval, pinpointing the desired fashion item using both a reference image and its accompanying textual description is an intriguing challenge. Existing approaches lean heavily on static fusion techniques, intertwining image and text. Despite their commendable advancements, these approaches are still limited by a deficiency in flexibility. In response, we propose a Self-distilled Dynamic Fusion Network to compose the multi-granularity features dynamically by considering the consistency of routing path and modality-specific information simultaneously. Two new modules are included in our proposed method: (1) Dynamic Fusion Network with Modality Specific Routers. The dynamic network enables a flexible determination of the routing for each reference image and modification text, taking into account their distinct semantics and distributions. (2) Self Path Distillation Loss. A stable path decision for queries benefits the optimization of feature extraction as well as routing, and we approach this by progressively refine the path decision with previous path information. Extensive experiments demonstrate the effectiveness of our proposed model compared to existing methods.
Semiparametric Regression for Spatial Data via Deep Learning
Jan 10, 2023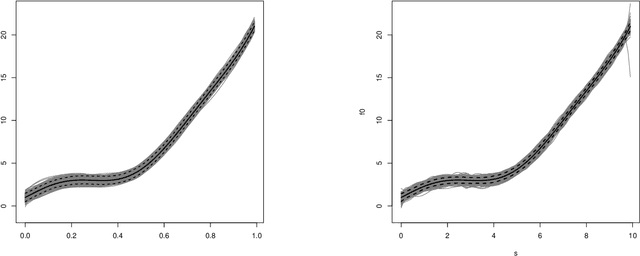
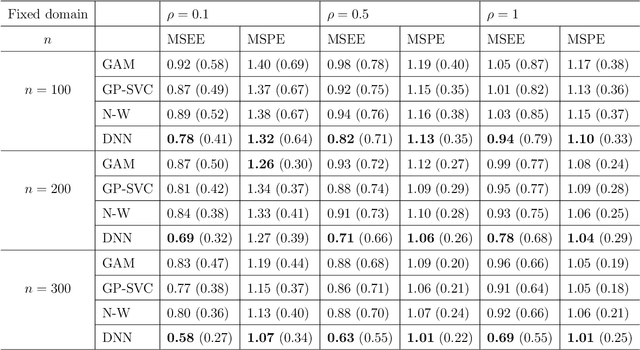
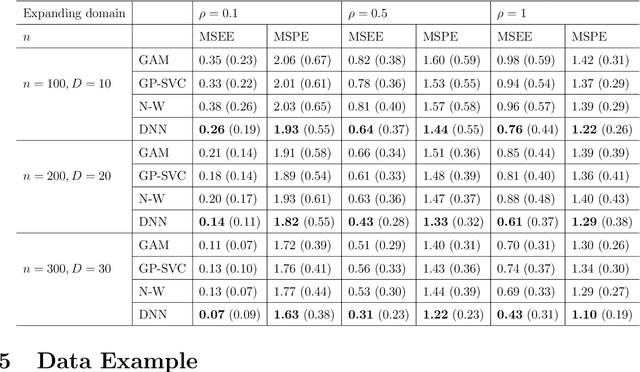
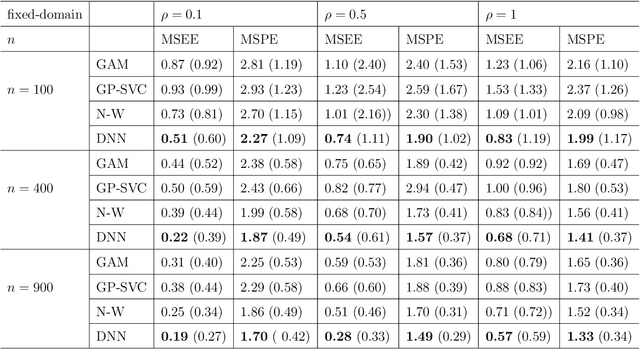
In this work, we propose a deep learning-based method to perform semiparametric regression analysis for spatially dependent data. To be specific, we use a sparsely connected deep neural network with rectified linear unit (ReLU) activation function to estimate the unknown regression function that describes the relationship between response and covariates in the presence of spatial dependence. Under some mild conditions, the estimator is proven to be consistent, and the rate of convergence is determined by three factors: (1) the architecture of neural network class, (2) the smoothness and (intrinsic) dimension of true mean function, and (3) the magnitude of spatial dependence. Our method can handle well large data set owing to the stochastic gradient descent optimization algorithm. Simulation studies on synthetic data are conducted to assess the finite sample performance, the results of which indicate that the proposed method is capable of picking up the intricate relationship between response and covariates. Finally, a real data analysis is provided to demonstrate the validity and effectiveness of the proposed method.
S2TNet: Spatio-Temporal Transformer Networks for Trajectory Prediction in Autonomous Driving
Jun 22, 2022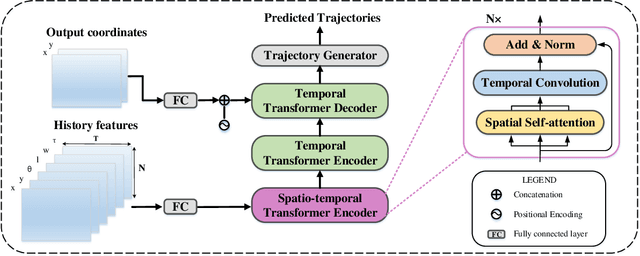
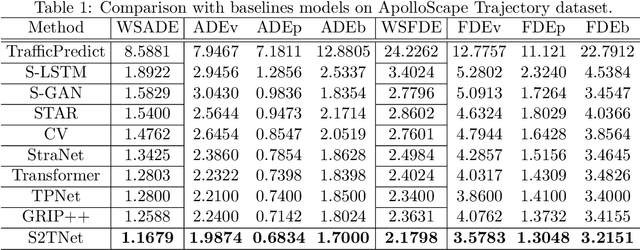
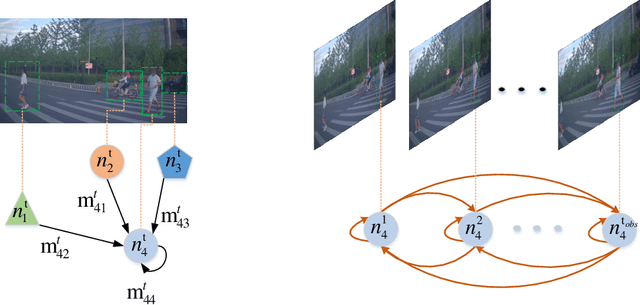
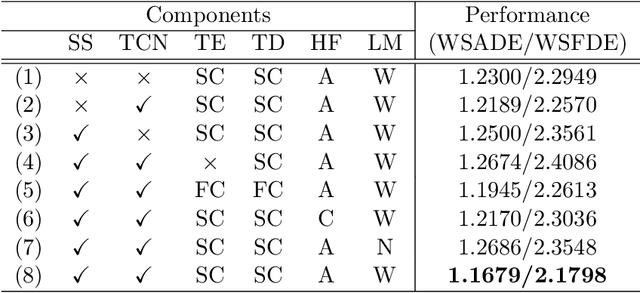
To safely and rationally participate in dense and heterogeneous traffic, autonomous vehicles require to sufficiently analyze the motion patterns of surrounding traffic-agents and accurately predict their future trajectories. This is challenging because the trajectories of traffic-agents are not only influenced by the traffic-agents themselves but also by spatial interaction with each other. Previous methods usually rely on the sequential step-by-step processing of Long Short-Term Memory networks (LSTMs) and merely extract the interactions between spatial neighbors for single type traffic-agents. We propose the Spatio-Temporal Transformer Networks (S2TNet), which models the spatio-temporal interactions by spatio-temporal Transformer and deals with the temporel sequences by temporal Transformer. We input additional category, shape and heading information into our networks to handle the heterogeneity of traffic-agents. The proposed methods outperforms state-of-the-art methods on ApolloScape Trajectory dataset by more than 7\% on both the weighted sum of Average and Final Displacement Error. Our code is available at https://github.com/chenghuang66/s2tnet.
Deep Feature Screening: Feature Selection for Ultra High-Dimensional Data via Deep Neural Networks
Apr 04, 2022
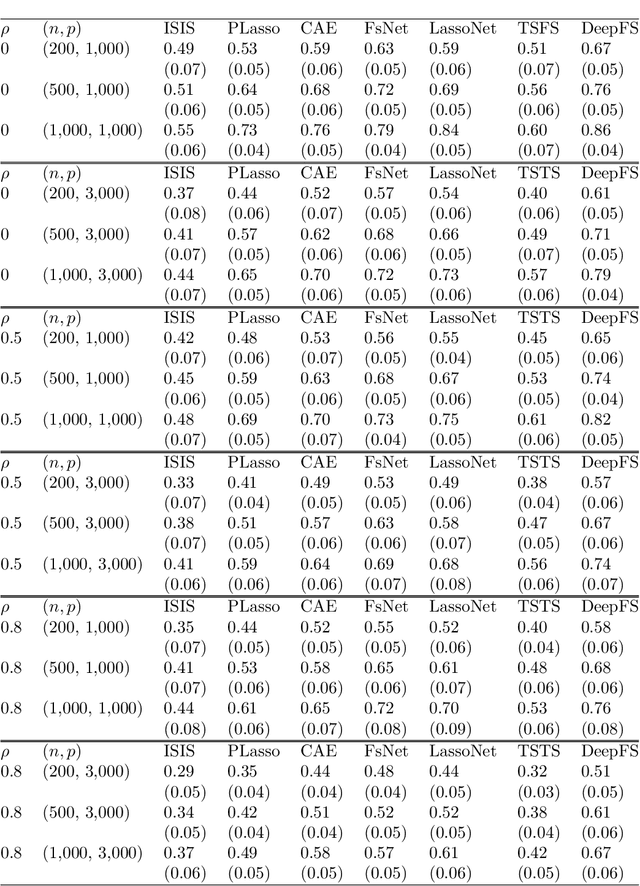
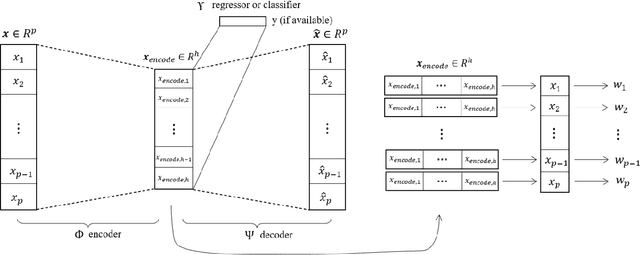
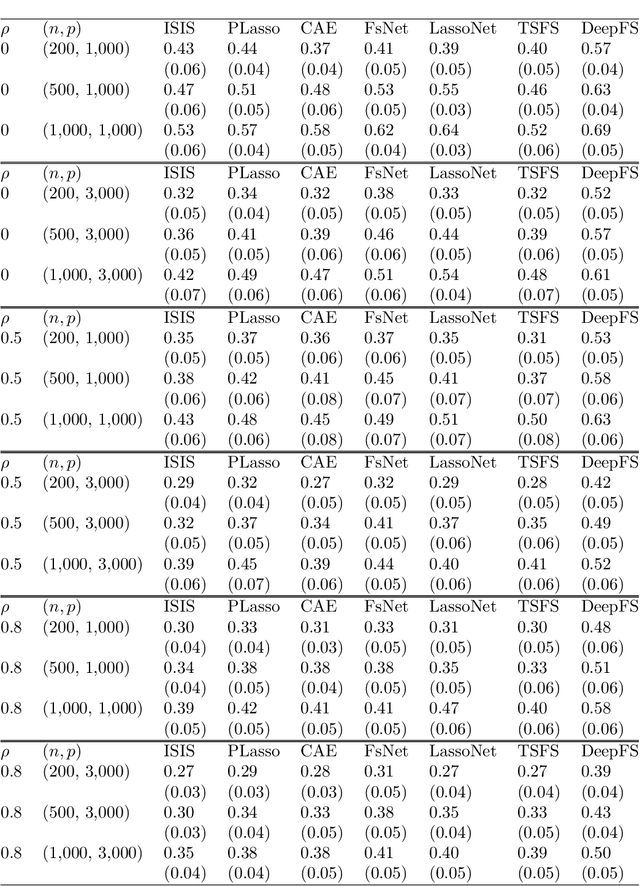
The applications of traditional statistical feature selection methods to high-dimension, low sample-size data often struggle and encounter challenging problems, such as overfitting, curse of dimensionality, computational infeasibility, and strong model assumption. In this paper, we propose a novel two-step nonparametric approach called Deep Feature Screening (DeepFS) that can overcome these problems and identify significant features with high precision for ultra high-dimensional, low-sample-size data. This approach first extracts a low-dimensional representation of input data and then applies feature screening based on multivariate rank distance correlation recently developed by Deb and Sen (2021). This approach combines the strengths of both deep neural networks and feature screening, and thereby has the following appealing features in addition to its ability of handling ultra high-dimensional data with small number of samples: (1) it is model free and distribution free; (2) it can be used for both supervised and unsupervised feature selection; and (3) it is capable of recovering the original input data. The superiority of DeepFS is demonstrated via extensive simulation studies and real data analyses.
CFNet: Learning Correlation Functions for One-Stage Panoptic Segmentation
Jan 13, 2022
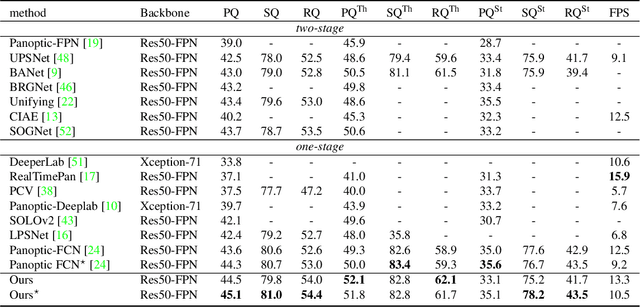
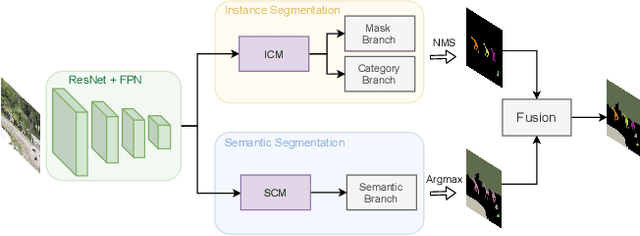
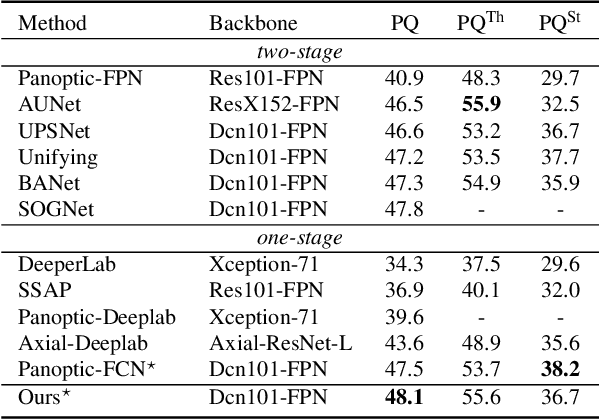
Recently, there is growing attention on one-stage panoptic segmentation methods which aim to segment instances and stuff jointly within a fully convolutional pipeline efficiently. However, most of the existing works directly feed the backbone features to various segmentation heads ignoring the demands for semantic and instance segmentation are different: The former needs semantic-level discriminative features, while the latter requires features to be distinguishable across instances. To alleviate this, we propose to first predict semantic-level and instance-level correlations among different locations that are utilized to enhance the backbone features, and then feed the improved discriminative features into the corresponding segmentation heads, respectively. Specifically, we organize the correlations between a given location and all locations as a continuous sequence and predict it as a whole. Considering that such a sequence can be extremely complicated, we adopt Discrete Fourier Transform (DFT), a tool that can approximate an arbitrary sequence parameterized by amplitudes and phrases. For different tasks, we generate these parameters from the backbone features in a fully convolutional way which is optimized implicitly by corresponding tasks. As a result, these accurate and consistent correlations contribute to producing plausible discriminative features which meet the requirements of the complicated panoptic segmentation task. To verify the effectiveness of our methods, we conduct experiments on several challenging panoptic segmentation datasets and achieve state-of-the-art performance on MS COCO with $45.1$\% PQ and ADE20k with $32.6$\% PQ.
Calibrating multi-dimensional complex ODE from noisy data via deep neural networks
Jun 07, 2021
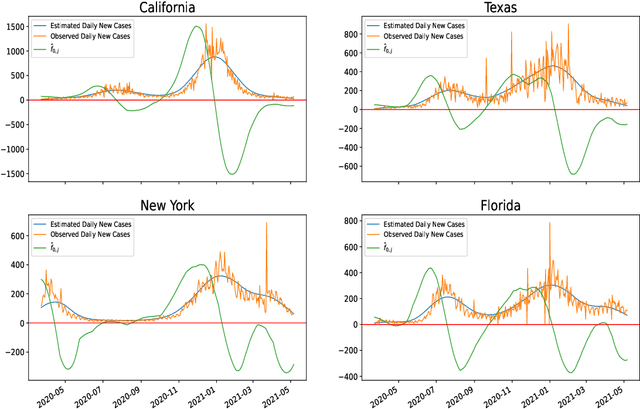
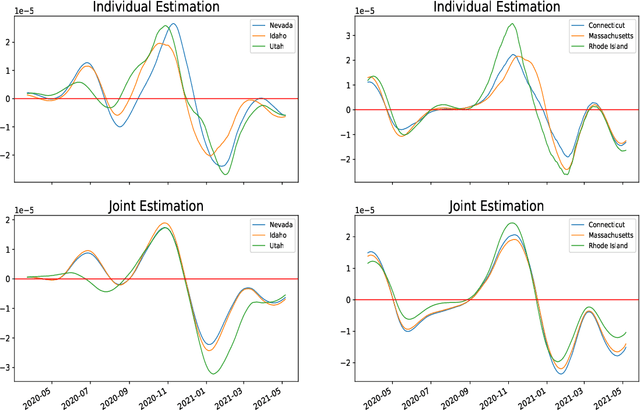
Ordinary differential equations (ODEs) are widely used to model complex dynamics that arises in biology, chemistry, engineering, finance, physics, etc. Calibration of a complicated ODE system using noisy data is generally very difficult. In this work, we propose a two-stage nonparametric approach to address this problem. We first extract the de-noised data and their higher order derivatives using boundary kernel method, and then feed them into a sparsely connected deep neural network with ReLU activation function. Our method is able to recover the ODE system without being subject to the curse of dimensionality and complicated ODE structure. When the ODE possesses a general modular structure, with each modular component involving only a few input variables, and the network architecture is properly chosen, our method is proven to be consistent. Theoretical properties are corroborated by an extensive simulation study that demonstrates the validity and effectiveness of the proposed method. Finally, we use our method to simultaneously characterize the growth rate of Covid-19 infection cases from 50 states of the USA.
TextRay: Contour-based Geometric Modeling for Arbitrary-shaped Scene Text Detection
Aug 12, 2020
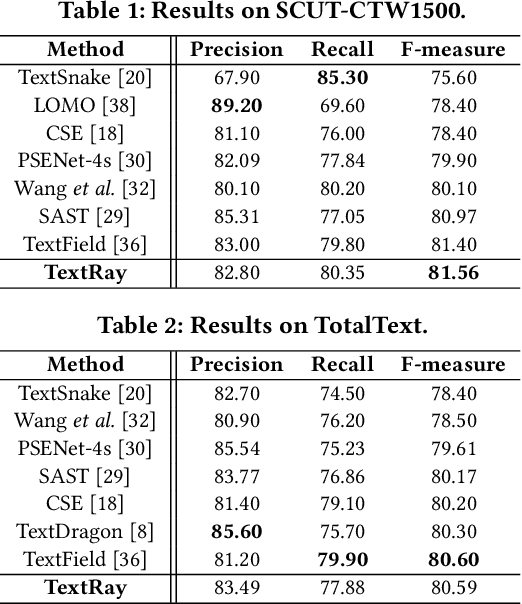
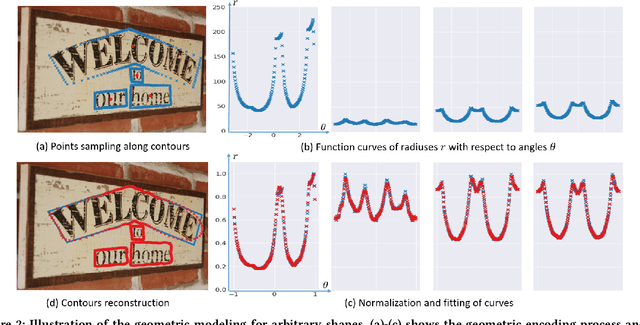
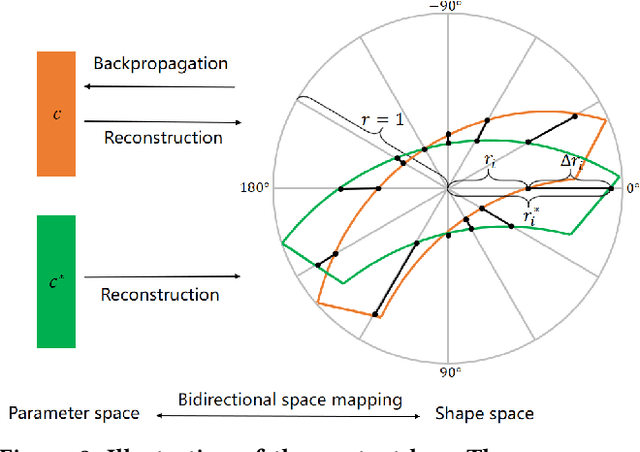
Arbitrary-shaped text detection is a challenging task due to the complex geometric layouts of texts such as large aspect ratios, various scales, random rotations and curve shapes. Most state-of-the-art methods solve this problem from bottom-up perspectives, seeking to model a text instance of complex geometric layouts with simple local units (e.g., local boxes or pixels) and generate detections with heuristic post-processings. In this work, we propose an arbitrary-shaped text detection method, namely TextRay, which conducts top-down contour-based geometric modeling and geometric parameter learning within a single-shot anchor-free framework. The geometric modeling is carried out under polar system with a bidirectional mapping scheme between shape space and parameter space, encoding complex geometric layouts into unified representations. For effective learning of the representations, we design a central-weighted training strategy and a content loss which builds propagation paths between geometric encodings and visual content. TextRay outputs simple polygon detections at one pass with only one NMS post-processing. Experiments on several benchmark datasets demonstrate the effectiveness of the proposed approach. The code is available at https://github.com/LianaWang/TextRay.
BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation
Mar 31, 2020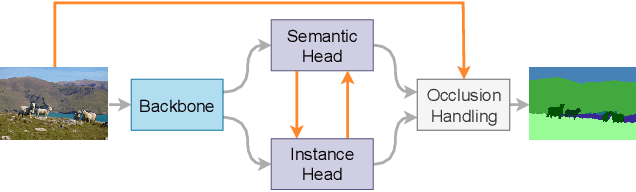
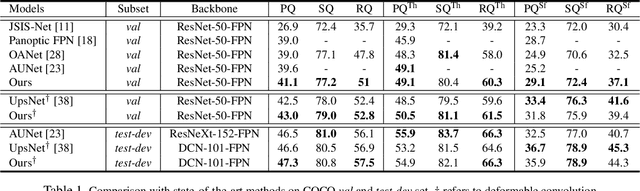
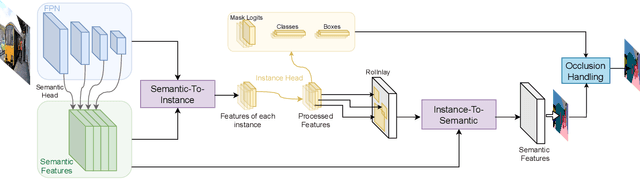

Panoptic segmentation aims to perform instance segmentation for foreground instances and semantic segmentation for background stuff simultaneously. The typical top-down pipeline concentrates on two key issues: 1) how to effectively model the intrinsic interaction between semantic segmentation and instance segmentation, and 2) how to properly handle occlusion for panoptic segmentation. Intuitively, the complementarity between semantic segmentation and instance segmentation can be leveraged to improve the performance. Besides, we notice that using detection/mask scores is insufficient for resolving the occlusion problem. Motivated by these observations, we propose a novel deep panoptic segmentation scheme based on a bidirectional learning pipeline. Moreover, we introduce a plug-and-play occlusion handling algorithm to deal with the occlusion between different object instances. The experimental results on COCO panoptic benchmark validate the effectiveness of our proposed method. Codes will be released soon at https://github.com/Mooonside/BANet.
Graph-Theoretic Spatiotemporal Context Modeling for Video Saliency Detection
Jul 25, 2017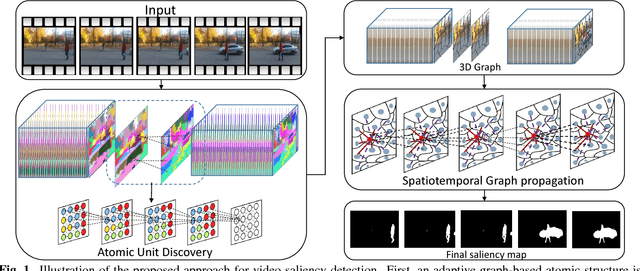
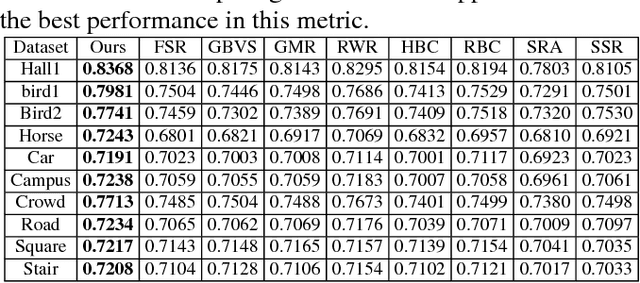
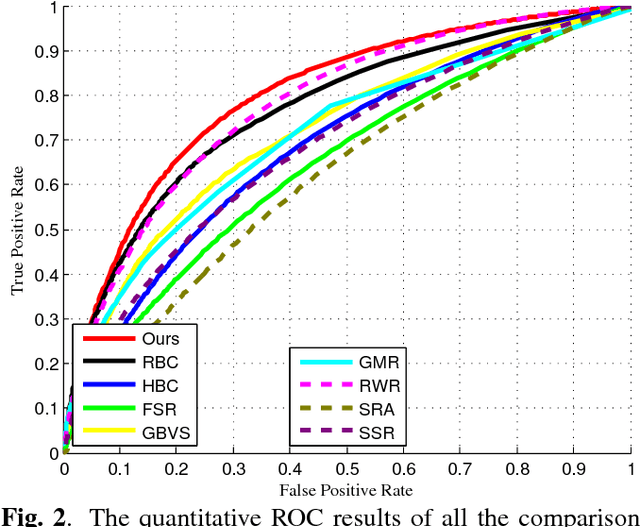
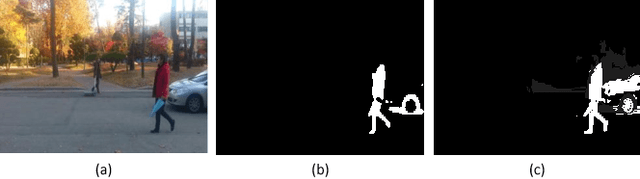
As an important and challenging problem in computer vision, video saliency detection is typically cast as a spatiotemporal context modeling problem over consecutive frames. As a result, a key issue in video saliency detection is how to effectively capture the intrinsical properties of atomic video structures as well as their associated contextual interactions along the spatial and temporal dimensions. Motivated by this observation, we propose a graph-theoretic video saliency detection approach based on adaptive video structure discovery, which is carried out within a spatiotemporal atomic graph. Through graph-based manifold propagation, the proposed approach is capable of effectively modeling the semantically contextual interactions among atomic video structures for saliency detection while preserving spatial smoothness and temporal consistency. Experiments demonstrate the effectiveness of the proposed approach over several benchmark datasets.